本文来自于《The Cognitive Neurosciences 6th》。上篇文章 认知神经科学笔记(1.1):方法进展之表征模型与特征谬误 介绍了表征模型以及其在fMRI中的应用,而这篇文章来源于Methods Advances部分的第二篇:An Introduction to Time-Resolved Decoding Analysis for M/EEG(arxiv版本链接),主要是介绍MVPA方法在M/EEG中的基本应用。
2 M/EEG时间分辨解码
by Thomas A. Carlson, Tijl Grootswagers, and Amanda K. Robinson
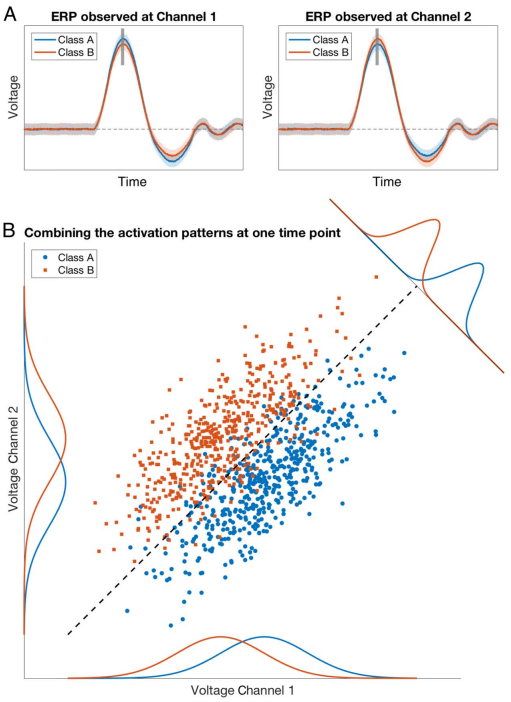
我们的大脑一直在不断地处理信息和做出决策,同时与外界进行互动来完成各种任务,这些复杂的认知过程需要大量神经元之间的交流。基于脑电图(EEG)和脑磁图(MEG)的非侵入式神经成像方法使我们能够测量毫秒精度的神经活动,从而研究认知的时间过程。然而多传感器的数据是高维的,这使得从噪声中解析信号变得更加困难。多变量模式分析(multivariate pattern analysis,MVPA方法)为理解高维M/EEG数据提供了巨大的潜力——MVPA方法可以用来区分不同的条件以及各种神经活动的时间过程,甚至能够了解不同认知过程之间的顺序。在本章中,我们讨论了对M/EEG信号进行解码的方法及其局限性,目的是提供一个方便上手的简易教程。 MVPA的历史:MVPA方法从二十年前开始应用于fMRI研究,展现出强大的认知解码能力,并且能够定位认知过程所在的具体脑区。如今,对M/EEG信号使用MVPA能够在神经活动的时间过程上提供互补的信息,因而在认知神经科学中逐渐流行起来。有趣的是,使用电生理方法进行认知解码的研究其实比fMRI研究还要早上数十年——Vidal在1973年就提出”脑电信号能否与机器进行通讯以控制假体或者其他外部设备?“这一具有挑战性的问题。但是这一问题长期以来都是在工程背景下进行的研究,这些领域的研究者们更关心认知解码的实际应用,例如脑机接口(BCI)、测谎、精神疾病诊断等等,因而更重视性能而不是解释。但对于认知神经科学来说,我们更加希望阐明认知过程背后的神经机制。 时间分辨解码(time-resolved decoding):MVPA可以应用于多种M/EEG数据,包括时间序列、频域分析、小波分解、功能连接等等。本文重点介绍了M/EEG的时间分辨解码,也就是对时间序列的每一个时间点进行解码,但是许多原则也适用于其他数据(下文的MVPA都特指时间分辨解码)。MVPA和EEG中经典的ERP研究范式非常相似,都是给被试呈现不同条件的刺激,然后试图找到不同条件下神经信号之间的差异。不同的是ERP采用的是单变量的方法,而MVPA采用了跨通道的方法因而更加敏感。例如下图中两种条件在通道上的平均活动都是没有显著差异的,但是用MVPA就可以找到不同的模式。需要注意的是,MVPA只是探究信号在不同条件下是否分离的一种测量方法,但是如果想要解决这些信息是什么以及如何在大脑中表示,则需要所在研究领域的具体理论以及对应的研究范式。
图片来源于作者的另一篇综述(Grootswagers et al,2017)
2.1 基础概念 The Basics of Time-Resolved Decoding Analysis for M/EEG
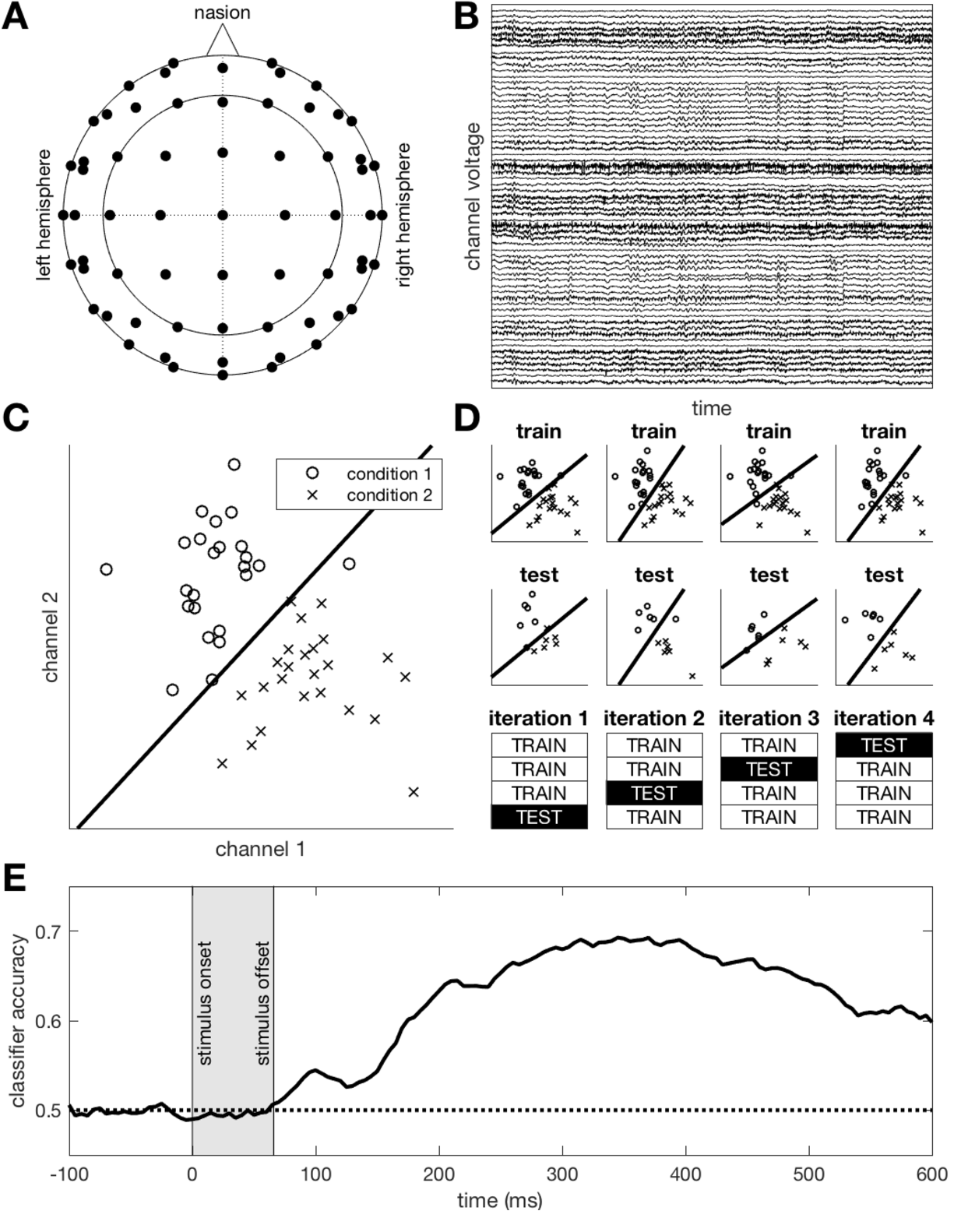
线性分类器与非线性分类器:在解码时,我们更倾向于线性分类器,例如支持向量机或者逻辑回归。尽管非线性分类器能够拟合更复杂的决策边界,但在实际的认知神经科学研究中它们的表现通常与线性分类器差不多甚至更差(Misaki et al., 2010)。这是因为非线性分类器更灵活的边界可能会导致过拟合从而降低泛化性,并且认知神经科学中的数据量本就有限。此外,非线性分类器的结果很难解释。正如前文提到的,在认知神经科学中使用MVPA的目的在于理解大脑而不是提升解码性能。因此除非有充分的理由,线性分类器是在M/EEG中使用MVPA的首选方法。 线性分类器在解释性上有两个优势:(1)对于fMRI来说,线性分类器是一种符合生物学的“read-out”方式。具体来说,一个下游神经元也可以像线性分类器那样接收和使用这些上游的信息,因此线性分类器可以看作一种对于神经计算的模拟。不过对于M/EEG来说情况有所不同,单个EEG通道记录了来自不同脑区的数千个神经元的活动,整个EEG脑电帽可以访问皮层上的大多数神经元,但是单个神经元不可能接收所有的这些信息。(2)线性分类器的权重可以进行可视化,从而了解与条件相关的信息的来源。例如,研究人脸的fMRI实验可能会显示梭状回面部识别区域(FFA)具有很高的权重。对于M/EEG,我们也可以将分类器权重投影回传感器的地形图。 如何选择线性分类器:作者在之前的研究中比较了五种分类器在解码MEG数据时的表现,这些分类器包括线性判别分析(LDA),高斯朴素贝叶斯(GNB),支持向量机(SVM),Spearman相关以及Pearson相关。结果发现SVM、LDA和GNB表现最好,说明这些都是M/EEG解码研究的不错选择,可以在数据分析时进行尝试。 定位可解码的信息源
在认知神经科学中,研究者家对神经加工的空间和时间特性都感兴趣,但是对于M/EEG来说了解神经活动的空间信息是一个巨大的挑战。在M/EEG的解码研究中这一挑战更加艰巨因为我们同时采用了全脑的信号,不过我们也有一些解决方案。首先我们需要区分分辨率(resolution)和空间精度(spatial precision)这两个概念。分辨率指的是在空间中分辨两个点的能力,研究表明MVPA可以探测到宽度仅为一毫米的初级视觉皮层(V1)功能柱的激活模式(Cichy,Ramirez,& Pantazis,2015;Wardle et al.,2016)。这些结果说明了MVPA对激活模式的细微空间差异也具有不错的敏感性,但是我们依旧无法在皮层上很好地定位这些信息的精确空间位置(即较低的空间精度)。
目前来说大致有三种可以用MVPA来定位信息源的方法:
权重投影:前文提到线性分类器能够返回每个传感器的权重,其中传感器的包含条件相关的信息量越大,权重就越高,因此我们可以直接在地形图上画出这些权重。但是在解释这些地形图时,我们需要考虑信息的定义——除了分配权重来区分条件,分类器还使用一些通道来抑制噪声。所以在使用权重投影解释信息源时,我们只能考虑反映条件之间差异的权重(Haufe et al.,2014)。
前两种方法存在一些不足,主要原因是因为某一信息源的脑活动会传到源上方的传感器之外造成信息丢失,并且附近的脑活动也会传到该源上方的传感器造成信息泄漏,这些原因本质上是因为从M/EEG中还原大脑信号是一个困难的逆问题。尽管如此,这些方法能够提供大致上的定位,并且在某些情况下例如比较左右半脑的偏侧化时可能有用。并且,我们还可以使用源定位(source localization)方法,例如最小范数估计(MNE)和波束形成(beamformer)。这些源定位方法可以将传感器的信号映射到大脑每个体素上,并且保留了时间精度,以便在ROI中构建多元时间序列,从而进行解码分析。我们还可以使用被试的解剖像(T1)和功能像(fMRI)来更精确地定义ROI,以提高源定位的质量。但是这些更复杂的定位方法仍无法完全解决信息丢失和泄漏的问题(Brookes,Woolrich,& Barnes,2012;Hipp et al.,2012)。 进行组水平的统计检验
上述的方法能够帮助我们对个体进行MVPA分析,但是我们还需要在组水平上进行检验。具体来说,我们需要知道在采样的被试中,分类器的效果是否高于随机水平:(1)我们有很多方法,包括参数检验方法(例如t检验)或非参数检验方法(例如Wilcoxon符号秩检验或置换检验)来检验分类器的准确性。(2)此外,由于这些检验是在每个时间点上进行的,所以我们还需要进行多重比较校正,例如Bonferroni校正、FDR校正以及基于聚类的校正(Smith & Nichols, 2009;Stelzer,Chen,& Turner,2013)。需要注意的是,研究者们对检验方法和多重比较校正并没有一个共识,因此我们需要根据研究问题来选择不同的方法。这一部分属于M/EEG数据分析的基础知识,可以参考Mike X Cohen的经典教程《Analyzing Neural Time Series Data》或者这些文献(Allefeld,Gorgen,& Haynes,2016;Hebart & Baker, 2017)。
2.3 进阶方法之表征动力学 Advanced Methods for M/EEG Decoding: Representational Dynamics
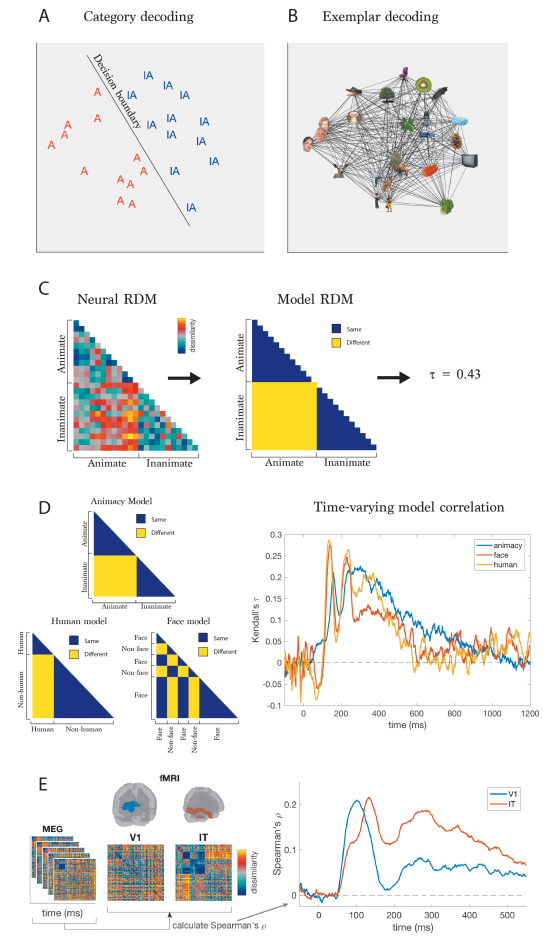
基于实例的解码方法(examplar decoding):除了像上述那样对几种条件进行分类解码,我们还可以通过具体实例来研究大脑表示信息的结构。以Carlson et al.(2013)的研究为例,实验收集了被试看到24个物体时的MEG数据,这24个物体包括12个有生命体和12个无生命体。我们可以基于有/无生命两个类别像刚刚讲的那样对信号进行解码,发现MEG信号中确实可以分辨两种条件(图A)。我们也可以对每两个物体都进行一次解码,然后用解码的准确率作为这两个物体之间的距离(准确率越高距离越远,见图B)。
M/EEG解码方法为认知神经科学提供了一套强大的工具,让我们能够以毫秒级的分辨率揭示大脑的动态加工过程。这一章比较基础地介绍了在M/EEG数据中进行解码的方法,更多内容可以看作者的另一篇综述(Grootswagers,Wardle,& Carlson,2017),补充了通道降维,试次选择,跨时域解码等方法。从实际操作来说,上述的分析方法已被纳入各种MVPA工具箱,包括MNE-python,FieldTrip,PyMVPA,ADAM,DDTBOX,CoSMoMVPA,NeuroRA等等,并且研究者们也在努力提出一些标准化的分析流程以供初学者方便上手(FLUX: a pipeline for MEG analysis)。
另外,上篇文章讲的是表征模型(也可以理解为编码模型),这篇文章讲的是解码模型,不过两者又都提到了RSA方法,容易造成一些混淆。在下一章,我们会深入探讨关于编码模型和解码模型的整个框架。

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-9-19 20:21
发表于 2024-9-19 20:21