金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
最近在大量阅读时间序列挖掘相关的文献,今天特意系统性地回答一下这个问题。此回答主要做一个系统性科普,不会涉及太多数学/统计的细节。本回答的结构安排如下。
- 一个好的相似度度量方法(Similarity Measure)需要具备哪些好的性质?
- 现有的时间序列相似度度量方法(Time Series Similarity Measure)分类以及简要介绍?
- 现有的时间序列相似度度量方法(Time Series Similarity Measure)总结?
<hr/>第一节:一个好的相似度度量方法(Similarity Measure)需要具备哪些好的性质?
备注: 我这里说的Similarity Measure是指一般的相似度度量,而不局限于时间序列相似度度量(Time Series Similarity Measure).
- Similarity Measure能够识别在感觉上比较相似、但是在数学意义上不完全一样的物体。比如说下图中的叶子哪一些比较相似?因为世界上没有两片一模一样的叶子,所以一个好的相似度度量方法需要能够识别感觉上/直观上比较相似的叶子。

source: [1]
2. Similarity Measure的结果应该和人类的直觉相符合。如果你告诉我上图中的枫叶和扇形叶子的形状很相似,那我只能说你在扯蛋。
3. Similarity Measure, 不管在全局(global),还是局部(local)水平上,都应该重点关注一个物体的显著特征,而不是鸡毛蒜皮的无关细节。比如说,你告诉我上图中的枫叶和扇形叶子很相似,因为它们的边缘都是呈现小锯齿状(local feature)。你也告诉我,上图中的两片扇形叶子很相似,因为它们都是扇形(global feature)。我都会觉得你说得有道理。 但是如果你告诉我,上图中的枫叶和扇形叶子很相似,因为它们上面都有泥巴,我只能说“我不关心这个”。
上面三点描述的是通用的Similarity Measure,现在来讨论Time Series Similarity Measure.
4. 除了以上的通用方面外,对于一个好的Time Series Similarity Measure来讲,它应该能够比较两个长度不相等的时间序列。(然而,如果两条时间序列长度相差太大,计算它们的相似度也会变得没有意义[2])
5. 一个好的Time Series Similarity Measure的复杂度应该越低越好。换句话说,Time Complexity 和 Space Complexity 都要小。
6. 一个好的Time Series Similarity Measure应该对各种扭曲(distortion)和变换(transformation)不敏感。具体有哪些distortion和transformation呢?具体见下图。
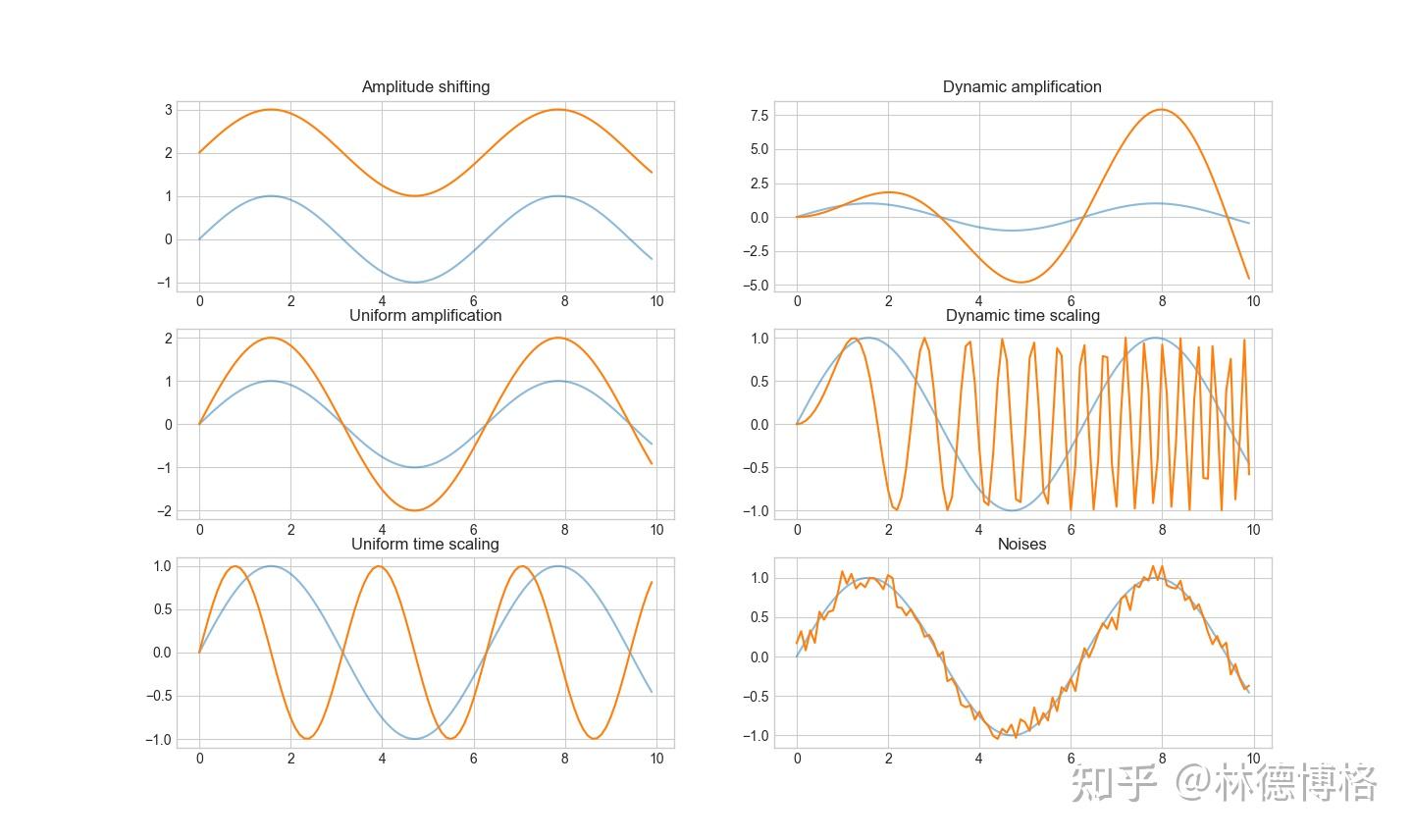
蓝色代表原始时间序列,橙色代表扭曲或者变换之后的时间序列
在理想情况下,上面六对时间序列应该被看作是相似的。也就是说,一个好的Time Series Similarity Measure应该对这些扭曲和变换不敏感。
&#34;&#34;&#34;
用于复现上述distortion, transformation 的python代码
Created on Fri Mar 4 10:01:27 2022
@author: zlifr
““”
import numpy as np
import matplotlib.pyplot as plt
fig, axs = plt.subplots(3,2)
##Raw time series
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)
axs[0,0].plot(time, amplitude, alpha = 0.5)
axs[1,0].plot(time, amplitude, alpha = 0.5)
axs[2,0].plot(time, amplitude, alpha = 0.5)
axs[0,1].plot(time, amplitude, alpha = 0.5)
axs[1,1].plot(time, amplitude, alpha = 0.5)
axs[2,1].plot(time, amplitude, alpha = 0.5)
##Amplitude shifting
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)+2
axs[0,0].plot(time, amplitude)
axs[0,0].set_title(&#34;Amplitude shifting&#34;)
##Uniform amplification
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)*2
axs[1,0].plot(time, amplitude)
axs[1,0].set_title(&#34;Uniform amplification&#34;)
##Uniform time scaling
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time*2)
axs[2,0].plot(time, amplitude)
axs[2,0].set_title(&#34;Uniform time scaling&#34;)
##Dynamic amplification
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)*time
axs[0,1].plot(time, amplitude)
axs[0,1].set_title(&#34;Dynamic amplification&#34;)
##Dynamic time scaling
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time*time)
axs[1,1].plot(time, amplitude)
axs[1,1].set_title(&#34;Dynamic time scaling&#34;)
##Noises
time = np.arange(0, 10, 0.1);
amplitude = np.sin(time)+np.random.normal(0,0.1,100)
axs[2,1].plot(time, amplitude)
axs[2,1].set_title(&#34;Noises&#34;)<hr/>第二节:现有的时间序列相似度度量方法(Time Series Similarity Measure)分类以及简要介绍?
Time Series Similarity Measure大概可以分为四类:
- 基于形状的(Shape Based Time Series Similarity Measure)
- 基于编辑距离的(Edit Based Time Series Similarity Measure)
- 基于特征的(Feature Based Time Series Similarity Measure)
- 基于结构的(Structure Based Time Series Similarity Measure)
- Shape Based Time Series Similarity Measure
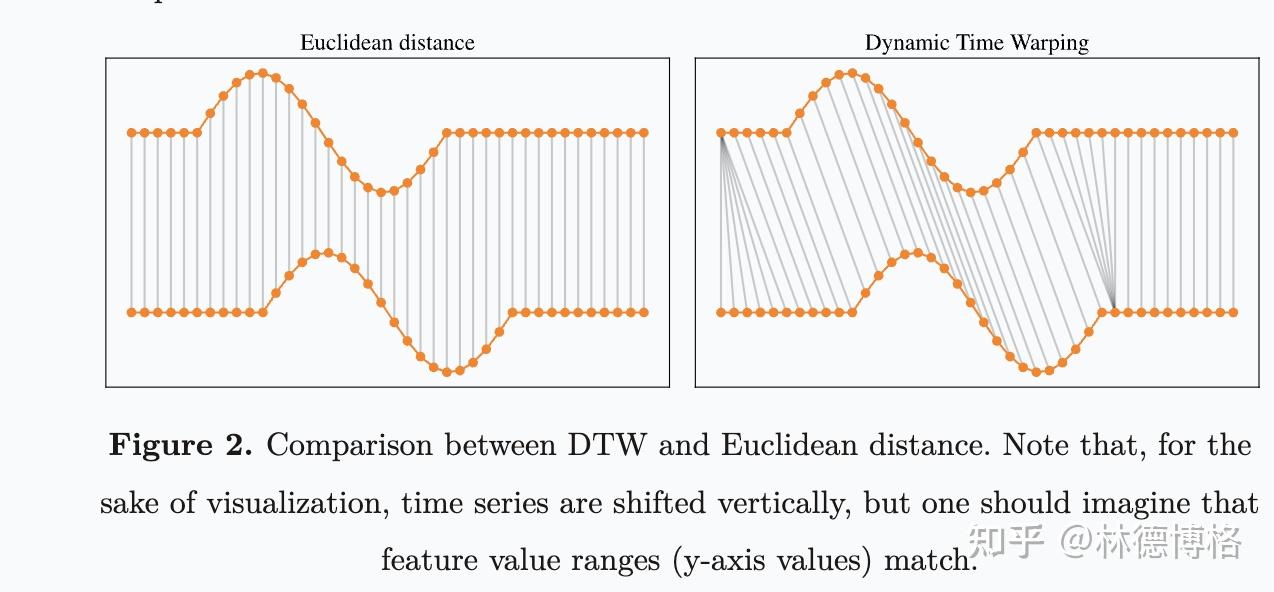
欧几里得距离和DTW距离比较(source: https://rtavenar.github.io/blog/dtw.html)
这一类方法的基本思想是,通过比较时间序列的整体形状来计算相似度。这一类方法包括了大名鼎鼎的Euclidean distance 和 DTW。
主要包括以下方法:
- Euclidean Distance and other
 norms. norms.
- Dynamic Time Warping (DTW)
- LB-Keogh (variant of DTW)
- Spatial Assembling (SpADe)
- Optimal Bijection (OSB)
- DISSIM
2. Edit Based Time Series Similarity Measure

Longest Common Subsequence (source: https://www.enjoyalgorithms.com/blog/longest-common-subsequence )
这一类方法的基本思想是,通过计算“最少需要多少步基本操作来把一段时间序列变成另外一段时间序列”来衡量相似度。举个例子,给定两个序列:ABC,ABD,以及三个基本操作“删除、添加、替换”,我们最少需要一个基本操作“替换”(C替换成D),将ABC编程ABD. 主要包括以下方法:
- Levenshtein
- Weighted Levenshtein
- Edit with Real Penalty (ERP)
- Time Warp Edit Distance (TWED)
- Longest Common SubSeq (LCSS)
- Sequence Weighted Align (Swale)
- Edit Distance on Real(EDR)
- Extended Edit Distance(EED)
- Constraint Continuous Edit(CCED)
3. Feature Based Time Series Similarity Measure
TQuest Distance(source: https://www.dbs.ifi.lmu.de/Publikationen/Papers/paper-edbt06_final.pdf)
这一类方法的基本思想是:首先提取出时间序列的特征,比如说统计学特征(最大值、最小值、均值,方差等),或者是通过FFT提取出Amplitude, Energy, Phase, Damping Ratio, Frequency)等特征,然后直接计算这些特征之间的Eclidean distance 然后再求和。主要包括以下方法(也就是不同的特征提取和比较方法):
- Likelihood
- Autocorrelation
- Vector quantization
- Threshold Queries (TQuest)
- Random Vectors
- Histogram
- WARP
4. Structure Based Time Series Similarity Measure
之前介绍的三种时间序列相似度度量方法适用于短的时间序列,然而对于较长的时间序列(比如说几万个点的时间序列),前面三大类方法很可能会失效。于是,就有了第四类方法。前面三大类方法之所以失效,是因为它们过多关注局部特征(local feature),而忽略了全局特征(Global feature)。而第四类方法的基本思想是:关注全局特征。
这一类方法可以进一步分为两类:基于模型的(model-based distance) 和 基于压缩的(Compression-based distance).
Model-based distance假设时间序列服从某个分布/模型,然后估计模型参数,最后通过比较模型参数之间的差异来反映时间序列的相似度。主要包括以下方法:
- Markov Chain(MC)
- Hidden Markov Models(HMM)
- Auto-Regressive(ARMA)
- Kullback-Leibler
Compression-based distance通过研究两个时间序列在一起压缩的压缩率来反映相似度。直观上,如果两个时间序列比较相似,则它们在一起压缩就比较容易。
- Compression Dissimilarity(CDM)
- Parsing-Based
第三节:现有的时间序列相似度度量方法(Time Series Similarity Measure)总结?
对于绝大部分同学来说,可能只知道Euclidean Distance的存在,更厉害一点的同学也知道DTW,或者还有LCSS. 然后,根据上面的梳理,大家可以看到,现有的时间序列相似度度量十分丰富,那么该如何选呢?这要取决于你的数据类型,以及你应用的领域。大体来说,根据[3],可以给出以下几条建议:
- 如果你的时间序列比较短,并且通过双眼就能感觉出两个时间序列是否相似,那么建议选第一类方法Shape Based Time Series Similarity Measure.
- 如果你的时间序列的类型比较特殊,或者你有关于时间序列的一部分先验知识(比如说时间序列服从模型),那么你可以选择第四类方法Structure Based Time Series Similarity Measure里面的model-based distance.
- 如果你的时间序列比较长,并且你对于时间序列本身一无所知。那么你可以考虑第四类方法Structure Based Time Series Similarity Measure里面的Compression-based distance.
- 如果你什么都不知道的话:如果你的时间序列是等长的,那么你可以用Euclidean Distance,DTW(大众的选择)。特别的,DTW的改进版本FastDTW计算起来也很快; 如果你的时间序列不是等长的,那么建议你选DTW.
- 此外,如果你要发论文,当选择一个时间序列相似度的时候,你需要考虑它是不是一个metric,以及它是否lower bound真实距离(不懂的同学可以直接跳过)。
最后放出一张总结表(感兴趣的同学可以去读原论文[3],找每一个方法的参考文献):
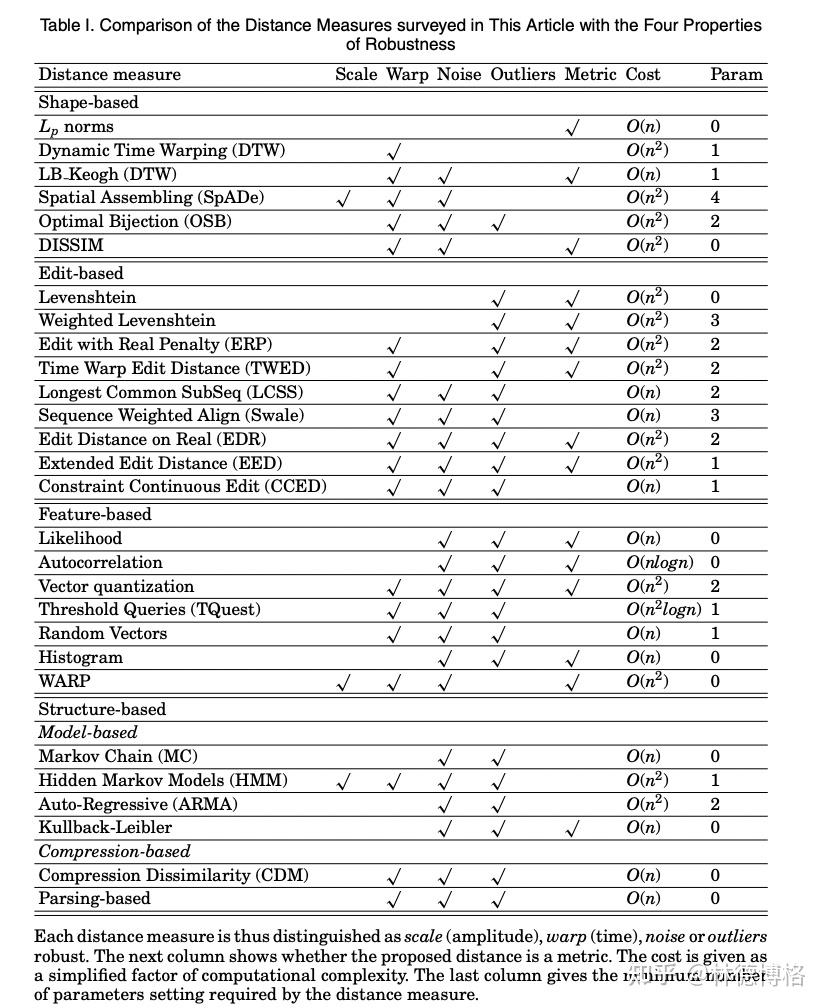
Source: [3]
<hr/>参考文献
[1] [PDF] Comparison of Leaf Recognition by Moments and Fourier Descriptors | Semantic Scholar
[2] Keogh Eamonn
[3] Esling, Philippe, and Carlos Agon. &#34;Time-series data mining.&#34;ACM Computing Surveys (CSUR)45.1 (2012): 1-34. |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-10-12 11:30
发表于 2024-10-12 11:30





