仅从筛查逻辑来评价,当前的单癌早筛和多癌早筛,谁更像肿瘤标志物? PS:文末真的有彩蛋
最近多癌早筛有点火,可能因为NGS伴随诊断市场的增速实在差强人意,大家都寄希望于这个新的应用场景能成为新的“救命稻草”,相信各家公司看待这个产品的感觉都和曹操看到赵子龙七进七出差不多:
但,它真的是吗? 相信每个人都会有自己的答案,但有一个靠谱答案的前提是足够了解这个产品,足够了解这个产品当前的边界和可能的突破点。 算起来接触到这个品类也有快三年时间,有一些自己的学习和思考,和大家交流下。 围绕三个问题展开:
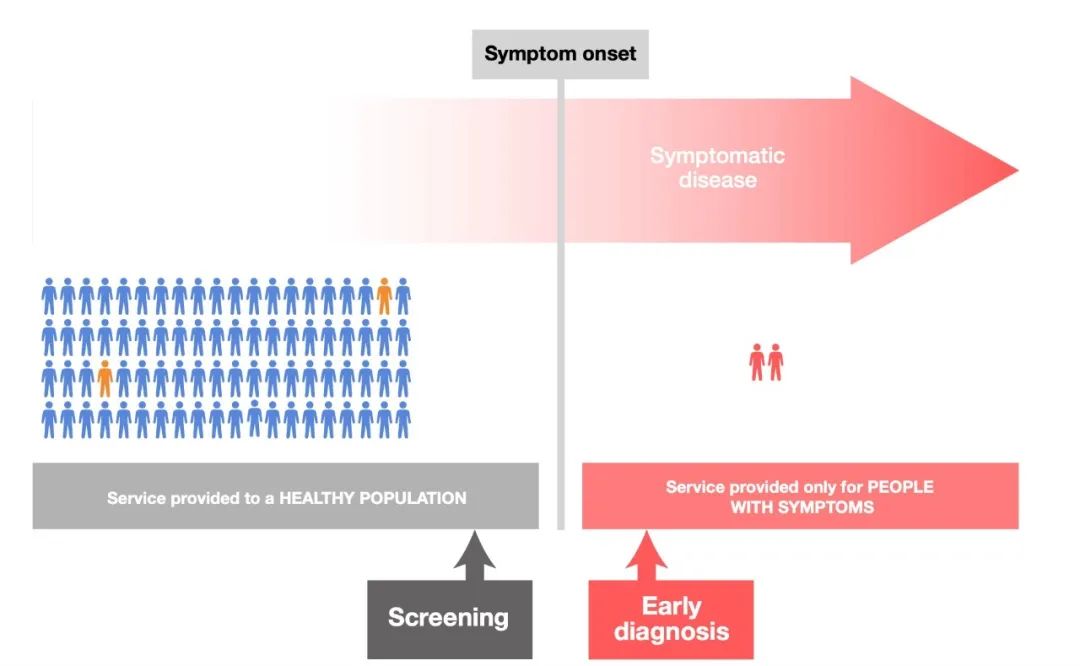
PS:本文内容仅代表个人理解,欢迎不同意见讨论。 01 多癌 vs 单癌,谁更“像”肿标 首先要说,“像”肿标并不丢人,事实上已有百年历史的肿标是个非常优秀的产品,在《你以为的小趴菜,是肿瘤早筛的百年顶流》里我详细的说过了。另外这里的“像”并不涉及性能的优劣,而是从技术底层逻辑来评价。 WHO曾经对于“早筛”和“早诊”的目标人群有过清晰的定义:癌症筛查邀请目标人群中没有症状(无症状)的人接受检测,而早期诊断是在早期阶段识别有症状的癌症。
因此所有的筛查产品事实上都在面对一个问题:如何在毫无线索的情况下,发现早期肿瘤。 有两个解题思路,随便起个名字,分别叫做“正推法”和“比较法”:
我举个可能不恰当的例子:如何判断一个陌生人是不是帅哥 正推法:看这个人是否剑眉星目、八块腹肌 比较法:看这个人像不像泰坦尼克时期的小李子
肿瘤标志物是个典型的“比较法”思维下的产品:因为在肿瘤患者中检测到了这些标志物的变化,因此认为“有同样变化的人应该得了肿瘤”。 大部分的单癌筛查则更像的“正推法”思维,比如:因为多项研究证实,Septin9基因的v2亚型启动子区CpG岛甲基化与结直肠癌的发生发展密切相关。所以认为“检测出Spetin 9甲基化的人应该得了肠癌”。(这里sun博指出,单癌筛查的起点也是比较法,只是通过比较找到了靶点再去找生物学意义,相对研究的清楚)
多癌早筛是哪个思路? 受限于基础科学的进展,目前人类对于大部分癌症的发生机制并不清晰,无法准确的给出每个癌种在演进过程中的变化细节,因此多癌早筛可以说是“不由自主/被迫”选择了“比较法”:通过对已确诊患者的检测结果构建“参考答案”,然后每次检测都类似于搜索引擎的“找相似的图”。虽然看宏观来看像突变、CNV、甲基化这些就是引起癌症原因,但对于现在动辄就测的十几万个位点,这些位点中大部分都不清楚其在癌症发生、发展中的作用。 唐代李节在《饯潭州疏言禅师诣太原求藏经诗序》所言: 抑能知其然,未知其所以然者也。吾请言之。 有了个判断,我们才能去真正理解多癌早检在当前的技术局限性。 02 为什么当前的多癌早筛都“不完美” 作为用户,我们都希望有一个完美的产品,具体到多癌筛查上,那就是100%不漏+100%不错。 WHO在一份指南中有一句对当前情况的结论性总结:没有完美的筛查产品,总有假阳性和假阴性。
多癌早筛当前的不完美是从选择“比较法”就注定了的,因为“比较”是个相对主观的事情,而“主观”就意味着会犯错。 以目前主流的cfDNA甲基化多癌筛查为例,可以列举几个会干扰“比较”从而带来“假阳性”的因素:
比如衰老,有一位前辈跟我说过一句话:衰老的尽头是肿瘤。随着细胞分裂次数的累积,特定区域甲基化会出现选择性丢失,而这种变化和肿瘤还真挺像的,感兴趣的可以去看看这两篇文献。
PS:也许换个思路,直接包装成“器官衰老程度检测”是不是个很棒的产品
比如炎症,通常器官发生癌变,免疫细胞都会被激活、并且聚集到癌变部位周围,所以也会伴随炎症的发生。因此从已确诊患者的样本特征中构建的“画像”可能免不了带了些炎症的特征。遇到下一个“炎症”样本时,就有可能错判为“相似”。
比如器官损伤,导至该器官来源的cfDNA异常的高。这就好比有一个人眼睛极其的漂亮,极其的符合“历史上所有帅哥眼睛的样子”,但其他都很普通。这个人是不是帅哥可能就不那么好判断。 而“假阴性”的因素在不考虑技术失误(比如没测准)的情况下最大的原因是三个字: “没见过” 当前不管哪家公司的算法模型,不管有没有号称使用AI技术,本质上都只能做到对输入信息的结构化和归纳总结,暂时不具备“学习后进化和推理的能力”。通俗的说,它没办法自己去悟到没有被教过的东西(这和ChatGPT这样的生成式AI有着代际差)。而癌症是个很多样化的疾病,受限于构建“画像”时的样本通常有限,很难做到覆盖每个亚型,一旦遇到没见过的癌症类型,基本就是无法检出。就像如果用早期小李子的画像去评价晚期小李子,大概得不出帅哥的结论。
所以事实上就是,当前所有的多癌检测产品,都无法完全规避假阳性和假阴性的问题。 这个分析也可以帮助我们更好的去理解现在市面上的产品形态,因为当前逻辑下要解决“假阴性”和“假阳性”的核心都是不断扩大模型的学习素材,考虑到存在该情况的人群基数,相比之下后者比前者的学习素材更容易“获取”,因此我们会发现现在的多癌早筛产品特异性往往表现比敏感性更好。 因此反向结论也成立,在同样的技术水平下,如果一个多癌早筛产品连特异性的问题都解决不好,是不太可能相信其有很好的解决敏感性的能力的。 另外,这种不完美也在当前可以成为“照妖镜”,一个好的多癌筛查产品在当前一定是会有清晰的“适用人群”和“不适用人群”,如若没有,两种可能:没说实话 or 临床验证做的不扎实。 无论是哪种,都说明这产品不仅不完美,还不可信。
不过这里忽略了主观策略选择的因素,有的时候有意选择“高特异性”是因为选择“让拿到错误结果的用户总数最少”,从而使用了更严格的“比较”策略,放掉了一些本可检出的用户去换取更低的假阳性率。而有意选择“高敏感性”则是因为选择“让可能被严重伤害的用户总数最少”。 小插曲1: 为什么作为“比较法”下师出同门的兄弟,当前不管是甲基化还是多组学的多癌早筛,能够在性能上强过肿瘤标志物那么多。比如ESMO上的PROMISE研究。
因为“大力出奇迹”,当用于比较的维度大到一定数量级时,就可以通过“训练”让这个“比较”更聪明,通常大家管这叫“算法”。而肿瘤标志物时无法被“训练”的,其可调整的空间仅仅只有单一数值的cutoff值。玩手办的朋友们应该更有体会,一个手办可动关节越多,其更能逼真的复原动画场景。
03 多癌早筛如何走向“完美” 这个问题要拆分成两个:“当前能做的” 和 “未来可以希冀的”。 当前能做的事情不多,都是“结硬寨、打呆仗”,没有捷径,一份付出换一分提升
这个比拼的是临床试验的开展能力,为什么大家这么眼馋Grail,既因为他是大曼曼的亲儿子所以测序成本低,更因为其有钱开展了茫茫多的临床试验,这让其构建画像时的样本丰富程度可以显著拉开与其他竞争者的差距。
人的血液中大量的来自于正常细胞的cfDNA,从中去找到肿瘤来源的确实类似于类似“稻草堆里面找针”,通常用于评价测序质量的指标是Q30/Q40(碱基读取的准确性达到99.9%/99.99%),某不愿意透露姓名的ELEMENT的朋友说Q40的降噪肯定有作用的,且说element大部分数据在Q40-45,大部分数据错误可能性是现有某主流测序仪的1/10。(此处我不发表任何意见,大家自行判断是否可信)
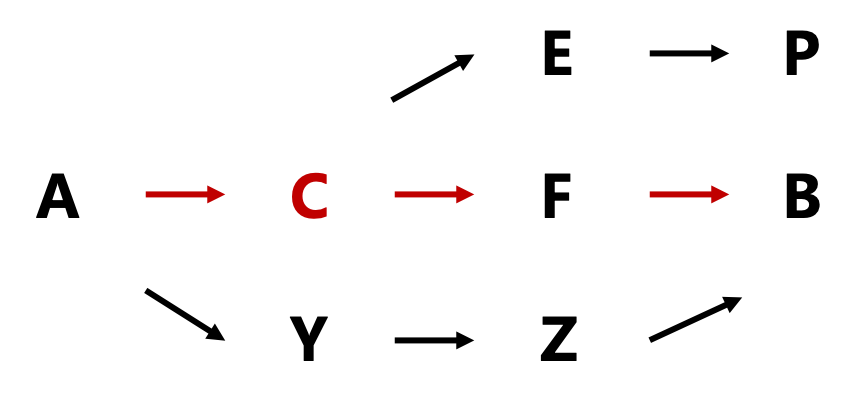
我很喜欢一句话,“错误本身不是末日,无法被消除的恐惧才是”。在当前这个阶段的多癌筛查,相比于“单打独斗”,更适合“一个好汉三个帮”,一方面在前端应用可以考虑联合其他检测来实现降低漏检率上的互补,另一方面则需要联合医生给到阳性检出一个合适的“诊断路径和诊断终点”来帮助“假阳性”及时止损。 那么,未来呢? 前面说到,多癌早筛的不完美是从选择“比较法”就注定了的,而未来的希望则在于底层逻辑的变化:从“比较法”变成“正推法”, 从甲基化/组学检测的结果,正向模拟细胞变化,推断癌症是否已经发生。很多问题就迎刃而解了 要实现这一点,依赖于基础科学研究的突破性进展,如果放到过去,这可能真的要花费数十年的时间,但AI的进步可能极大的缩短这个时间,比如类似于alphafold2能够帮助结构生物学家更快速的预测蛋白质结构一样,如果AI能够以极高的准确度推演出所有癌症的发生、发展过程,这对于多癌早筛的影响是革命性的,也给“完美”提供了可能性。 我相信这一天不会太远了,这也是我心中认为AI能够对肿瘤早筛产生最大影响的地方。 小插曲2: 肯定有朋友会说,用“正推法”做出来的单癌筛查产品性能也就那样啊。那是因为虽然底层逻辑是正推,但如sun博所言,这是“比较法”后找补的“正推法”,仅解释了当前靶点在肿瘤发生、发展中的机制,缺乏全貌。我举个例子就明白了: 就像有三条路,分别是A-C-F-B、A-C-E-P和A-Y-Z-B,现在我们的认知大概是A-C-?-B。基于这个认知,我们认为如果看到一个人经过了C就判断其一定会到B,显然既会漏也会错。
04 结尾 今天的总结很简单,以下都是重点,就不画重点了
作为一个“比较法”逻辑下的产品,当前的多癌早筛产品注定是不完美的,假阳性和假阴性无法避免。 如果要在“不完美”中判断谁做的差一点,有两个可参考的标准:
虽然无法解决“不完美”,但当前还是有些事情可以去优化的,不断做临床试验搜集样本和找伙伴。 彻底解决“不完美”需要对现有多癌早检产品的底层构建逻辑做一个大的替换,从“比较法”变成“正推法”,在类似于AlphaFold的AI加持下,一切可期。 我个人依然长期看好多癌早筛,我感觉至少大曼曼也是这么想的
今天的彩蛋是个“广告” 每次都很有耐心怼我指导我的前辈姐姐上综艺了!! 果然要足够瘦才能上镜刚刚好啊! |

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号