金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
F检验是被誉为现代统计学之父的R.A. Fisher爵士提出、由George W. Snedecor命名的统计检验方法,主要用于方差齐性检验、方差分析等等。
本文介绍F检验的如下应用:
- 方差齐性检验(F-test of equality of variances)
- 方差分析(Analysis of Variance, ANOVA)
- 线性回归方程整体的显著性检验
其中第二条方差分析分很多种类,根据因素的多少可分为单因素方差分析和多因素方差分析;根据试验设计可分为完全随机设计和随机区组设计等;根据交互项又可分为无交互项的方差分析和有交互项的方差分析等;又有完全随机设计、随机区组设计、拉丁方设计、析因设计、正交设计、平衡不完全区组设计等等很多可能相互重叠但概念又不尽相同的类型。本文在方差分析这一点只介绍最简单的一种——完全随机设计的单因素方差分析,其他类型的方差分析,除了可能涉及到如何科学地进行试验设计的知识,方差分析的基本思想都是相同的。其他类型的方差分析具体见参考文献[1],有关试验设计(Design of Experiment, DOE)的知识见参考文献[2]。或者看我翻译的书混乱数据分析:设计的实验
1.方差齐性检验
目的:方差齐性是方差分析和一些均数比较t检验的重要前提,利用F检验进行方差齐性检验是最原始的,但对数据要求比较高。
要求:样本来自两个独立的、服从正态分布的总体。
检验原理
记两独立总体为:
X_1\sim N(\mu_1,\sigma_1^2),\quad X_2\sim N(\mu_2,\sigma_2^2) 从两总体中抽取的样本为:
X_{1i}(i=1,2,\cdots,n_1),\quad X_{2j}(j=1,2,\cdots,n_2) 定义样本均值和样本方差:
\bar X_1=\frac{1}{n_1}\sum_{i=1}^{n_1}X_{i1},\quad s_1^2=\frac{1}{n_1-1}\sum_{i=1}^{n_1}(X_{i1}-\bar X_1)^2
\bar X_2=\frac{1}{n_2}\sum_{i=1}^{n_2}X_{i2},\quad s_2^2=\frac{1}{n_2-1}\sum_{i=1}^{n_2}(X_{i2}-\bar X_2)^2 方差齐性双侧检验的原假设和备择假设:
H_0:\sigma_1^2=\sigma_2^2,即两总体方差相等
H_1:\sigma_1^2\neq\sigma_2^2,即两总体方差不等 由F分布的构造定义:
\frac{s_1^2/\sigma_1^2}{s_2^2/\sigma_2^2}\sim F(n_1-1,n_2-1)
其中n_1-1、n_2-1分别为分子自由度和分母自由度。
在H_0成立的条件下,即\sigma_1^2=\sigma_2^2成立的条件下:
\frac{s_1^2}{s_2^2}\sim F(n_1-1,n_2-1)
一般约定取较大的方差作为分子,较小的方差作为分母,这样计算出来的F>1,缩小了范围,便于查表做出结论。给定显著性水平\alpha,利用样本数据计算统计量F_1=\frac{s_1^2}{s_2^2},若F_1>F_{\alpha,(n_1-1,n_2-1)},这在一次抽样中几乎是不可能发生的(其发生的可能性为p值)此时拒绝原假设,认为方差不齐,否则就不拒绝原假设(即认为方差齐)。
对于单侧检验:
H_0:\sigma_1^2<\sigma_2^2
H_1:\sigma_1^2\geq\sigma_2^2 若利用样本计算出来的统计量\frac{s_1^2}{s_2^2}=F_2>F_{\alpha,(n_1-1,n_2-1)},则拒绝原假设,否则不拒绝原假设。
对于单侧检验:
H_0:\sigma_2^2<\sigma_1^2
H_1:\sigma_2^2 \geq \sigma_1^2 若\frac{s_1^2}{s_2^2}=F3<{F_{1-\alpha,(n_1-1,n_2-1)}},则拒绝原假设,否则不拒绝原假设。
2.完全随机设计的单因素方差分析(completely randomized design one-way ANOVA)
假设我们要研究一个因素对于一个指标的影响,试图比较这个因素内各个取值水平对于这个指标的影响是否相同。譬如我们要研究饲料对于鸡的增重的影响,这里面饲料就是一个因素,相同时间内鸡的增重就是研究的指标,饲料可能有很多种配方,不同的配方就代表饲料这个因素的不同的水平,我们对于每个水平做试验(每个水平的试验次数可以不同),可以得到如下的结果(数据是编造的):
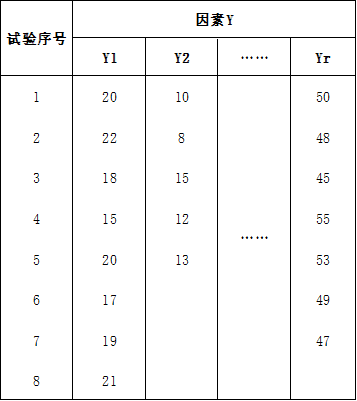
其中共有r个水平,每个水平的试验次数不一定相同,从这些数据显然可以看出Yr的均值最大,且Y1比Y2大。但这只是我们直观上的判断,要给出科学依据就要用到方差分析(Analysis of Variance, ANOVA),这里只考虑了一个因素Y,所以是单因素方差分析,这是最简单的方差分析。所有的方差分析研究的都是因子的不同水平是否有差异,这个差异就是看同一因子的各个水平下的指标的均值的差异是否显著。但我们不能想当然地直接将各个水平的指标平均、比较然后得到结论,这样又是刚才说的直观的判断。因为也许客观来说真的是直观上的结论,但抽样是有误差的,如何证明各个水平的差异不是由抽样的误差造成的呢?譬如上面这个例子中,假如,假如,假如各个水平的影响是相同的(H_0),由于抽样误差导致这么大的差异,在一次抽样中是小概率事件,极有可能让我们怀疑原假设。从这个意义上说,如何度量“抽样得到的各个水平的差异'更多地'是来自各个水平自身的差异,'较少地'来自抽样误差便成了这个假设检验问题的关键(关于这个问题更多的探讨,对方差分析(ANOVA)的直观解释及计算给出了三种情形,图文并茂很好理解),Fisher爵士可能就是这样自然地想到了利用这两种差异的比值构造F统计量:
F=\frac{SSA/df1}{SSE/df2} 其中SSA是各个水平之间的偏差平方和,也可以说成是组间平方和(Sum of Square Between Groups),SSE是各个水平内部的偏差平方和,可以说成是组内偏差平方和,可以理解为上面说的误差的平方和(Sum of Square Error),df1、df2分别是它们的自由度。那就有疑问了,为什么不直接把\frac{SSA}{SSE}作为判断依据呢,而是要各自除以一个“难以理解”的自由度?这是因为SSA、SSE都只是偏差的平方和,倘若这两个计算的数量不一样,譬如SSA计算了十个偏差的平方和,而SSE只计算了五个,那么\frac{SSA}{SSE}就会又因为组间、组内这些数量而无法度量。除以自由度得到的就是方差,从而保证了这两个偏差的平方和在平均意义下是可比的,由此引出组间方差和组内方差的概念:
组间方差(组间变异):\frac{SSA}{df1},又可以称为由因素自身产生的变异
组内方差(组内变异):\frac{SSE}{df2},又可以称为由误差产生的变异,又称为均方误差(Mean Square Error, MSE)
上面从直观上给出了定性的描述,下面从数学角度给出定量地分析,不过随之而来的是一群张牙舞爪的符号和晦涩难懂的推导。
以i表示因素Y的不同的水平/组别,共有r个水平/组别;j表示不同的试验,一般情况下,不同组别的试验数不同,y_{ij}表示在第i个组下第j次试验得到的指标。譬如在开头的例子中,y_{24}=12表示在第2种饲料配方(第2组)下第4次试验得到的指标(鸡的增重)为12。
接着我们给出方差分析的基本假定:每一水平的总体服从均值为0的正态分布且各总体方差相等,即:
y_{ij}\sim N(\mu_i,\sigma^2)\quad i=1,2,\cdots,r,且y_{ij}相互独立。 我们取各个总体的均值:\mu_1,\mu_2,\cdots,\mu_r,现在做出假设:
H_0:\mu_1=\mu_2=\cdots=\mu_n
H_1:\mu_1,\mu_2,\cdots,\mu_r不全相等 注意,这里的\mu_i是总体的均值,是客观存在的固定的常数,但我们未知,我们就是要利用方差分析来判断它们在统计学意义上是否相等。若H_0成立,则我们认为因素A的各个水平的差别是不显著的,我们称因素A不显著。若拒绝了H_0,则我们认为A中至少有两个水平从差别是显著的,我们称因素A显著。提出了原假设和备择假设,下面就是漫长的推理过程了。
这里我们仅证明各个水平试验次数相同的情况,各个水平试验不同的情况见参考文献[2]。设每个水平i(i=1,2\cdots,r)进行了m次试验,则总试验次数n=mr。每个水平i(i=1,2\cdots,r)下试验得到的数据y_{ij}(j=1,2,\cdots,m)与该水平总体的均值\mu_i是有差异的,我们记这个差异为:
\varepsilon_{ij}=y_{ij}-\mu_i\sim N(0,\sigma^2)\quad (1) 可以推出:
y_{ij}=\mu_i+\varepsilon_{ij}\quad (2) 接着我们定义总体的总均值:
\begin{aligned}\mu=\frac{1}{r}\sum_{i=1}^r\mu_i\end{aligned}\quad (3) 定义因素A第i水平的主效应=第i个水平的总体均值与总均值的差(主效应的概念在试验设计中很重要):
a_i=\mu_i-\mu \quad (4) 以\begin{aligned}\overline{y_{i\boldsymbol ·}}=\frac{1}{m}\sum_{j=1}^{m_i}y_{ij}\end{aligned}表示第i个水平的样本均值,定义第i个水平的样本均值与总体均值的差:
\overline {\varepsilon_{i\boldsymbol·}}=\overline{y_{i\boldsymbol·}}-\mu_i \quad(5) 由此推出:
\overline{y_{i\boldsymbol·}}=\mu_i+\overline {\varepsilon_{i\boldsymbol·}}\quad(7) 定义样本的总均值:
\begin{aligned}\bar y=\frac{1}{n}\sum_{i=1}^{r}\sum_{j=1}^{m}y_{ij}\end{aligned} \quad(8) 样本的总均值和总体的总均值的差:
\bar \varepsilon=\bar y-\mu\quad(9) 由此推出:
\bar y=\mu+\bar \epsilon\quad(10) 疯狂定义了这么多,让我们画张图来梳理一下,为了简洁,我只画出两个水平,以黑色图形代表可以从样本中获取的、已知的;红色图形代表与总体有关的、未知的。
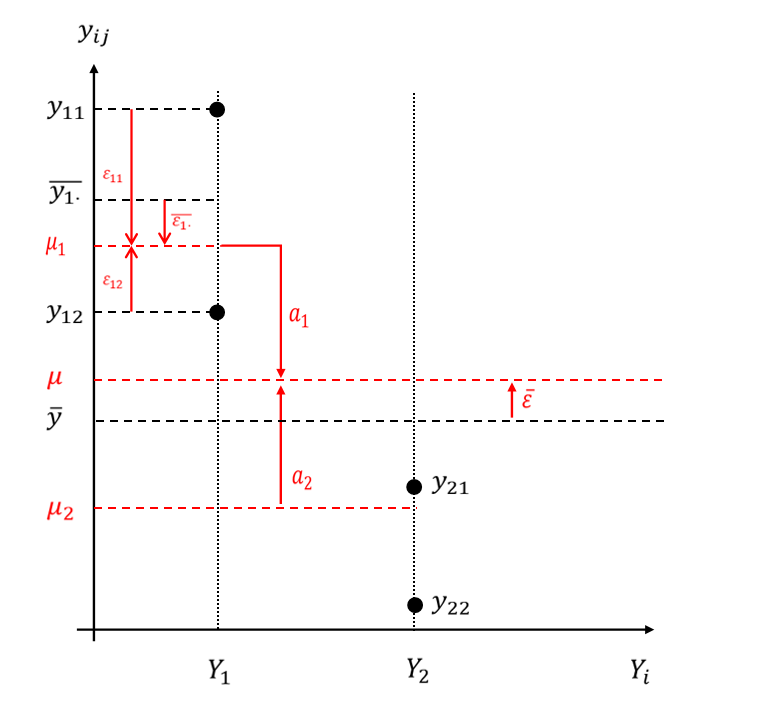
希望没有把大家绕晕,如果有,不妨再把这些符号写一遍:
- \mu_i是第i个水平的总体均值
- \overline{y_{i\boldsymbol ·}}是第i个水平的样本均值
- \varepsilon_{ij}是第i个水平第i个试验的值与该水平总体均值的差,反应了第i个水平内部各个试验的误差
- \overline {\varepsilon_{i\boldsymbol·}}是第i个水平的样本均值与总体均值的差,反应了第i个水平内部 试验的平均误差
- a_i是第i个水平的总体均值与总均值的差,称为主效应,反应了第i个水平平均而言对指标的作用
- \bar \varepsilon是样本的总均值和总体的总均值的差,反应了样本与总体之间平均而言的误差
现定义三种偏差/变异,它们都是偏差平方和的概念,而不是方差的概念:
- 总偏差平方和(Sum of Square Total, SST)
\begin{aligned}SST=\sum_{i=1}^{r}\sum_{j=1}^{m}(y_{ij}-\bar y)^2\end{aligned}
在一共n次试验中,\bar y确定后,n次试验只有n-1次是可自由变动的,故SST的自由度为n-1。
- 组内偏差平方和,或称为误差偏差平凡和(Sum of Square Error, SSE)
\begin{aligned}SSE=\sum_{i=1}^{r}\sum_{j=1}^{m}(y_{ij}-\overline{y_{i\boldsymbol ·}})^2\end{aligned}
在一共n次试验中,分为r组,每组内的均值确定后,每组就少了一个可自由变动的试验,共r组,故一共少了r个可自由变动的试验,故SSE的自由度为n-r
- 组间偏差平方和(Sum of Square Between Groups)
\begin{aligned}SSA&=\sum_{i=1}^{r}\sum_{j=1}^{m}(\overline {y_{i\boldsymbol ·}}-\bar y)^2\\&=\sum_{i=1}^{r}m(\overline {y_{i\boldsymbol ·}}-\bar y)^2\end{aligned}
一共r组,试验确定后,只有r-1个可自由变动,故SSA的自由度为r-1
定义完后,我们回过头看,这三个偏差平方和是分别将y_{ij}-\bar y,y_{ij}-\overline{y_{i\boldsymbol ·}},\overline {y_{i\boldsymbol ·}}-\bar y在所有试验上遍历一遍,但它们的自由度不同。下面证明一个很重要的结论:
结论:SST=SSE+SSA
它的证明又要用到“加一项减一项”这个小技巧。首先我们有:
\begin{aligned}\forall i\in \{1,2,\cdots,r\},\sum_{j=1}^{m}(y_{ij}-\overline{y_{i\boldsymbol ·}})=0\end{aligned} 由此得到:
\begin{aligned}\sum_{i=1}^{r}\sum_{j=1}^{m}(\overline{y_{i\boldsymbol ·}}-\bar y)(y_{ij}-\overline{y_{i\boldsymbol ·}})=\sum_{i=1}^{r}\left[(\overline{y_{i\boldsymbol ·}}-\bar y)\sum_{j=1}^{m}\left(y_{ij}-\overline{y_{i\boldsymbol ·}}\right)\right]=0\end{aligned} 从而有SST的分解:
\begin{aligned}SST&=\sum_{i=1}^{r}\sum_{j=1}^{m}(y_{ij}-\bar y)^2\\&=\sum_{i=1}^{r}\sum_{j=1}^{m}\left[(y_{ij}-\overline{y_{i\boldsymbol ·}})+(\overline{y_{i\boldsymbol ·}}-\bar y)\right]^2\\&=\sum_{i=1}^{r}\sum_{j=1}^{m}(y_{ij}-\overline{y_{i\boldsymbol ·}})^2+\sum_{i=1}^{r}\sum_{j=1}^{m}(\overline {y_{i\boldsymbol ·}}-\bar y)^2+2\sum_{i=1}^{r}\sum_{j=1}^{m}(\overline{y_{i\boldsymbol ·}}-\bar y)(y_{ij}-\overline{y_{i\boldsymbol ·}})\\&=SSE+SSA+0=SSE+SSA\end{aligned} 而且它们自由度的也可以分解:
n-1=(n-r)+(r-1) 现在我们回归正题:推导出一个F统计量。
首先放数理统计的一个基本定理:
若\{X_i\}_{i=1}^{n}是来自正态分布N(\mu,\sigma^2)的样本,定义样本均值和样本方差:
\bar X=\frac{1}{n}\sum_{i=1}^{n}X_i,\quad s^2=\frac{1}{n-1}\sum_{i=1}^{n}(X_i-\bar X)^2,从而:
(1) \bar X与s^2独立
(2) \bar X \sim N(\mu,\frac{\sigma^2}{n})
(3) \frac{(n-1)s^2}{\sigma^2}\sim \chi^2(n-1) 接着我们考虑SSE。
由(1)知\varepsilon_{ij}\sim N(0,\sigma^2),由基本定理(3):
\forall i\in\{1,2,\cdots,r\}
\begin{aligned}\frac{(m-1)·\frac{1}{m-1}\sum_{i=1}^{m}(\varepsilon_{ij}-\overline{\varepsilon_{i\boldsymbol ·}})^2}{\sigma^2}&=\frac{\sum_{j=1}^{m}(\varepsilon_{ij}-\overline{\varepsilon_{i\boldsymbol ·}})^2}{\sigma^2}\\&\sim \chi^2(m-1)\end{aligned} 且对于不同的i,该随机变量是独立的。由卡方变量的可加性以及n=mr:
\begin{aligned}\sum_{i=1}^r\frac{\sum_{j=1}^{m}(\varepsilon_{ij}-\overline{\varepsilon_{i\boldsymbol ·}})^2}{\sigma^2}\sim \chi^2\left(\sum_{i=1}^{r}(m-1)\right)=\chi^2(n-r)\end{aligned} 由(2)和(7):
y_{ij}-\overline{y_{i\boldsymbol ·}}=(\mu_i+\varepsilon_{ij})-(\mu_i+\overline{\varepsilon_{i\boldsymbol ·}})=\varepsilon_{ij}-\overline{\varepsilon_{i\boldsymbol ·}} 从而\frac{SSE}{\sigma^2}即为自由度为n-r的卡方变量:
\begin{aligned}\frac{SSE}{\sigma^2}&=\frac{1}{\sigma^2}\sum_{i=1}^{r}\sum_{j=1}^{m}(y_{ij}-\overline{y_{i\boldsymbol ·}})^2\\&=\sum_{i=1}^r\frac{\sum_{j=1}^{m}(\varepsilon_{ij}-\overline{\varepsilon_{i\boldsymbol ·}})}{\sigma^2}\sim \chi^2(n-r)\end{aligned} 然后我们考虑SSA。
由于\varepsilon_{ij}\sim N(0,\sigma^2),由基本定理(2):\overline{\varepsilon_{i\boldsymbol ·}}\sim N\left(0,\frac{\sigma^2}{m}\right)。由基本定理(3):
\begin{aligned}\frac{(r-1)·\frac{1}{r-1}\sum_{i=1}^{r}(\overline{\varepsilon_{i\boldsymbol ·}}-\bar \varepsilon)^2}{\frac{\sigma^2}{m}}&=\frac{\sum_{i=1}^{r}m(\varepsilon_{ij}-\overline{\varepsilon_{i\boldsymbol ·}})^2}{\sigma^2}\\&\sim \chi^2(r-1)\end{aligned} 由(7)、(10)和(4):
\begin{aligned}\overline{y_{i\boldsymbol ·}}-\bar y&=(\mu_i+\overline{\varepsilon_{i\boldsymbol ·}})-(\mu+\bar \varepsilon)\\&=(\mu_i-\mu)+\overline{\varepsilon_{i\boldsymbol ·}}-\bar \varepsilon\\&=a_i+\overline{\varepsilon_{i\boldsymbol ·}}-\bar \varepsilon\end{aligned} 在H_0:\mu_1=\mu_2=\cdots=\mu_r成立的条件下:
\begin{aligned}a_i&=\mu_i-\mu=\mu_i-\sum_{i=1}^r\mu_i=0\\&\rightarrow\overline{y_{i\boldsymbol ·}}-\bar y=\overline{\varepsilon_{i\boldsymbol ·}}-\bar \varepsilon\end{aligned} 从而\frac{SSA}{\sigma^2}即为自由度为r-1的卡方变量:
\begin{aligned}SSA&=\sum_{i=1}^{r}m(\overline {y_{i\boldsymbol ·}}-\bar y)^2\\&=\frac{\sum_{i=1}^{r}m(\varepsilon_{ij}-\overline{\varepsilon_{i\boldsymbol ·}})^2}{\sigma^2}\\&\sim \chi^2(r-1)\end{aligned} 下面证明SSA和SSE相互独立:
由基本定理(1):\forall i \in \{1,2,\cdots,r\} \sum_{j=1}^m(\varepsilon-\overline{\varepsilon_{i\boldsymbol ·}})^2与均值\overline{\varepsilon_{i\boldsymbol ·}}独立,从而\overline{\varepsilon_{i\boldsymbol ·}}与SSE独立。而SSA是\overline{\varepsilon_{i\boldsymbol ·}}的函数,从而SSA和SSE相互独立。
至此,根据F分布的构造定义:
\frac{SSA/(r-1)}{SSE(n-r)}\sim F(r-1,n-r) 我们定义上式中的分子和分母分别为:
MSA=\frac{SSA}{r-1},\quad MSE=\frac{SSE}{n-r} 取显著性水平\alpha,当利用样本数据算得的F=\frac{MSA}{MSE}>F_{\alpha,(r-1,n-r)},可以认为这在一次抽样中几乎不可能发生,从而拒绝原假设,认为因素A显著。列出方差分析表如下:
\begin{array}{c|c} \text{变异来源} & \text{偏差平方和}&自由度&均方&F&p值 \\ \hline 组间 & SSA&r-1&MSA=\frac{SSA}{r-1}&\frac{MSA}{MSE}&P(F_{\alpha,(r-1,n-r)})>F\\ 组内 & SSE&n-r&MSE=\frac{SSE}{n-r}&-&-\\总变异&SST&n-1&-&-&-\\\end{array}\\
3.线性回归方程整体的显著性检验
首先要说一点,线性回归方程的总变差也可以像方差分析一样分解:
总离差平方和=回归平方和+残差平方和
但是它们的英文缩写五花八门,譬如我知道的就有这么两种:
1.“SS?”型
总离差平方和=回归平方和+残差平方和
SST=SSR+SSE
SST:Sum of Squares for Total 总离差平方和
SSR:Sum of Squares for Regression 回归平方和
SSE:Sum of Squares for Erroe 误差平方和 2.“?SS”型
总离差平方和=能被回归方程解释的那部分的平方和+剩余平方和
TSS=ESS+RSS
TSS:Total Sum of Squares 总离差平方和
ESS:Explained Sum of Squares 能被回归方程解释的那部分的平方和,也翻译为回归平方和
RSS:Residual Sum of Squares 剩余平方和,也翻译为残差平方和 这里就统一用第一种以免引起误会吧。
首先给出多元线性回归方程的矩阵表达式:
\boldsymbol {y}=\boldsymbol{X}\boldsymbol{\beta}+\boldsymbol\varepsilon \quad or\quad \boldsymbol {\hat y}=\boldsymbol{X}\boldsymbol{\hat \beta} \quad(11) 其中:
\boldsymbol {y}=\left( \begin{matrix} y_1\\y_2\\\vdots\\y_n \end{matrix} \right)_{n×1},\quad\boldsymbol {X}=\left( \begin{matrix} 1&x_{11}&x_{12}&\cdots&x_{1p}\\1&x_{21}&x_{22}&\cdots&x_{2p}\\\vdots&\vdots&\vdots&&\vdots\\1&x_{n1}&x_{n2}&\cdots&x_{np} \end{matrix} \right)_{n×(p+1)}
\boldsymbol {\beta}=\left( \begin{matrix} \beta_0\\\beta_1\\\vdots\\\beta_p \end{matrix} \right)_{(p+1)×1},\quad\boldsymbol {\varepsilon}=\left( \begin{matrix} \varepsilon_1\\\varepsilon_2\\\vdots\\\varepsilon_n \end{matrix} \right)_{n×1}\sim \boldsymbol N(\boldsymbol 0,\sigma^2\boldsymbol I_n) 其中\boldsymbol I_n为n阶单位方阵。方程满足\boldsymbol X满秩、Gauss-Markov条件、随机误差项服从正态分布等假定。
定义残差e_i=y_i-\hat y_i,从而残差向量:
\left(\begin{matrix}e_1\\e_2\\\vdots\\e_n\end{matrix}\right):=\boldsymbol e=\boldsymbol y-\boldsymbol {\hat y}=\boldsymbol y-\boldsymbol {X}\boldsymbol {\hat \beta} 利用最小二乘估计,在一文详解t检验的附录2.1中已得到:
\boldsymbol X^T(\boldsymbol y-\boldsymbol X\boldsymbol {\hat\beta})=\boldsymbol 0 也就是:
\boldsymbol X^T\boldsymbol e=\boldsymbol 0\quad(12) 看X^T的结构,取它的第一行与\boldsymbol e相乘等于0,可以得到:
\boldsymbol 1_n^T\boldsymbol e=0\quad(13) 其中\boldsymbol 1_n表示n×1阶元素全为一的列向量。
定义SST、SSR和SSE:
总离差平方和:SST=||\boldsymbol y-{\bar y}\boldsymbol 1_n||^2
回归平方和:SSR=||\boldsymbol {\hat y}-\bar y\boldsymbol 1_n||^2
残差平方和:SSE=||\boldsymbol y-\boldsymbol{\hat y}||^2 下面证明总离差平方和分解式SST=SSR+SSE,最后两个等号应用了(11)、(12):
\begin{aligned}SST&=||\boldsymbol y-{\bar y}\boldsymbol 1_n||^2\\&=||(\boldsymbol y-\boldsymbol{\hat y})+(\boldsymbol {\hat y-\bar y\boldsymbol 1_n})||^2\\&=||\boldsymbol y-\boldsymbol{\hat y}||^2+2(\boldsymbol y-\boldsymbol{\hat y})^T({\boldsymbol{\hat y}-\bar y\boldsymbol 1_n})+||\boldsymbol {\hat y}-\bar y\boldsymbol 1_n||^2\\&=SSE+2\boldsymbol e^T({\boldsymbol{\hat y}-\bar y\boldsymbol 1_n})+SSR\\&=SSE+SSR+2\boldsymbol e^T\boldsymbol{\hat y}-2\bar y\boldsymbol e^T\boldsymbol {1_n}\end{aligned} 考虑上式中的最后两项,由(11)、(12)和(13):
\begin{aligned}2\boldsymbol e^T\boldsymbol{\hat y}-2\bar y\boldsymbol {1_n}\boldsymbol e^T&=2\boldsymbol e^T\boldsymbol X\boldsymbol {\hat\beta}-2\bar y\boldsymbol 0\\&=2(\boldsymbol X^T\boldsymbol e)^T\boldsymbol {\hat\beta}\\&=2\boldsymbol 0^T\boldsymbol {\hat\beta}\\&=0\end{aligned} 从而:SST=SSR+SSE.
我们不加证明地给出F统计量及方差分析表:
F=\frac{SSR/p}{SSE/(n-p-1)} \begin{array}{c|c} \text{方差来源} & \text{偏差平方和}&自由度&均方&F&p值 \\ \hline 回归 & SSR&p&MSR=\frac{SSR}{p}&\frac{SSR/p}{SSE/(n-p-1)}&P(F_{\alpha,(p,n-p-1)})>F\\ 残差 & SSE&n-p-1&MSE=\frac{SSE}{n-p-1}&-&-\\总变异&SST&n-1&-&-&-\\\end{array}\\
要注意的是对多元线性回归的F检验是用来检验线性方程整体的显著性,可以理解为“线性模型”这个假定对于解释被解释变量的变动是否显著,也就是说当方程的F检验不显著时,就要考虑非线性的模型了。
最后有个小结论:在一元线性回归中,对解释变量的t检验的t统计量的平方=对方程整体显著性F检验的F统计量,而且两个检验是等价的。
参考文献
[1]王炳顺等.医学统计学及SAS应用[M].上海交通大学出版社:上海,2009:95:135.
[2]George Casella,Roger L. Berger.Statistical Inference[M].Duxbury Press:Belmont, California,2001:521-534.
[3]Douglas C. Montgomery.Design and Analysis of Experiments[M].John Wiley & Sons:New York,2012.
[4]茆诗松,程依明,濮晓龙.概率论与数理统计教程[M].高等教育出版社:北京,2011:423-429.
[5]何晓群,刘文卿.应用回归分析[M].中国人民大学出版社:北京,2001:72-73.
[6]https://en.wikipedia.org/wiki/F-test
原文地址:https://zhuanlan.zhihu.com/p/139151375 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-3-31 19:02
发表于 2025-3-31 19:02



