金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|

本文介绍一篇被ICLR2023录用的旨在增强大型预训练语言模型代码生成能力的工作。生成给定编程问题的代码解决方案的任务可以从使用诸如Codex之类的预训练语言模型中受益,这些模型可以生成多种多样的代码样本。然而,这项任务的一个主要挑战是从预训练语言模型生成的多个样本中选择最合适的解决方案。评估代码解决方案的质量和正确性的一种方法是针对一组测试用例运行代码,但手动创建此类测试用例通常费时费力。在这篇论文中,作者提出了一种新颖的方法,称为CodeT,它利用相同的预训练语言模型自动生成代码样本与测试用例,从而减少人力投入,增加测试场景的覆盖范围。CodeT首先使用生成的测试用例执行代码样本,然后同时考虑代码样本与测试用例的一致性以及与其他代码样本的一致性进行排序。作者在四个基准测试集(HumanEval、MBPP、APPS和CodeContests)上进行了全面的实验,使用了五种不同大小和能力的预训练语言模型。实验结果表明,CodeT可以显著提升代码解决方案选择的性能,相较于先前的方法,无论是在不同模型还是不同基准测试集上,都实现了显著的提升。例如,CodeT在HumanEval上的pass@1指标提高到65.8%,这相对于code-davinci-002模型的提升幅度达到18.8%,并且而相对于先前的SOTA结果,提升幅度超过20%。
1. 绪论
尽管代码生成的预训练技术取得了显著进展,但从大型语言模型生成的多个候选方案中选择单个正确解决方案仍然是一个难题。例如,Codex(Chen等,2021)是用于代码生成的最先进的预训练语言模型,它可以在HumanEval基准测试集(Chen等,2021)上达到77.4%的pass@100(如果在给定问题的100个生成解决方案中有一个或多个可以通过相应的测试用例,则表示“pass”),但在pass@1(仅允许使用单个解决方案的正确率)方面仅为33.5%。这种巨大差距限制了代码生成模型的实际实用性,并激发了作者探索如何从多个候选方案中选择正确或最佳解决方案的动机。
一种直接验证解决方案正确性的方法是执行该解决方案并检查是否通过所有相应的测试用例。这种基于执行的方法已被广泛应用于各种与代码相关的任务,例如代码生成(Chen等,2021;Li等,2022b;Shi等,2022)、代码翻译(Roziere等,2021)和程序合成(Chen等,2018;Ellis等,2019)。然而,这种方法在很大程度上依赖于测试用例的质量和数量,而创建和维护测试用例通常是昂贵且耗时的。此外,在像Copilot这样的实际应用中,它是一个辅助开发人员编写代码的代码生成工具,期望用户为每个问题提供测试用例是不现实的。因此,作者提出为任意编程问题自动生成测试用例,并将其用于快速验证任何解决方案。
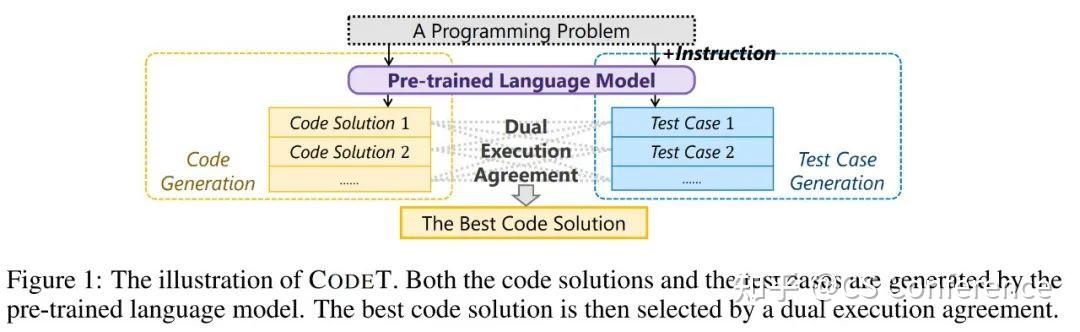
于是作者提出了CodeT:基于代码测试一致性驱动的代码生成方法,如图1所示。首先,作者利用同一预训练语言模型(例如Codex),通过提供详细的提示说明,生成针对每个编程问题的大量测试用例。接下来,作者采用了受经典RANSAC算法(Fischler & Bolles,1981)启发的代码测试一致性方法。作者将每个生成的代码解决方案在每个生成的测试用例上执行,并迭代地找到多组代码解决方案和测试用例配对。每个组,或称为共识集,具有通过相同测试用例的解决方案,表明它们具有相同的功能,即使在实现上不同。作者期望通过更多的测试用例的通过来判断解决方案的正确性,并且具有更多相似解决方案的解决方案,即在同一共识集中的解决方案。因此,作者通过共识集中的测试用例和解决方案的数量对每个共识集进行排名,并从排名最高的共识集中选择最佳解决方案。
论文提出的方法简单高效,因为它不需要任何标记数据或额外的排序器,但它可以实现令人惊讶的卓越性能。作者在五个不同的用于代码生成的预训练语言模型上进行了评估:三个OpenAI Codex模型(Chen等,2021)、InCoder(Fried等,2022)和CodeGen(Nijkamp等,2022),以及四个已建立的代码生成基准测试集:HumanEval(Chen等,2021)、MBPP(Austin等,2021)、APPS(Hendrycks等,2021)和CodeContests(Li等,2022b)。实验结果显示,论文提出的方法能够有效地从多个候选方案中选择正确的解决方案,在零样本情况下显著提高了所有基准测试集上的pass@1得分。例如,CodeT在使用code-davinci-002模型的情况下取得了如下改进:HumanEval(47.0% → 65.8%)、MBPP(58.1% → 67.7%)、APPS Introductory(27.2% → 34.6%)以及CodeContests(0.7% → 2.1%)。此外,当作者将最强大的预训练模型code-davinci-002与CodeT相结合时,可以在很大程度上超越先前的SOTA方法,例如在HumanEval上从42.7%(Inala等,2022)提升至 65.8%。作者还进行了详尽的分析以提供更多见解。
2.方法

代码生成任务的目标是解决一个编程问题:基于上下文c生成代码解决方案x。如图2所示,上下文c包含以代码注释形式呈现的自然语言问题描述,以及包括导入语句和函数头的代码片段。一个代码解决方案是一个解决上下文中描述的编程问题的代码片段。通常使用预训练语言模型M在给定上下文c的基础上对代码解决方案进行采样,表示为X = {x1, x2, …, xN },其中M(c)表示生成的代码解决方案集合。我们的目标是从生成的代码解决方案集合X中选择最佳代码解决方案,其中是最有可能正确解决给定编程问题的解决方案。为此,作者提出了CodeT,希望发挥预训练语言模型M固有的能力。具体来说,作者使用M为编程问题生成测试用例(第2.1节),然后基于代码测试一致性选择最佳代码解决方案(第2.2节)。
2.1测试用例的自动生成除了生成代码解决方案外,我们还需要生成测试用例来评估代码解决方案的正确性。一个测试用例是上下文中定义的函数的输入和期望输出的成对数据。例如,在图2中,该编程问题的一个测试用例是检查是否存在列表中小于阈值的接近元素。为了生成测试用例,作者使用了与生成代码解决方案相同的预训练语言模型M,但在上下文c中添加了一个指令p作为提示,以表明作者希望生成测试用例而不是代码解决方案。如图2所示,指令p包含三个部分:(1)一个“pass”语句作为函数体的占位符,表示不需要为函数生成代码,(2)一个注释“check the correctness of [entry point]”,以阐明生成测试用例的意图,其中“[entry point]”是函数的名称,以及(3)一个“assert”语句来表示开始生成测试用例,指定测试用例的格式为输入-输出对。
然后,作者将拼接后的上下文和指令,即concat(c, p),提供给语言模型M,然后从模型输出中采样得到一组测试用例,表示为Y = {y1, y2, …, yM}。测试用例生成的过程可以表示为Y = M(concat(c, p))。语言模型将尝试通过为函数生成合理的输入-输出对来完成指令。需要注意的是,在生成代码解决方案和测试用例之前,作者已经从上下文c中删除了所有示例输入-输出案例,以避免将真实测试用例暴露给语言模型。
2.2 代码测试的一致性排序在本小节中,作者解释了如何从生成的代码解决方案集合X = {x1, x2,…, xN }中选择最佳代码解决方案,使用生成的测试用例集合Y = {y1, y2,…, yM}作为判断标准。我们可以在测试用例y上执行代码解决方案x,这意味着在y的输入部分上运行由x定义的函数,并将输出与y的输出部分进行比较。如果代码解决方案x能够无错误地执行,并且输出与预期输出匹配,就称代码解决方案x能够通过测试用例y。此外,如果两个代码解决方案xi和xj能够通过集合Y中相同的测试用例,就说它们之间存在功能一致性协议。作者提出的方法基于以下假设:(1)在给定特定编程问题的情况下,代码解决方案和测试用例是从预训练语言模型M中独立随机采样的;(2)不正确的代码解决方案通常多种多样,并且两个不正确的代码解决方案之间具有功能一致性的概率很低。这些假设与经典的RANSAC算法(Fischler & Bolles,1981)相似,RANSAC是一种在嘈杂数据中寻找共识的鲁棒方法。受RANSAC启发,作者提出了CodeT,进行代码测试一致性的计算,这是一个迭代方法,具体如下:
- 首先从所有可能的配对集合D = {(x, y)|x ∈ X, y ∈ Y}中随机选择一对(x, y)。然后,尝试在测试用例y上执行代码解决方案x。如果x能够通过y,就称配对(x, y)为假设内点,因为它在假设上描述了正确的编程问题功能。否则,称(x, y)为异常值,因为它未能描述正确的功能。图3展示了一个简单的编程问题示例,即“返回一个数的平方”。(x1, y1)和(x3, y2)是两个假设的内点,而(x1, y4)和(x3, y1)则是两个异常值。
- 如果(x, y)是假设内点,就从D中收集与此假设内点一致的所有其他配对,形成一个称为共识集的集合S。为了找到与(x, y)一致的配对,首先找出x能够通过的所有测试用例,记为Sy。然后,找出能够通过与x完全相同的测试用例的所有代码解决方案,记为Sx。最后,共识集是由Sx中的代码解决方案和Sy中的测试用例组成的所有配对的集合,即S = {(x, y)|x ∈ Sx, y ∈ Sy}。例如,在图3中,可以从假设的内点(x1, y1)(显示在绿色框中)中得到Sx = {x1, x2},Sy = {y1, y2, y3},并从(x3, y2)(显示在紫色框中)中得到Sx = {x3},Sy = {y2, y3, y4, y5}。
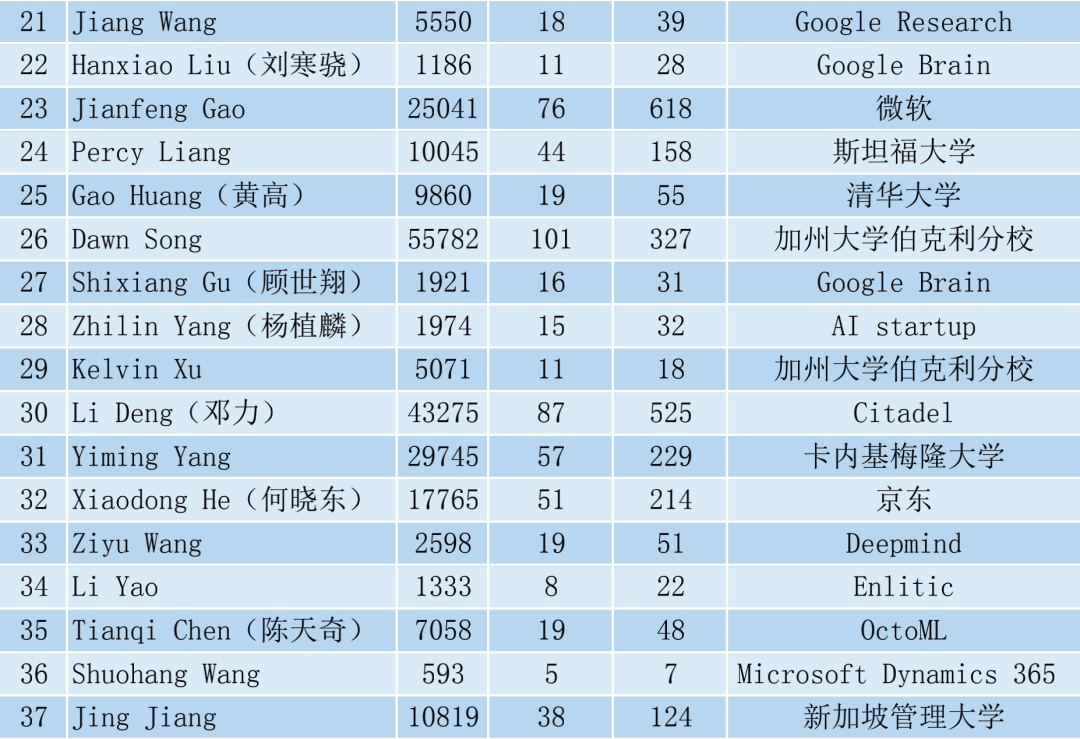
- 将共识集评分为f(S) = |Sx||Sy|,其中|Sx|是Sx中代码解决方案的数量,|Sy|是Sy中测试用例的数量。此得分等于共识集中的配对数量。根据作者的假设,与假设功能一致的配对越多,这个功能越有可能是正确的。根据图3中的示例,假设的内点(x1, y1)和(x3, y2)的共识集得分分别为6和4。

将以上过程重复固定次数,每次生成一个具有得分的共识集。最终,通过从得分最高的共识集中选择任何代码解决方案来获得最佳代码解决方案。如果我们想要获得k个代码解决方案,可以选择具有最高得分的前k个共识集,并从这k个共识集中各选择一个代码解决方案。在实际操作中,当D中的代码解决方案数量不大时,可以通过检查D中的所有可能配对来简化上述方法,而不是从D中采样配对。特别地,对于X中的每个代码解决方案x,将其与Y中的每个测试用例一一运行,并跟踪它通过了哪些测试用例。最终可以将通过相同测试用例的代码解决方案分组在一起,因为它们具有相同的功能。通过这种方式,根据它们的功能将X中的所有代码解决方案分成了不同的组,写为X = {S1x, S2x, …, SKx},其中K是代码解决方案组的数量。每个组Sx都有一组通过的测试用例,将其写为Sy。然后,得到K个共识集,每个共识集的形式为S = {(x, y)|x ∈ Sx, y ∈ Sy}。可以像之前一样通过f(S) = |Sx||Sy|对每个共识集进行评分。这个简化版本有着相同的基本原理,但它一次性找到了所有的共识集,而不需要重复采样配对。
3. 实验设置
模型:本文的实验基于Codex(Chen等,2021)、InCoder(Fried等,2022)和CodeGen(Nijkamp等,2022)。Codex是GPT-3(Brown等,2020)的一个后继模型,能够理解提供的上下文并生成功能完备的程序。作者使用了三个由OpenAI提供不同版本的Codex模型:code-cushman-001、code-davinci-001和code-davinci-002。InCoder是一个统一的生成模型,可以执行从左到右的代码生成和代码填充,而CodeGen是一系列用于进行会话式程序合成的大规模语言模型。作者使用了InCoder 6.7B版本(InCoder 6B)和CodeGen 16B Python单语言版本(CodeGen-Mono-16B)。
评估指标和基准对比方法:作者使用pass@k(包括n个样本)作为性能评估指标,并利用地面真实测试用例来确定代码解决方案的功能正确性。对于每个问题,首先采样n个代码解决方案,然后选择其中的k个进行评估。如果其中任何一个通过了所有真实的测试用例,问题就被认为是已解决。然后pass@k是已解决问题的百分比。作者使用无偏的pass@k定义的基准对比方法(Chen等,2021),即从n个样本中随机选择k个解决方案。CodeT则使用基于代码测试一致性从n个样本中选择k个解决方案,如2.2中所述。此外,作者还包括了Li等人(2022b)使用的一种聚类方法进行比较,称为AlphaCode-C。作者复现的方法是使用CodeT生成的测试输入,在测试输入上运行解决方案,通过测试输出对解决方案进行分组,并按照大小对聚类进行排名。
基准测试数据集:本文在零样本设置下对四个公共代码生成基准测试集进行实验。基准测试集的统计数据如表1所示。(1)HumanEval(Chen等,2021)包含手写的Python编程问题。原始上下文包括示例输入-输出案例,在本文的实验中被移除,以避免暴露真实测试用例。(2)MBPP(Austin等,2021)(经过清洗的版本)包含众包编写的Python编程问题,同样按照HumanEval的方式构建了其上下文。(3)APPS(Hendrycks等,2021)包含从开源编码网站收集的编码问题,具有不同的难度级别。(4)CodeContests(Li等,2022b)包括从Codeforces平台爬取的竞技编程问题。为了进行零样本推理,作者按照以下方式构建了APPS和CodeContests的上下文:原始问题描述被视为注释,其中移除了输入-输出示例,并在注释之后放置了一个简单的函数头“def solution(stdin : str) → str :”,以适应输入/输出数据格式。
4.实验结果
4.1 HumanEval与MBPP实验结果
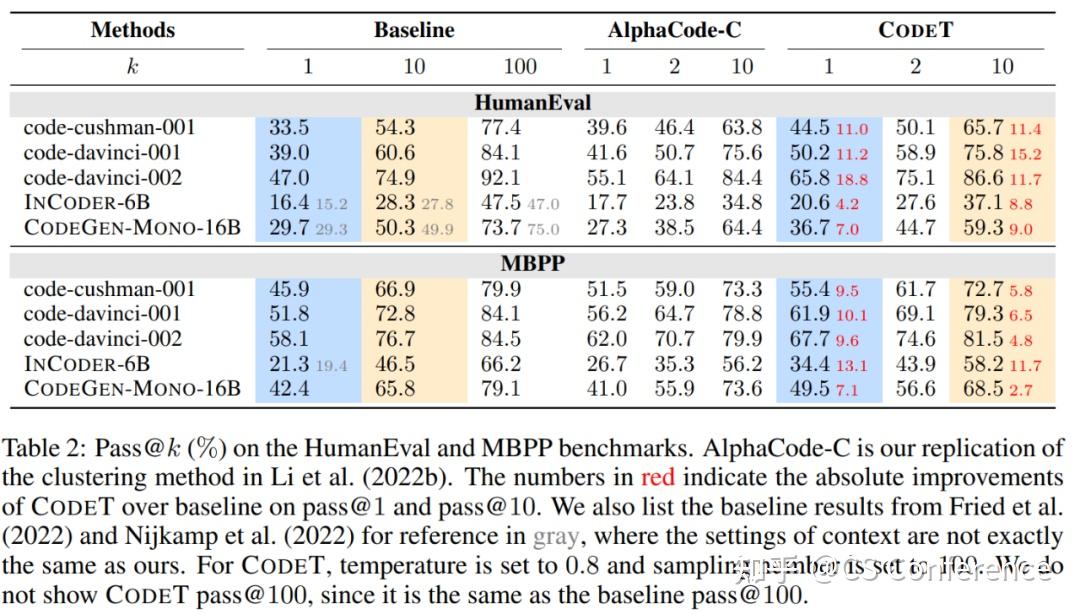
各种模型在HumanEval和MBPP基准测试上的实验结果总结在表2中。如果将基准列中的pass@100与pass@1进行比较,可以清楚地看到前者明显优于后者,表明CodeT有潜力从生成的100个样本中选择最佳的代码解决方案。
对于三个Codex模型,当将CodeT列与基准列进行比较时,CodeT的pass@1相对于基准pass@1实现了约10%的绝对提升。提升效果在HumanEval基准测试中始终在10%以上。令人惊讶的是,即使对于最强的基准模型code-davinci-002,提升效果也达到了18.8%,将pass@1提升到了65.8%,相对于先前报道的最佳结果(Inala等,2022)实现了20%以上的绝对提升。作者将这个更大的提升归因于code-davinci-002生成的测试用例质量更高,CodeT在MBPP基准测试中也取得了出色的表现,尽管提升幅度略低于HumanEval。以code-davinci-002为例,pass@1提高了9.6%。作者还报告了CodeT的pass@2和pass@10,以进一步展示其优越性。CodeT的pass@2结果接近基准的pass@10结果。与此同时,在HumanEval基准测试中,pass@10的提升效果也始终在10%以上。
InCoder-6B和CodeGen-Mono-16B的实验结果进一步验证了CodeT的有效性。显然,CodeT可以显著提升pass@1,绝对提升幅度在4.2%到13.1%之间。InCoder-6B在MBPP基准测试上取得了最大的提升效果,提升了13.1%。与Codex的实验结果类似,pass@2的结果接近基准的pass@10。所有结果表明,CodeT可以持续提高各种预训练语言模型的性能。
对于AlphaCode-C,无论使用不同模型在哪个基准测试上,它都始终劣于CodeT,这表明作者提出的代码测试一致性考虑了测试用例信息,具有优越性。
4.2 APPS与CodeContests实验结果
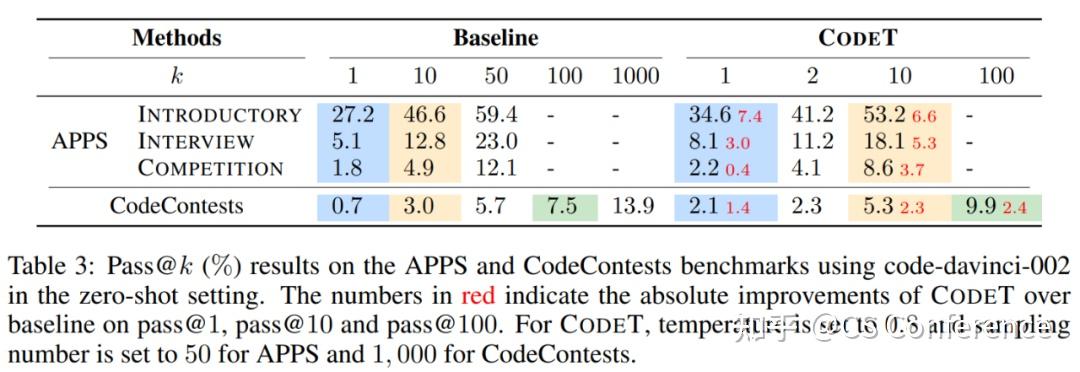
作者还在两个更具挑战性的基准测试上进行了实验,即APPS和CodeContests。作者构建了APPS和CodeContests的零样本版本,以与HumanEval和MBPP设置相一致,通过移除问题描述中的示例输入-输出案例。作者使用code-davinci-002进行代码解决方案和测试用例的生成。对于APPS,将采样数量设置为50,以节省计算成本,共有5,000个测试问题。对于CodeContests,参考Li等(2022b),将采样数量设置为1,000,以解决特别难的问题。从表3总结的结果中,我们可以清楚地观察到CodeT在这两个基准测试上的持续性能提升。在APPS的Introductory问题中,绝对的pass@1提升为7.4%,而对于APPS和CodeContest中的Competition问题,提升并不显著,表明它们的难度较大。
5. 结论
该论文提出了一种简单但有效的方法,称为CodeT,利用预训练语言模型来生成代码解决方案和测试用例。CodeT使用测试用例执行代码解决方案,并基于代码测试一致性选择最佳解决方案。作者展示了基于测试用例和其他解决方案的一致性对CodeT的成功至关重要,对生成的测试用例的质量及其对CodeT的影响进行了全面分析,并通过案例研究提供了更多的见解。实验结果清楚地证明了CodeT的优越性,在各种基准测试上显著提高了pass@1数值。虽然CodeT仍然面临挑战,即只适用于可执行代码生成,并且引入了额外的计算成本用于测试用例生成。在未来的工作中,作者会探索解决这些挑战的方法,并改进CodeT以解决更难的编程问题。
相关链接:
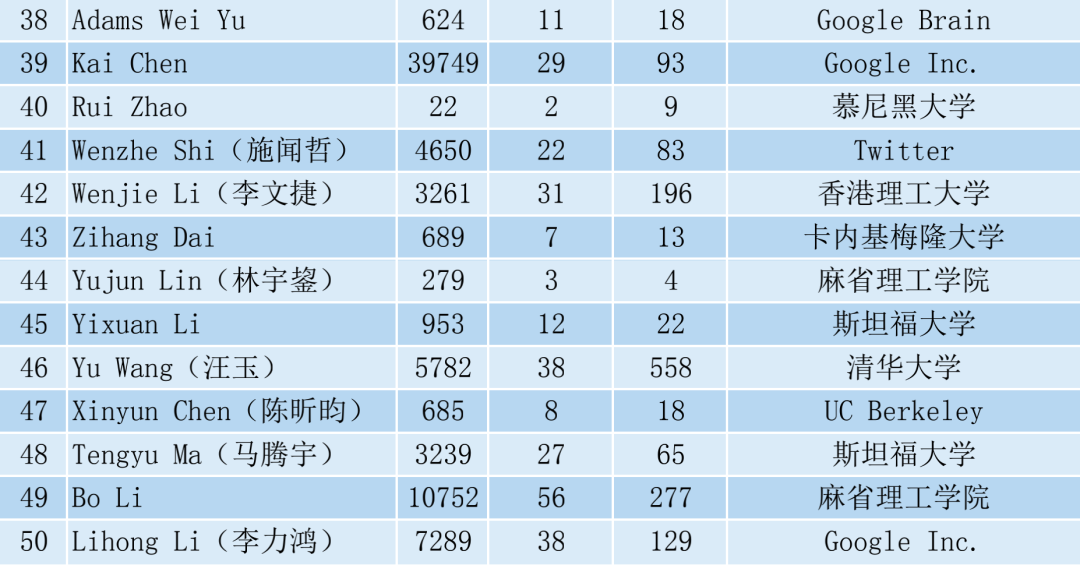
Humaneval数据集链接:
https://github.com/openai/human-eval
论文链接:
https://openreview.net/pdf?id=ktrw68Cmu9c
代码链接:
https://github.com/microsoft/CodeT |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-9-29 10:16
发表于 2024-9-29 10:16


 发表于 2024-9-29 10:16
发表于 2024-9-29 10:16






 发表于 2024-9-29 10:18
发表于 2024-9-29 10:18



