只需一步,快速开始
微信扫一扫,快速登录
您需要 登录 才可以下载或查看,没有账号?立即注册
举报
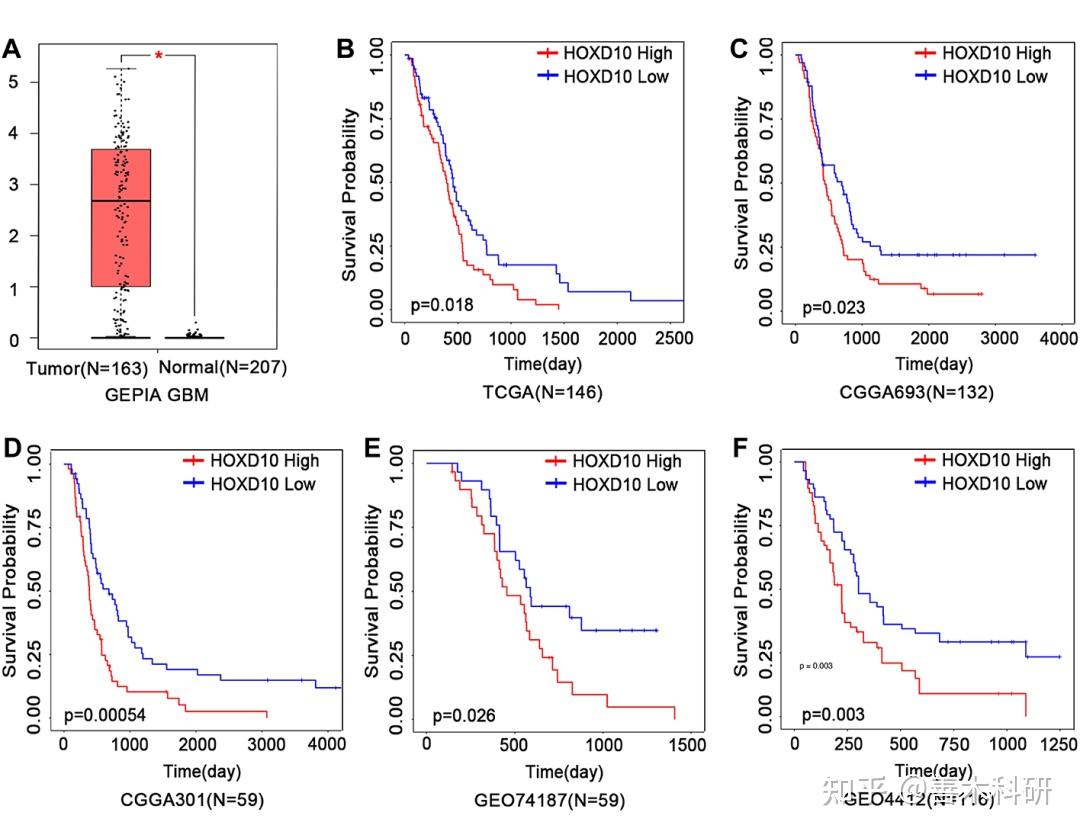
上图是国内学者2021年发表于期刊OncoTargets and Therapy的生信相关文献。 题名:Identification of HOXD10 as a Marker of Poor Prognosis in Glioblastoma Multiforme (HOXD10为多形性胶质母细胞瘤预后不良的标志物) 需要注意的是,在开始具体分析之前,此论文作者已通过前期筛选,得到了一个与母细胞瘤疾病发展相关的关键分子(HOXD10),即已完成了生信分析的第一步:挑分子。
随后作者利用不同来源(TCGA、CGGA、GEO)的数据,通过生存分析证明了HOXD10表达水平影响患者的生存时间。 该部分通过表达分析和预后分析,阐明了HOXD10与肿瘤的发生发展相关。 作者首先证明,研究的分子具有临床意义,是具有解决临床问题的潜在价值的,值得后续做更深层次的研究。 这部分,实现了“靠临床”。
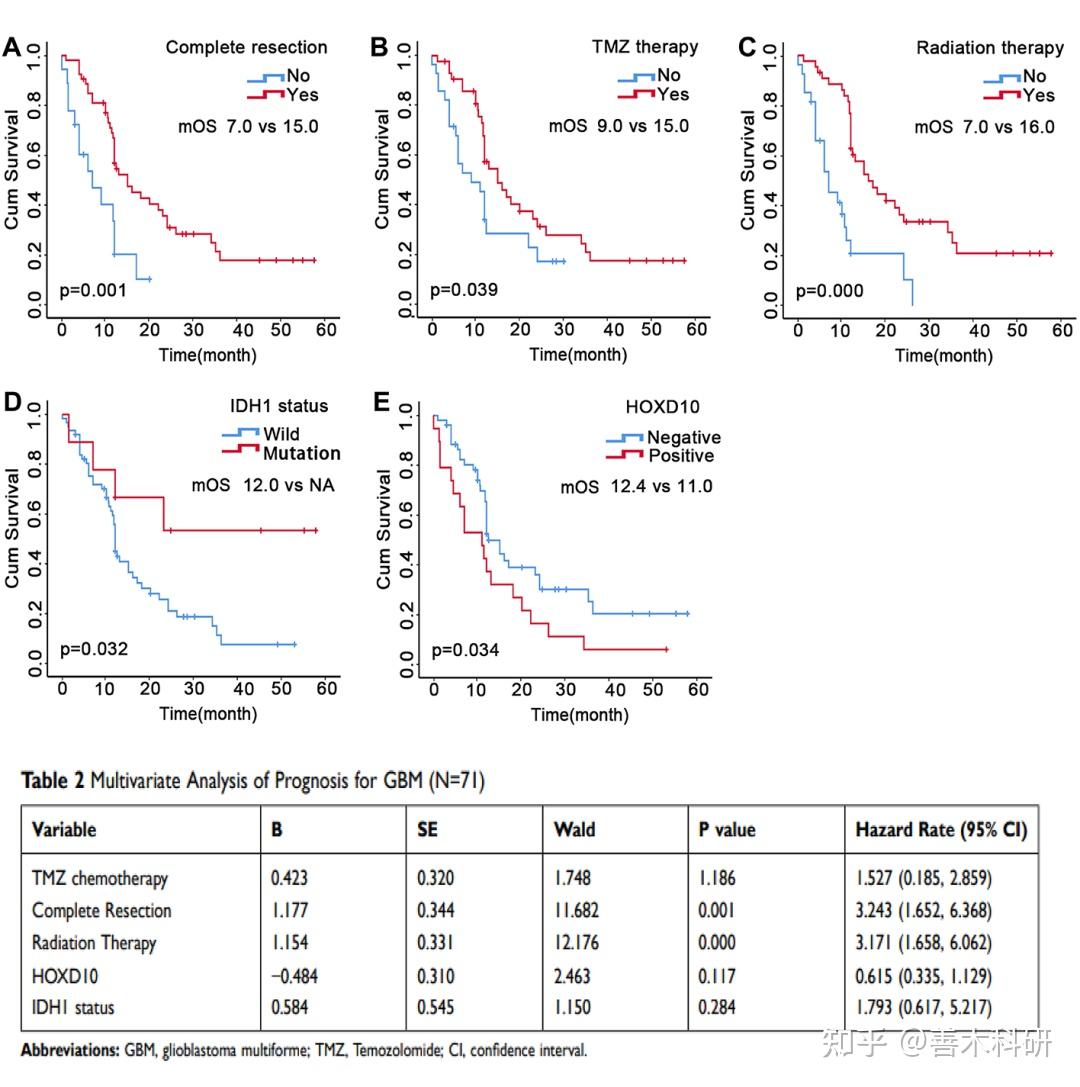
随后作者又通过单因素COX回归分析,探索了不同临床特征下(是否全切除、是否TMZ治疗、是否放疗、IDH1状态、HOXD10状态),HOXD10对预后的影响(A-E)。 又通过多因素COX回归分析,探索了影响患者生存的独立预后因子(表2)。 此部分,作者仍然是做“靠临床”的分析。
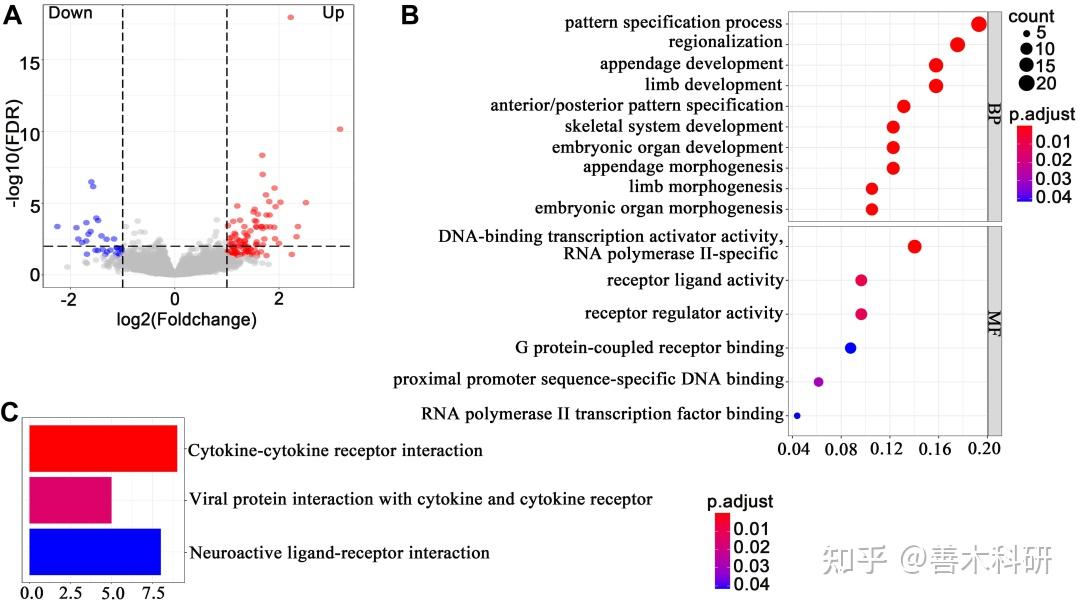
作者先筛选出母细胞瘤中与HOXD10表达模式相似的一群差异基因(A)。 随后通过富集分析探索了这群基因可能参与的生物学过程、发挥的分子功能(B),及其涉及的信号通路(C)。 可以看到,这群基因主要与细胞因子-细胞因子受体相互作用通路相关。 该部分,作者进行了“圈功能”的分析。
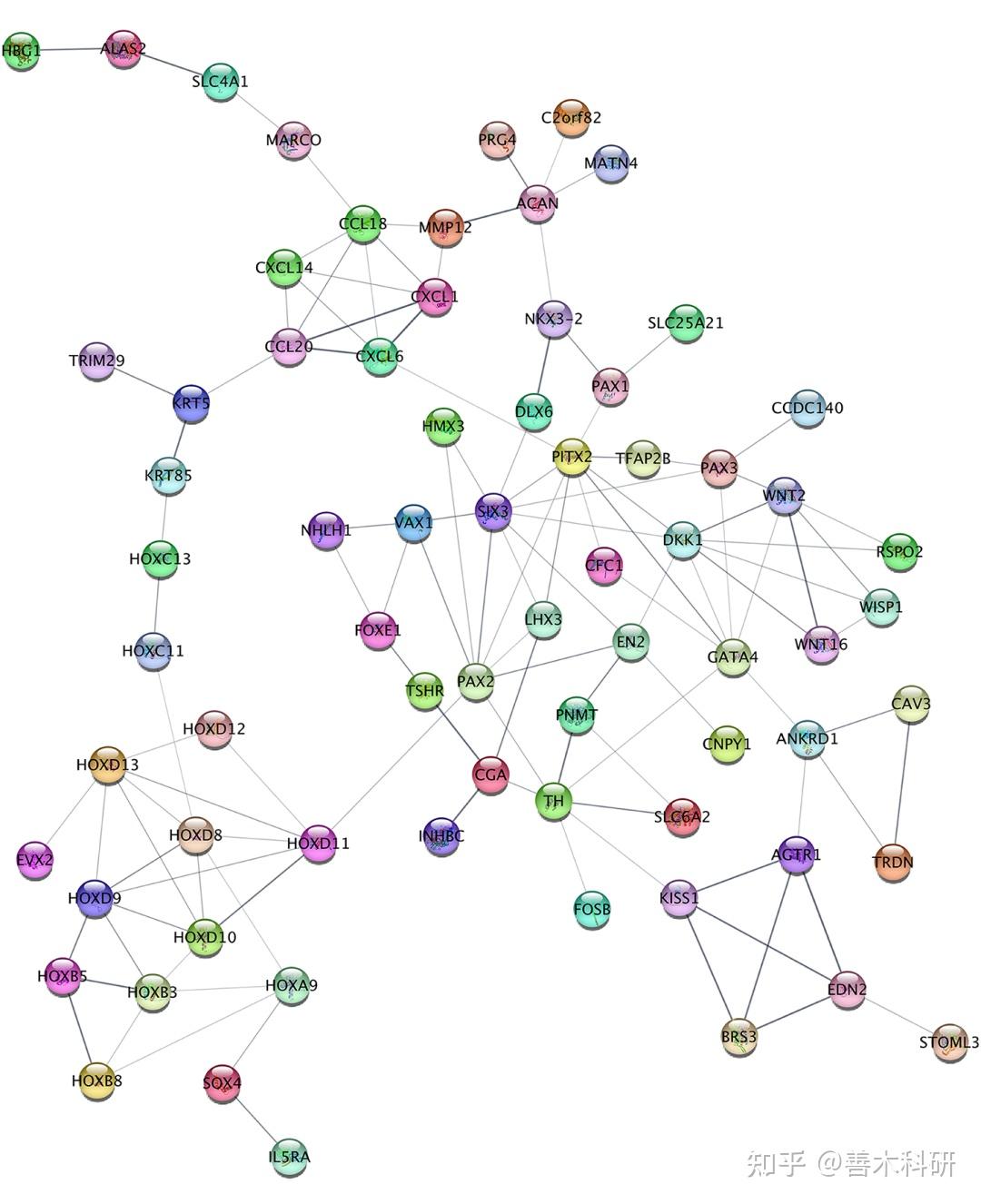
最后,作者通过蛋白-蛋白互作(PPI)网络,呈现了这群分子之间的相互作用形式。 该部分,作者进行了“联关系”的分析。
本版积分规则 发表回复 回帖后跳转到最后一页
查看 »
微信扫一扫关注本站公众号

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-5-10 15:40
发表于 2025-5-10 15:40