金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
Embodied Intelligence作为一种将感知、决策与执行相结合的前沿技术,正在引领机器人技术迈向新的高度。具身智能不仅要求机器人具备理解和处理复杂环境的能力,还需赋予其自主决策和执行任务的能力。本文将深入探讨如何将LLM和多模态大模型与机器人技术相结合,构建一套完整的具身智能技术流程。本文参考了同济子豪兄的部分工作,TsingtaoAI团队对整体构建做了一部分拓展和延伸。文中相关流程和代码仅作示例,用于读者理解相关的内部实现逻辑,不具备工程复现意义。
本文目录
- 一套最小的具身智能应用实现流程
- 系统架构设计
- LLM与机器人集成
- 多模态大模型的应用
- 自主决策与执行模块
- 传感器与执行器接口
- 通信与数据处理
- 系统部署与优化
- 案例分析与代码示例
- 未来展望
01
一套最小的具身智能应用实现流程
具身智能强调机器人不仅具备感知和认知能力,还能够通过与环境的交互实现自主行为。与传统的机器人相比,具身智能机器人更具适应性和灵活性,能够在复杂、多变的环境中执行任务。这一概念的核心在于将感知、认知和动作控制有机结合,使机器人具备类似人类的智能行为。
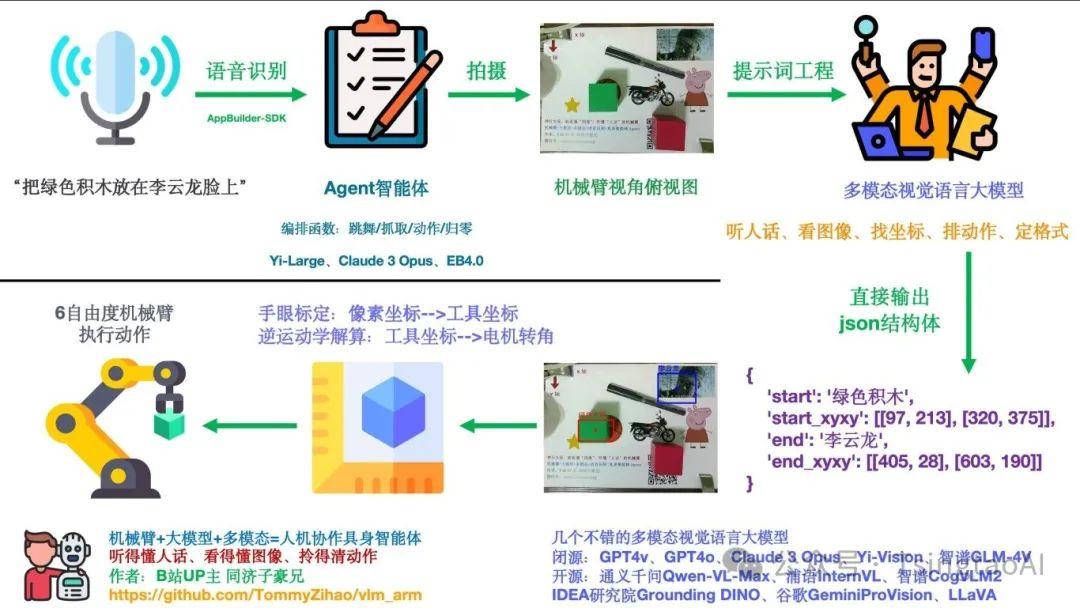
一套最小的具身智能应用实现流程-引自同济子豪兄
1.1 具身智能的关键要素
- 感知能力:通过多种传感器获取环境信息,包括视觉、听觉、触觉等。
- 认知能力:利用AI模型进行信息处理和理解,实现环境建模和任务规划。
- 动作控制:通过执行器实现对环境的物理操作,完成特定任务。
- 自主决策:基于感知和认知结果,自主制定行动策略。
02
系统架构设计
构建具身智能系统需要一个高度集成的架构,涵盖感知、认知、决策与执行等多个模块。以下是一个典型的具身智能系统架构图:
diff复制代码+-----------------------+| 感知模块 || - 摄像头 || - 麦克风 || - 触觉传感器 |+----------+------------+ | v+----------+------------+| 数据处理 || - 数据预处理 || - 特征提取 |+----------+------------+ | v+----------+------------+| 认知模块 || - 大型语言模型(LLM) || - 多模态大模型 |+----------+------------+ | v+----------+------------+| 决策与规划模块 || - 行为规划 || - 决策树 |+----------+------------+ | v+----------+------------+| 执行模块 || - 机械臂控制 || - 动作执行 |+-----------------------+
2.1 模块详细说明
- 感知模块:负责采集环境数据,包括视觉、听觉和触觉等多种传感器信息。
- 数据处理:对采集到的数据进行预处理和特征提取,为认知模块提供高质量的输入。
- 认知模块:利用LLM和多模态大模型对数据进行理解和分析,生成上下文相关的信息。
- 决策与规划模块:基于认知结果,制定具体的行动计划和策略。
- 执行模块:将决策转化为具体的物理动作,通过机械臂等执行器完成任务。
03
LLM与机器人集成
大型语言模型,如OpenAI的GPT-4o,具备强大的自然语言理解和生成能力。将LLM集成到机器人系统中,可以显著提升机器人的交互能力和决策水平。
3.1 LLM的选择与部署
在选择LLM时,需要考虑模型的性能、响应速度和资源消耗。当前,主流的LLM包括:
- Yi-Large:具有强大的中文理解和生成能力,适合中文环境下的应用。
- Claude 3:以其稳健性和高效性著称,适用于多种任务场景。
- ERNIE 4.0:百度推出的多任务学习模型,在中文NLP任务中表现优异。
3.1.1 部署环境
为了实现高效的模型运行,建议使用亚马逊云科技的生成式AI平台Amazon Bedrock。Bedrock提供了高性能的计算资源和便捷的模型管理接口,适合大规模部署LLM。
pythonimport boto3# 初始化Bedrock客户端bedrock_client=boto3.client%28%27bedrock%27, region_name=%27us-west-2%27%29# 调用LLM进行文本生成response = bedrock_client.invoke_model%28 ModelId=%27ernie-4.0%27, Prompt=%27你好,机器人!今天的任务是什么?%27, MaxTokens=150%29print%28response[%27GeneratedText%27]%293.2 LLM与感知模块的融合
LLM不仅可以处理文本指令,还能结合视觉和听觉信息,实现更复杂的交互。通过多模态输入,机器人可以更准确地理解用户意图。
pythonfrom transformers import CLIPProcessor,CLIPModel import torch# 初始化多模态模型clip_model=CLIPModel.from_pretrained%28"openai/clip-vit-base-patch32"%29clip_processor=CLIPProcessor.from_pretrained%28"openai/clip-vit-base-patch32"%29def process_multimodal%28image, text%29: inputs = clip_processor%28text=[text], images=image, return_tensors="pt", padding=True%29 outputs = clip_model%28%2A%2Ainputs%29 logits_per_image =outputs.logits_per_image probs =logits_per_image.softmax%28dim=1%29 return probs# 示例调用image = Image.open%28"example.jpg"%29text = "这是一个红色的苹果。"prob = process_multimodal%28image, text%29print%28prob%29
3.3 自然语言指令解析与执行
通过LLM,机器人可以解析自然语言指令,并将其转化为具体的动作指令。例如,用户可以通过语音指令“请将红色的物体拿起来”,机器人通过LLM解析后,结合视觉信息,执行相应的动作。
pythondef parse_instruction%28instruction%29: # 使用LLM解析指令 response = bedrock_client.invoke_model%28 ModelId=%27yi-large%27, Prompt=instruction, MaxTokens=100%29 action_plan = response[%27GeneratedText%27] return action_planinstruction = "请将红色的物体拿起来。"action = parse_instruction%28instruction%29print%28action%29
04
多模态大模型的应用
多模态大模型结合了文本、图像、音频等多种数据类型的处理能力,赋予机器人更全面的感知和理解能力。当前,主流的多模态大模型包括GPT-4o、Yi-Vision、Claude 3 Opus等。
4.1 多模态模型的选择与集成
选择合适的多模态模型是实现具身智能的关键。以下是几种常用的多模态模型及其特点:
- GPT-4o:在多模态理解和生成方面表现优异,适合复杂场景下的应用。
- Yi-Vision:专注于中文图像理解,适合中文环境下的视觉任务。
- Claude 3 Opus:结合了音频和视觉信息,适用于需要听觉与视觉结合的任务。
4.1.1 集成示例
以GPT-4o为例,展示如何将图像和文本输入结合,进行综合理解。
pythonfrom transformers import GPT4oProcessor,GPT4oModelfrom PIL import Image# 初始化多模态处理器和模型processor=GPT4oProcessor.from_pretrained%28"openai/gpt4o"%29model=GPT4oModel.from_pretrained%28"openai/gpt4o"%29def multimodal_inference%28image_path, text%29: image = Image.open%28image_path%29 inputs = processor%28text=text, images=image, return_tensors="pt"%29 outputs = model%28%2A%2Ainputs%29 return outputs# 示例调用image_path="scene.jpg"text="描述这张图片中的主要物体和动作。"outputs=multimodal_inference%28image_path, text%29print%28outputs%29
4.2 多模态信息融合
在具身智能中,融合多模态信息是提升机器人理解能力的重要手段。通过结合视觉、听觉和文本信息,机器人能够更准确地感知环境和用户意图。
pythondef fuse_multimodal_data%28image, audio, text%29: # 处理视觉信息 visual_features=clip_model.get_image_features%28clip_processor%28images=image, return_tensors="pt"%29["pixel_values"]%29 # 处理音频信息 audio_features=audio_model.extract_features%28audio%29 # 处理文本信息 text_features = llm_model.encode%28text%29 # 融合特征 fused_features =torch.cat%28%28visual_features, audio_features, text_features%29, dim=1%29 return fused_features# 示例调用image = Image.open%28"object.jpg"%29audio = load_audio%28"command.wav"%29text = "请识别并抓取桌上的苹果。"features =fuse_multimodal_data%28image, audio, text%29print%28features%29
05
自主决策与执行模块
自主决策是具身智能机器人的核心,通过结合认知模块的输出,制定具体的行动计划。决策模块需要具备灵活性和适应性,能够应对动态变化的环境。
5.1 决策树与行为规划
决策树是一种常用的决策模型,通过分层次的条件判断,确定下一步的行动。结合行为规划,机器人可以根据当前状态和目标,制定详细的行动步骤。
pythonclass DecisionNode: def__init__%28self,condition,true_branch, false_branch%29: self.condition = condition self.true_branch = true_branch self.false_branch = false_branchdef evaluate_decision%28node, context%29: if node.condition%28context%29: if isinstance%28node.true_branch, DecisionNode%29: return evaluate_decision%28node.true_branch, context%29 else: return node.true_branch else: if isinstance%28node.false_branch, DecisionNode%29: return evaluate_decision%28node.false_branch, context%29 else: return node.false_branch# 示例决策树def condition_pick_up%28context%29: return context[%27object_detected%27] and context[%27object_color%27]==%27red%27action_pick="抓取红色物体"action_search="搜索红色物体"root= DecisionNode%28condition_pick_up, action_pick, action_search%29# 示例调用context={%27object_detected%27:True,%27object_color%27:%27red%27}action=evaluate_decision%28root, context%29print%28action%29#输出:抓取红色物体
5.2 强化学习在决策中的应用
强化学习(Reinforcement Learning, RL)通过与环境的交互,不断优化策略,实现复杂任务的自主决策。利用RL,机器人能够在动态环境中学习并适应变化。
pythonimport gymimport numpy as npimport torchimport torch.nn as nnimport torch.optim as optim# 定义简单的策略网络class PolicyNetwork%28nn.Module%29: def __init__%28self, state_size, action_size%29: super%28PolicyNetwork, self%29.__init__%28%29 self.fc =nn.Linear%28state_size, 128%29 self.action_head =nn.Linear%28128, action_size%29 def forward%28self, x%29: x=torch.relu%28self.fc%28x%29%29 action_probs=torch.softmax%28self.action_head%28x%29, dim=-1%29 return action_probs# 初始化环境和网络env = gym.make%28%27CartPole-v1%27%29state_size =env.observation_space.shape[0]action_size =env.action_space.npolicy_net = PolicyNetwork%28state_size, action_size%29optimizer =optim.Adam%28policy_net.parameters%28%29, lr=1e-2%29eps = np.finfo%28np.float32%29.eps.item%28%29# 训练过程for episode in range%281000%29: state = env.reset%28%29 rewards = [] log_probs = [] done = False while not done: state =torch.from_numpy%28state%29.float%28%29 action_probs =policy_net%28state%29 m=torch.distributions.Categorical%28action_probs%29 action = m.sample%28%29 log_prob = m.log_prob%28action%29 state, reward, done, _ = env.step%28action.item%28%29%29 log_probs.append%28log_prob%29 rewards.append%28reward%29 if done: break # 计算累计奖励 cumulative_reward = 0 policy_loss = [] for log_prob, reward in zip%28log_probs, rewards%29: cumulative_reward += reward policy_loss.append%28-log_prob %2A cumulative_reward%29 optimizer.zero_grad%28%29 policy_loss =torch.cat%28policy_loss%29.sum%28%29 policy_loss.backward%28%29 optimizer.step%28%29 if episode % 100 == 0: print%28f"Episode {episode}, Reward:{cumulative_reward}"%29
5.3 行为规划的实现
行为规划需要结合具体任务,制定详细的行动步骤。例如,在抓取物体任务中,规划路径、避障策略等。
pythonimport numpy as npclass BehaviorPlanner: def __init__%28self, robot, environment%29: self.robot = robot self.environment = environment def plan_path%28self, start, goal%29: # 使用A%2A算法进行路径规划 open_set = set%28%29 open_set.add%28start%29 came_from = {} g_score = {start: 0} f_score={start: self.heuristic%28start, goal%29} while open_set: current=min%28open_set,key=lambdax:f_score.get%28x, np.inf%29%29 if current == goal: return self.reconstruct_path%28came_from, current%29 open_set.remove%28current%29for neighbor in self.environment.get_neighbors%28current%29: tentative_g = g_score[current] + self.distance%28current, neighbor%29 if tentative_g < g_score.get%28neighbor, np.inf%29: came_from[neighbor] = current g_score[neighbor] = tentative_g f_score[neighbor] =tentative_g + self.heuristic%28neighbor, goal%29 open_set.add%28neighbor%29 return [] def heuristic%28self, a, b%29: return np.linalg.norm%28np.array%28a%29 - np.array%28b%29%29 def distance%28self, a, b%29: return self.heuristic%28a, b%29 def reconstruct_path%28self, came_from, current%29: path = [current] while current in came_from: current = came_from[current] path.append%28current%29 path.reverse%28%29 return path# 示例调用robot = MyRobot%28%29environment = EnvironmentGrid%28%29planner = BehaviorPlanner%28robot, environment%29start = %280, 0%29goal = %285, 5%29path = planner.plan_path%28start, goal%29print%28f"规划路径: {path}"%29
06
传感器与执行器接口
传感器和执行器是机器人与外界交互的桥梁,确保感知信息的准确采集和动作指令的有效执行。以下将详细介绍如何集成和管理各种传感器与执行器。
6.1 视觉传感器接口
摄像头是主要的视觉传感器,通过图像处理技术,获取环境的视觉信息。
pythonimport cv2class CameraInterface: def __init__%28self, camera_id=0%29: self.cap=cv2.VideoCapture%28camera_id%29 def get_frame%28self%29: ret, frame=self.cap.read%28%29 if ret: return frame else: return None def release%28self%29: self.cap.release%28%29# 示例调用camera = CameraInterface%28%29frame = camera.get_frame%28%29if frame is not None: cv2.imshow%28%27Camera Frame%27, frame%29 cv2.waitKey%280%29camera.release%28%29cv2.destroyAllWindows%28%29
6.2 语音识别与合成
语音识别和合成是实现自然人机交互的重要手段。本文采用PaddleSpeech进行短文本在线合成和AppBuilder-SDK进行语音识别。
pythonimport paddlespeech as ps# 语音识别def recognize_speech%28audio_file%29: recognizer=ps.AsrModel.from_pretrained%28"appbuilder-sdk-short"%29 result = recognizer.recognize%28audio_file%29 return result# 语音合成def synthesize_speech%28text, output_file%29: tts=ps.TtsModel.from_pretrained%28"appbuilder-sdk-tts"%29 tts.synthesize%28text, output_file%29# 示例调用audio_input = "command.wav"recognized_text=recognize_speech%28audio_input%29print%28f"识别结果:{recognized_text}"%29text_output = "任务已完成。"synthesize_speech%28text_output, "output.wav"%29
6.3 机械臂控制接口
机械臂是机器人的执行器,通过编程接口,实现精准的动作控制。本文以Mycobot 280 Pi机械臂为例,展示如何进行控制。
pythonfrom pymycobot import Mycobot# 初始化机械臂mc = Mycobot%28"/dev/ttyUSB0", 115200%29# 移动到指定坐标def move_to%28x, y, z, r=0%29: mc.send_coords%28[x, y, z, r], 50%29# 抓取动作示例move_to%28200, 0, 100%29 # 位置1mc.set_gripper_state%28True%29 # 开启夹爪move_to%28200, 0, 200%29 # 位置2mc.set_gripper_state%28False%29 # 关闭夹爪# 示例调用move_to%28150, 50, 100%29mc.set_gripper_state%28True%29move_to%28150, 50, 200%29mc.set_gripper_state%28False%29
6.4 传感器数据同步与管理
确保传感器数据的同步与高效管理,是实现准确控制的基础。可以通过多线程或异步编程,实现多传感器数据的并行处理。
pythonimport threadingclass SensorManager: def __init__%28self%29: self.camera = CameraInterface%28%29 self.audio = AudioInterface%28%29 self.lock = threading.Lock%28%29 self.latest_frame = None self.latest_audio = None def start_camera%28self%29: def camera_thread%28%29: while True: frame = self.camera.get_frame%28%29 with self.lock: self.latest_frame = frame threading.Thread%28target=camera_thread, daemon=True%29.start%28%29 def start_audio%28self%29: def audio_thread%28%29: while True: audio = self.audio.get_audio%28%29 with self.lock: self.latest_audio = audio threading.Thread%28target=audio_thread, daemon=True%29.start%28%29 def get_latest_data%28self%29: with self.lock: return self.latest_frame, self.latest_audio# 示例调用sensor_manager = SensorManager%28%29sensor_manager.start_camera%28%29sensor_manager.start_audio%28%29# 在主循环中获取最新数据while True: frame, audio=sensor_manager.get_latest_data%28%29 if frame is not None: cv2.imshow%28%27Live Frame%27, frame%29 if audio is not None: print%28f"最新音频数据: {audio}"%29 if cv2.waitKey%281%29 & 0xFF == ord%28%27q%27%29: break
07
通信与数据处理
在具身智能系统中,通信与数据处理是保证各模块高效协作的关键。以下将介绍如何实现模块间的通信与数据同步。
7.1 模块间通信机制
可以采用消息队列(如RabbitMQ)、共享内存或RESTful API等方式,实现模块间的通信。本文以RabbitMQ为例,展示如何实现消息传递。
pythonimport pikaimport json# 发送消息def send_message%28queue, message%29: connection=ika.BlockingConnection%28pika.ConnectionParameters%28%27localhost%27%29%29 channel = connection.channel%28%29 channel.queue_declare%28queue=queue%29 channel.basic_publish%28exchange=%27%27, routing_key=queue, body=json.dumps%28message%29%29 connection.close%28%29# 接收消息def receive_message%28queue, callback%29: connection=pika.BlockingConnection%28pika.ConnectionParameters%28%27localhost%27%29%29 channel = connection.channel%28%29 channel.queue_declare%28queue=queue%29 channel.basic_consume%28queue=queue, on_message_callback=lambda ch, method, properties, body: callback%28json.loads%28body%29%29, auto_ack=True%29 channel.start_consuming%28%29# 示例调用def action_callback%28message%29: print%28f"接收到消息: {message}"%29# 发送send_message%28%27action_queue%27,{%27action%27: %27move%27, %27parameters%27:{%27x%27: 100, %27y%27: 200}}%29# 接收receive_message%28%27action_queue%27, action_callback%29
7.2 数据处理与存储
在大规模数据处理场景下,采用分布式数据库(如MongoDB、PostgreSQL)和实时数据处理框架(如Apache Kafka、Spark)是必要的。本文以MongoDB为例,展示数据的存储与查询。
pythonfrom pymongo import MongoClient# 连接MongoDBclient = MongoClient%28%27mongodb://localhost:27017/%27%29db = client[%27robot_db%27]collection = db[%27sensor_data%27]# 插入数据def insert_sensor_data%28data%29: collection.insert_one%28data%29# 查询数据def query_sensor_data%28query%29: return collection.find%28query%29# 示例调用sensor_data = { %27timestamp%27:%272024-04-27T10:00:00Z%27, %27sensor%27: %27camera%27, %27data%27: %27image_bytes...%27}insert_sensor_data%28sensor_data%29results = query_sensor_data%28{%27sensor%27: %27camera%27}%29for result in results: print%28result%29
7.3 实时数据处理
实时数据处理对于具身智能系统的响应速度至关重要。可以采用流处理框架,如Apache Kafka,实现数据的实时传输与处理。
pythonfrom kafka import KafkaProducer, KafkaConsumer# 生产者发送消息producer = KafkaProducer%28bootstrap_servers=%27localhost:9092%27%29producer.send%28%27sensor_topic%27, b%27新传感器数据%27%29producer.flush%28%29# 消费者接收消息consumer=KafkaConsumer%28%27sensor_topic%27, bootstrap_servers=%27localhost:9092%27%29for message in consumer: print%28f"接收到消息: {message.value}"%29
08
系统部署与优化
高效的系统部署与优化,能够显著提升具身智能机器人的性能与可靠性。以下将探讨系统部署的最佳实践及性能优化策略。
8.1 部署环境配置
确保系统在稳定的环境中运行,是实现高效部署的基础。推荐使用树莓派4B搭载Ubuntu 20.04作为开发环境,结合云平台资源,实现本地与云端的协同工作。
bash# 更新系统sudo apt updatesudo apt upgrade -y# 安装必要的软件包sudo apt install -y python3-pip git# 克隆项目代码git clone https://github.com/TommyZihao/vlm_arm.gitcd vlm_arm# 创建虚拟环境python3 -m venv venvsource venv/bin/activate# 安装依赖pip install -r requirements.txt
8.2 性能优化策略
针对具身智能系统的高计算需求,以下是几种常用的性能优化策略:
- 模型压缩与剪枝:减少模型参数量,提升推理速度。
- 硬件加速:利用GPU或TPU加速计算,提升处理效率。
- 并行计算:采用多线程或分布式计算,提升数据处理能力。
- 缓存机制:对频繁访问的数据进行缓存,减少重复计算。
pythonimport torchimport torch.nn.utils.prune as prune# 模型剪枝示例def prune_model%28model, amount=0.3%29: for name, module in model.named_modules%28%29: if isinstance%28module, torch.nn.Linear%29: prune.l1_unstructured%28module, name=%27weight%27, amount=amount%29 return model# 示例调用pruned_model = prune_model%28policy_net, amount=0.2%29
8.3 系统监控与维护
实时监控系统状态,及时发现并解决潜在问题,是保证系统稳定运行的重要手段。可以采用Prometheus和Grafana进行系统监控与可视化。
yaml# Prometheus配置示例global: scrape_interval: 15sscrape_configs: - job_name: %27robot_system%27 static_configs: - targets: [%27localhost:9090%27]yaml复制代码# Grafana数据源配置apiVersion: 1datasources: - name: Prometheus type: prometheus url: http://localhost:9090
09
案例分析与代码示例
为更好地理解具身智能技术流程,以下通过具体案例进行分析,并提供相应的代码示例。
9.1 案例背景
假设我们要实现一个具身智能机器人,通过语音指令控制机械臂抓取指定颜色的物体。具体流程包括语音识别、指令解析、视觉识别、路径规划与机械臂控制。
9.2 实现步骤
9.2.1 语音指令获取与解析
python# 语音指令获取def get_voice_command%28%29: audio_file = "command.wav" record_audio%28audio_file%29 #假设有录音函数 command = recognize_speech%28audio_file%29 return command# 指令解析def parse_command%28command%29: action_plan=parse_instruction%28command%29 return action_plan# 示例调用voice_command = get_voice_command%28%29action_plan = parse_command%28voice_command%29print%28f"解析后的指令: {action_plan}"%29
9.2.2 视觉识别与目标定位
pythonfrom PIL import Imageimport torchdef detect_object%28image, target_color%29: # 使用多模态模型进行颜色识别 response = multimodal_inference%28image, f"找到一个{target_color}的物体。"%29 # 假设返回物体的坐标 object_coords = extract_coordinates%28response%29 return object_coords# 示例调用frame = camera.get_frame%28%29target_color = "红色"object_coords = detect_object%28frame, target_color%29print%28f"目标物体坐标: {object_coords}"%29
9.2.3 路径规划与机械臂控制
python# 规划路径path=planner.plan_path%28current_position, object_coords%29# 执行路径for point in path: move_to%28point[0], point[1], point[2]%29 # 添加必要的延时和状态检查
9.2.4 完整流程整合
pythondef main%28%29: # 获取并解析语音指令 voice_command = get_voice_command%28%29 action_plan = parse_command%28voice_command%29 if action_plan[%27action%27]==%27抓取%27and%27颜色%27 in action_plan[%27parameters%27]: target_color =action_plan[%27parameters%27][%27颜色%27] # 视觉识别 frame=camera.get_frame%28%29 object_coords=detect_object%28frame, target_color%29 if object_coords: # 路径规划 path=planner.plan_path%28current_position,object_coords%29 # 执行动作 for point in path: move_to%28point[0], point[1], point[2]%29 # 抓取物体 mc.set_gripper_state%28True%29 move_to%28grasp_position%29 mc.set_gripper_state%28False%29 print%28"抓取任务完成。"%29 else: print%28f"未检测到{target_color}的物体。"%29 else: print%28"不支持的指令。"%29# 运行主函数if __name__ == "__main__": main%28%29
10
未来展望
本文深入探讨了一套基本的具身智能技术流程,从系统架构设计到具体模块的实现,涵盖了最新的LLM、多模态大模型与机器人技术的集成方法。通过详细的技术分析和代码示例,展示了如何实现AI机器人的自主决策与执行能力。
具身智能作为机器人技术的前沿方向,未来的发展潜力巨大。随着AI模型的不断进步和硬件技术的提升,具身智能机器人将在更多领域展现其价值。以下是几个值得关注的发展趋势:
- 自适应学习:机器人能够根据环境变化,自主调整策略,实现持续学习和优化。
- 情感交互:通过情感识别与表达,提升人机交互的自然性和亲和力。
- 协同工作:多机器人协作,共同完成复杂任务,提高整体效率。
- 智能感知:更加精准和多样化的感知能力,提升机器人在复杂环境中的适应性。
在高校实训教育领域,目前TsingtaoAI公司推出了具身智能高校实训解决方案-从AI大模型+机器人到通用具身智能”,该方案基于华为技术有限公司AI框架昇思MindSpore,完成并通过昇腾相互兼容性技术认证。


专家招募
TsingtaoAI面向全球范围的LLM大模型、具身智能、AI机器人、智算、AIGC、数据科学、金融科技、5G、信创、智能制造、智慧能源等领域招募专家讲师。有多种方式合作,合作方式灵活,收益丰厚。欢迎感兴趣的专家与我们联系。
https://u.wechat.com/EIWDQkhxEDWojEQJv7hEnQs (二维码自动识别)
原文地址:https://zhuanlan.zhihu.com/p/18715623030 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-1-29 20:55
发表于 2025-1-29 20:55



