最近看了Gene Solutions在Journal of Translational Medicine最新发表的关于TOO文章,解读一下该文章并着重介绍一下TOO:
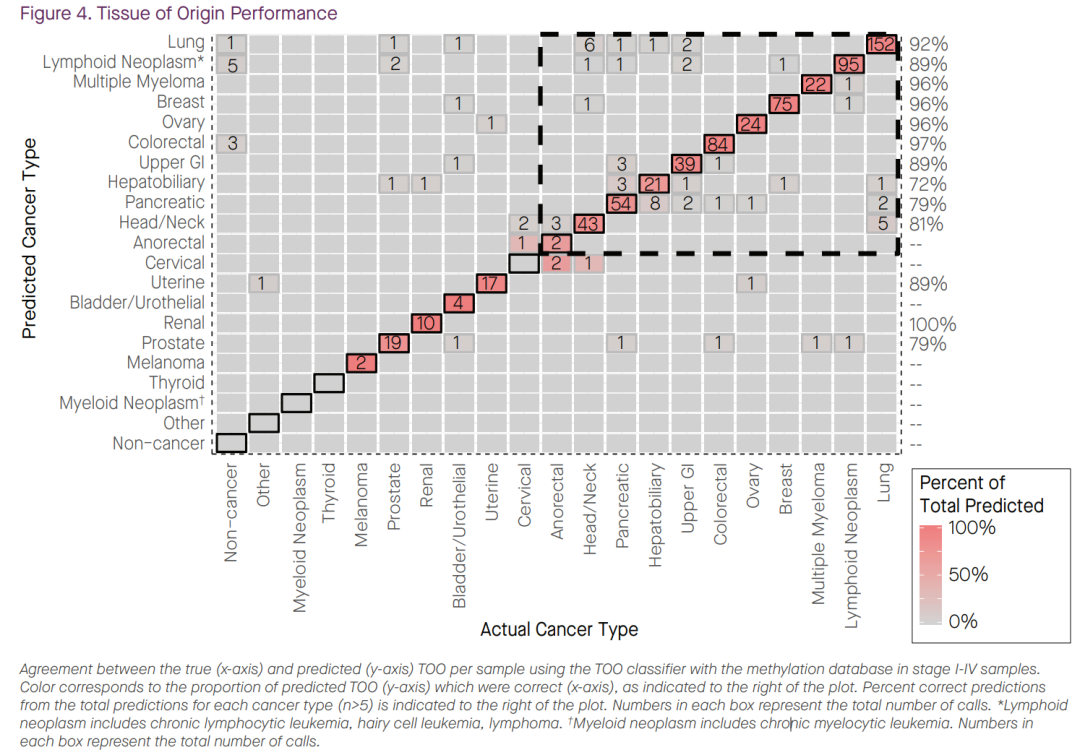
TOO全称Tissue of origin,即组织溯源,泛癌早筛第二步模型的目标(不了解泛癌早筛模型的可参考甲基化泛癌早筛—Grail是如何建模的?)。 现在市场上泛癌早筛产品开发主要基于两个路线:甲基化靶向测序(参考国内泛癌早筛产品梳理之甲基化靶向测序篇)和low-pass WGS/WGBS(参考国内泛癌早筛产品梳理之低深度全基因测序篇)。 首先看一下基于甲基化靶向测序泛癌早筛产品的组织溯源性能: Grail的泛癌早筛产品Galleri已经写过多次了,其覆盖了50多个癌种,虽然组织溯源时将有些相近部位的癌种分为了一组, 但至少也有20多个不同的部位:
按20多个不同的溯源部位来算,随机预测成功的概率不到5%,但是Galleri的组织溯源模型能将TOO准确率从随机的5%提升到90%左右。
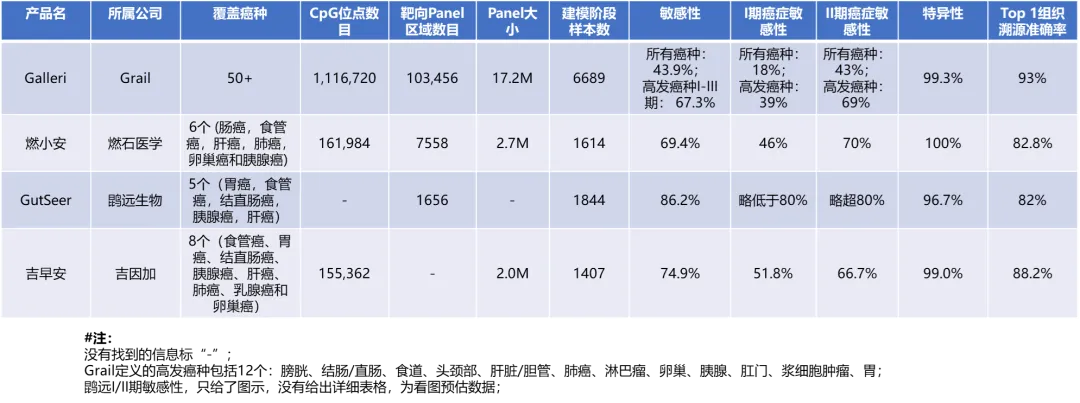
覆盖的癌种越少,随机预测的准确率越高,组织溯源难度应该越低,上表总结的国内的这三个使用相同技术路线的产品,覆盖的癌种数目远远少于Grail,TOO本该更好才对,但是即使在回顾研究的训练集样本中都难以达到Grail的水平,仍需努力。 再看一下基于low-pass WGS/WGBS 技术路线泛癌早筛产品的TOO性能: 前面已经介绍过Gene Solutions的泛癌早筛产品SPOT-MAS(越南也有泛癌早筛!!并且还不差!!),并进行了大规模的前瞻性临床验证(亚洲第一个?Gene Solutions 万人前瞻性泛癌早筛临床实验结果)。 估计Gene Solutions对比Grail 90%左右的TOO准确率,感觉原模型效果不行,然后进行了各种测试并发表了开头说的文章:
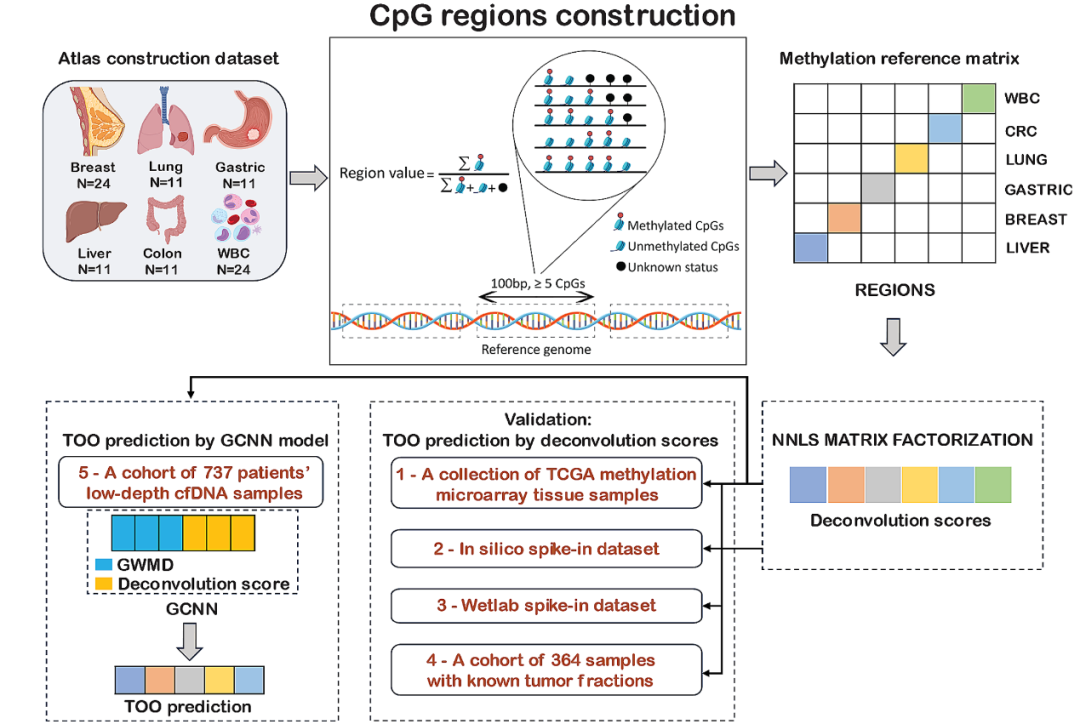
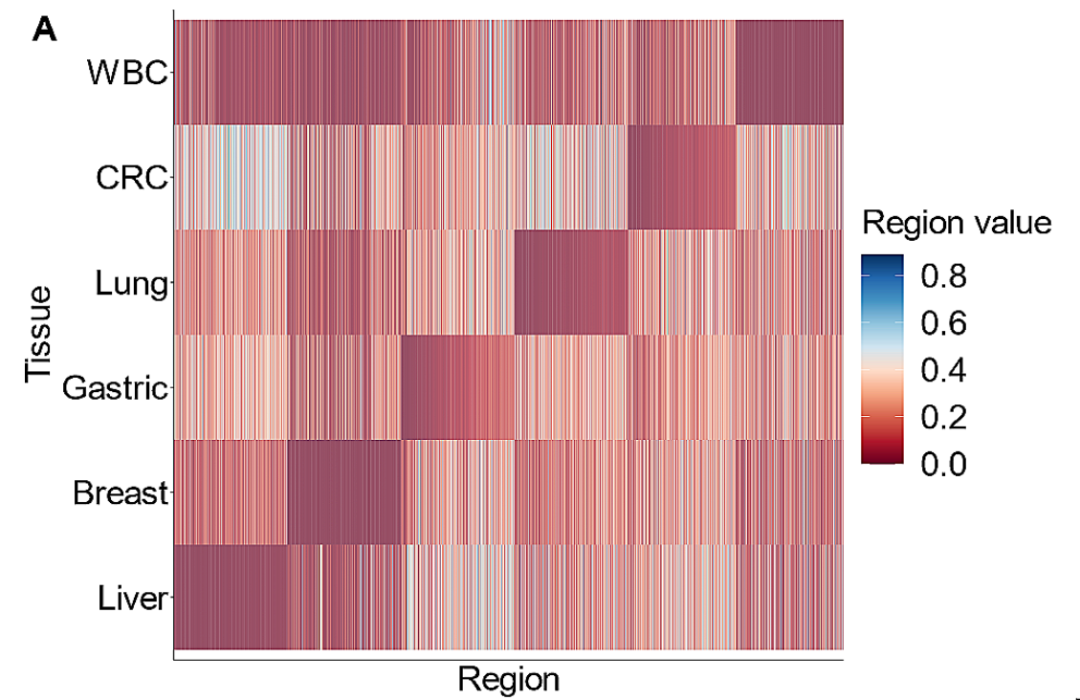
文章中Gene Solutions首先从5个癌种(越南前5大高发癌种:乳腺癌,结直肠癌,胃癌,肝癌,肺癌,另外还包括了WBC)组织WGBS数据(测序深度5-15x)中筛选甲基化区域。 一共筛选到了2945个低甲基化区域(每个组织 vs 其它组织选Top 500 markers),下面热图中明显看到这些marker在5个癌种及WBC样本中具有显著的差异:
为什么只选低甲基化区域呢? Gene Solutions参考了2023年发表在Nature上的一篇文章:
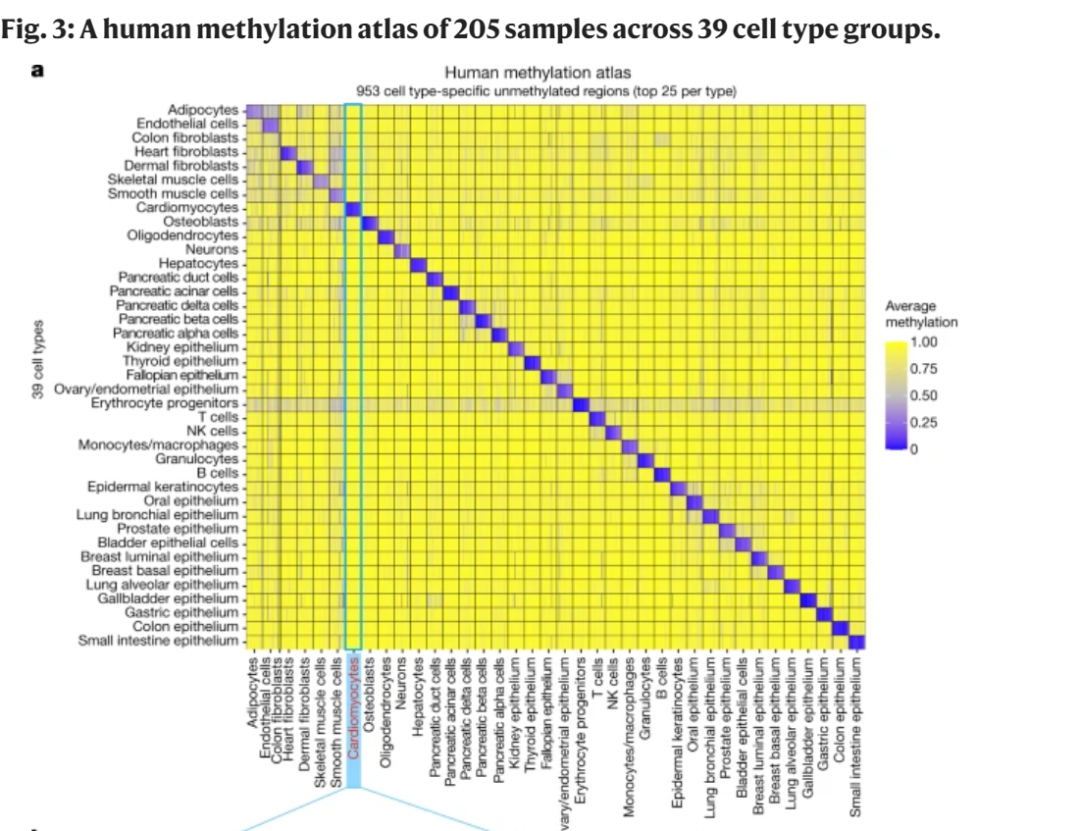
大概讲一下这篇文章:其使用来源于205个不同个体的39种不同细胞类型的WGBS数据来筛选细胞类型特异性的甲基化marker,发现最后筛选到的甲基化marker中: 细胞类型特异性的高甲基化marker富集于CpG岛区域,但是很少;细胞类型特异性的低甲基化marker富集于增强子区域,很多。
这个和前面讲过的Grail筛选的marker也是比较一致的(参考甲基化标志物筛选:Grail VS 燃石),Grail主要使用WGBS的数据进行甲基化marker筛选,最后筛选出的低甲基化CpG位点也是更多的。
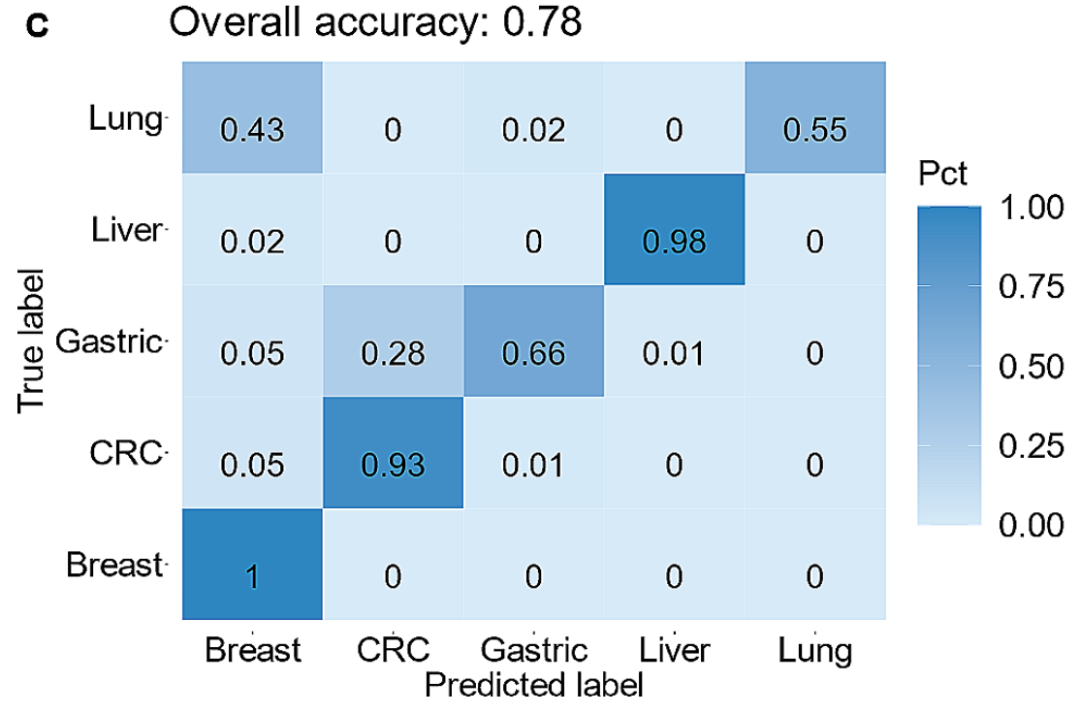
只是Grail没有把癌症鉴别的marker和组织溯源的marker的分开统计,如果分开统计的话,预估组织溯源marker中低甲基化marker占比更高。 继续,Gene Solutions筛选到2945低甲基化TOO marker后,再使用非负最小二乘矩阵分解法(简称NNLS)来确定目标样本中不同组织的占比。 NNLS怎么做的? NNLS是一种用于解决非负矩阵分解问题的方法。它的主要思想是在给定一个矩阵A和向量b的情况下寻找一个非负向量x,使得Ax与b的差异最小化。 具体到该文章: 矩阵A就是筛选出的这2945个甲基化区域在上述组织WGBS数据的甲基化水平,相当于做了一个参考矩阵; 向量b就是目标样本在这2945个甲基化区域中的甲基化水平; 非负向量x是待求的目标向量,x向量中的数值就是上述5个癌种+WBC的系数(文章中称为Deconvolution scores),即对目标样本进行了分解,可看做目标样本中5个癌种+WBC的组成比例,组织溯源结果就是最大系数所对应的癌种。 后续Gene Solutions将此方法在以下4个不同的数据集中进行了验证: 组织样本TCGA甲基化芯片(450k/850k)数据集: 2945个目标甲基化区域,只有1088个和甲基化芯片的数据有交集,基于这1088个甲基化区域,同样使用NNLS的方法。 TOO准确率可达到78%左右,达到这程度也可以了,毕竟不同的技术平台,说明筛选的这些marker在不同的数据集中都是有TOO信号的:
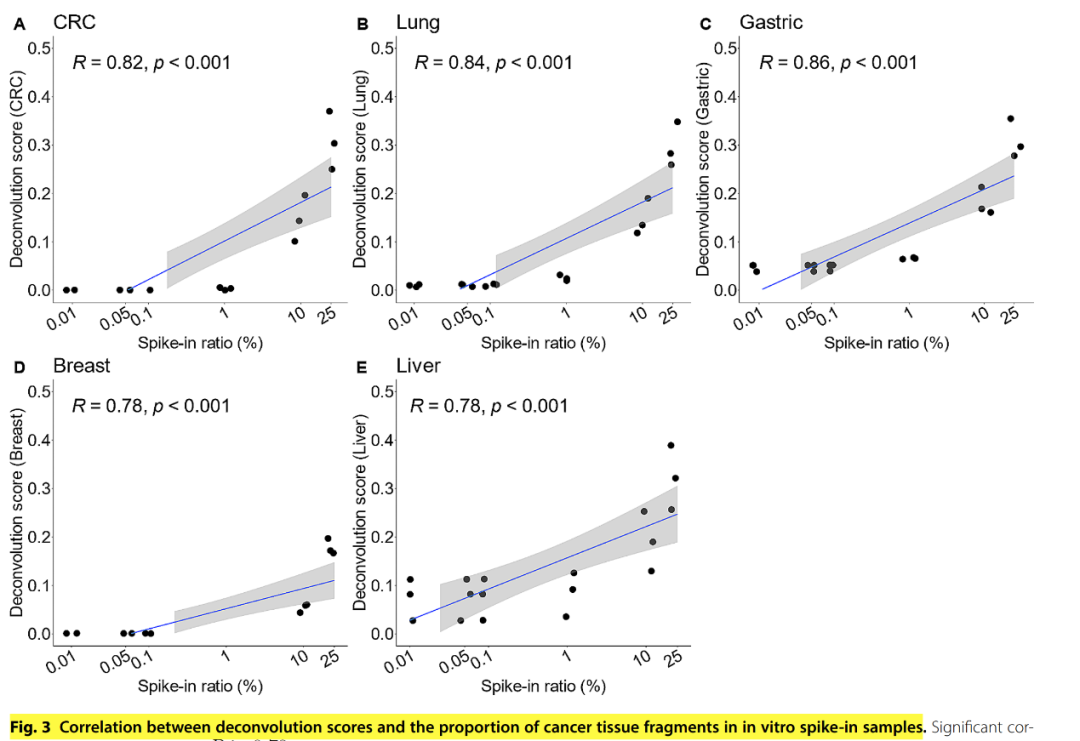
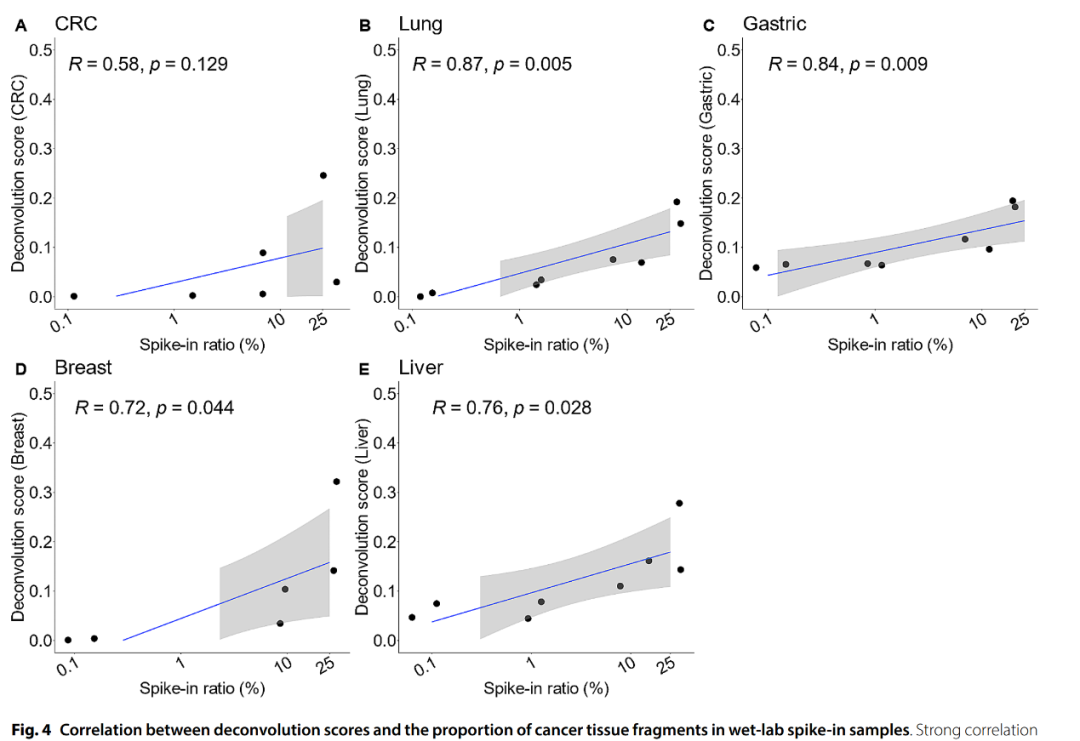
计算机和湿实验分别模拟的不同癌种不同ctDNA占比的数据:
在不同的癌种中,都是随着ctDNA占比的升高,NNLS分解的对应癌种的分值也越来越高,除了湿实验模拟的CRC,其他都显著相关,并且R值都在0.72以上,也是符合目标的。 最关键是真实临床cfDNA样本WGBS数据的验证:真正临床应用时测序深度只有0.5x。
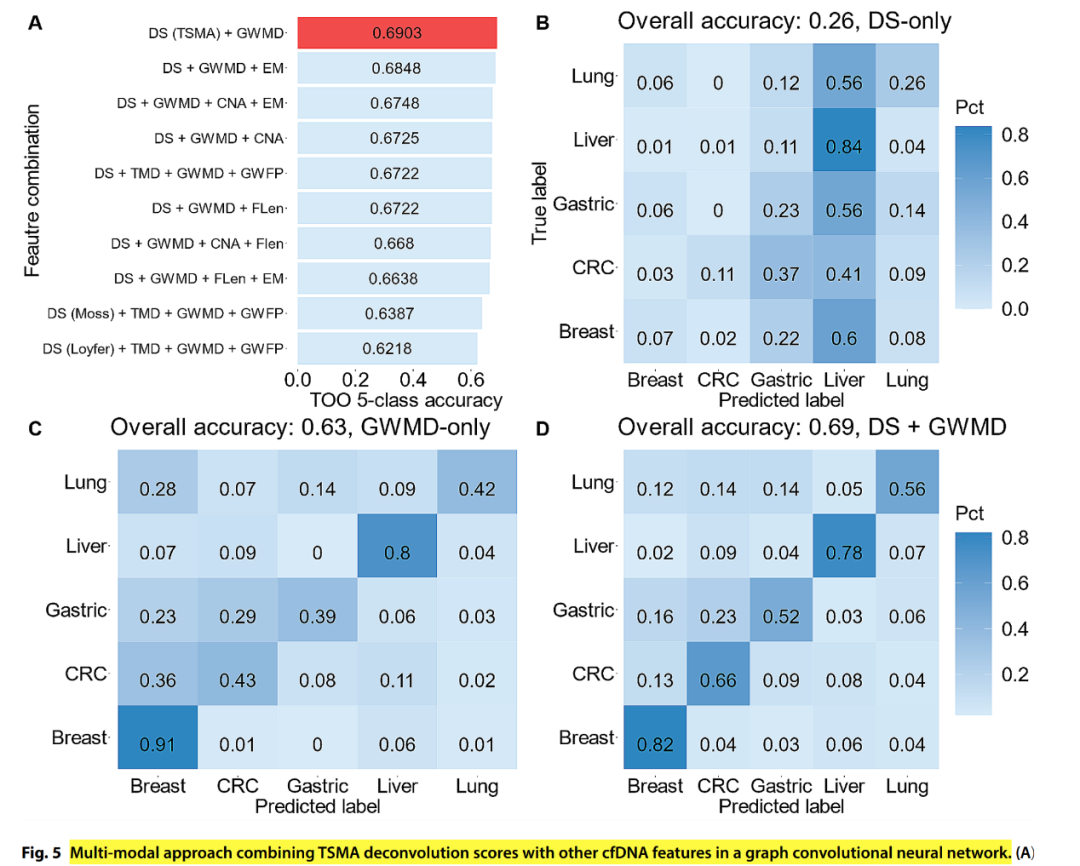
上述的方法(即上图中的DS-Only)在cfDNA样本中整体的准确率只有0.26,比随机预测的准确率(20%)就高了一点。。。说明该方法在实际的临床cfDNA样本中效果还很差,也可理解,毕竟才0.5x,区域也就不到3000个。 然后Gene Solutions遍历测试了不同特征组合模型的效果,使用的特征包括: DS(即刚才讲述的2945个区域NNLS的方法),GWMD(基因组水平甲基化水平),TMD(450个靶向甲基化区域的甲基化水平),CNA(拷贝数),EM(endmotif,片段末端基序),GWFP(基因组水平片段化特征)等等(前面说到过其中一些特征:越南也有泛癌早筛!!并且还不差!!)。 总之你能想到的几乎所有特征Gene Solutions都有纳入,并使用了深度学习GCNN(图卷积神经网络模型)模型进行整合。 Gene Solutions做的很多很全了。 最后遍历的结果是DS+GWMD的TOO准确率最高,可以达到0.69左右,最后那一堆片段组学特征竟然都没用到。。。 再综合一下现有的基于low-pass WGS和WGBS的泛癌早筛产品的两个大规模前瞻性验证的结果: Gene Solution 5个癌种组织溯源准确率只有64%(亚洲第一个?Gene Solutions 万人前瞻性泛癌早筛临床实验结果),和此次新发表文章结果差别不大。 世和基因low-pass WGS的泛癌早筛产品:13个癌种组织溯源准确率为61.5%(世和基因泛癌早筛最新结果)。 比起Grail都还差的远。。。 总结: 甲基化靶向测序的路线有Grail在前面打样,组织溯源准确率在20+部位中都能达到90%左右,国内相同路线产品虽然还达不到Grail的水平,但至少心里有底,未来还是有机会可以达到的。 但是low-pass WGS/WGBS的路线的泛癌早筛产品现在看来TOO的天花板比较低,TOO准确率堪忧。 最后也希望未来被打脸吧,毕竟多一个路,就会有更多人获益。 |

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号