金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
2019年底把申请毕设什么的都忙完之后总算有点时间看点论文写写代码了(菜鸡的哭泣(;´༎ຶД༎ຶ`),最近看了一些graph embedding的内容有了一点想法想记录下来。由于能力所限,知识和想法上的错误还请读者们指出讨论。
<hr/>Introduction
分子机器学习(molecular machine learning)中最重要的一步就是获得分子 embedding。更好的embedding自然意味着更好的机器学习效果。最近看到的几个有意思的无监督学习方法在分子的 substructure 与NLP的 word embedding 之间建立了一种对应关系,使得NLP中用于做 embedding 的方法可以迁移运用到分子 embedding 中。本文将主要围绕ECFP,mol2vec 和 graph2vec 这三个算法展开对分子机器学习中子结构embedding的讨论。其中ECFP通过直接数子结构得到的embedding缺乏子结构之间的关联性,而mol2vec利用word2vec将同一个化合物中子结构的关系加进了embedding,graph2vec则进一步将这种关系深入到更局部的分子拓扑结构上。
ECFP:基于子结构的传统的分子指纹
Extended Connectivity Fingerprint(ECFP)是一种能表示化合物内部结构的分子指纹,常用于QSPR-QSAR,在近几年的机器学习中也常常作为 baseline model/benchmark 与新方法的效果进行对比。ECFP首先通过搜索算法(如Morgan Algorithm)搜索所有化合物中所有给定步长的子结构(substructure),通过哈希后得到每个子结构的哈希值并进而形成的对应指纹。例如某个10种分子的化合物集一共有100个步长为2的子结构,最终对每个分子得到一个形如1001010...11011的一百维one hot encoding vector即为其ECFP,开头的1001就意味着这个分子中含有第一个子结构和第四个子结构,以此类推。ECFP还可以扩展出ECFC,即把原来向量中0/1bit作为有/无的信息直接换成一个int代表其中含有几个这样的子结构。得到这个指纹后就可以在后面搭个机器学习模型进行预测了。
回到这个算法的重点,即子结构的定义。不同的分子指纹一般区别于不同的子结构。例如MACCS/PubChem 使用的子结构是预定的官能团/化学键/化学结构等,也就是说它给出的指纹只关心化合物中是否存在我们想找的一些子结构[1]。基于拓扑或路径的指纹,例如ECFP等则是在不同的化合物集上计算这个集合中能找到的所有子结构。下图中画出了一些我在使用的时候找到的子结构示意图(步长为2)。
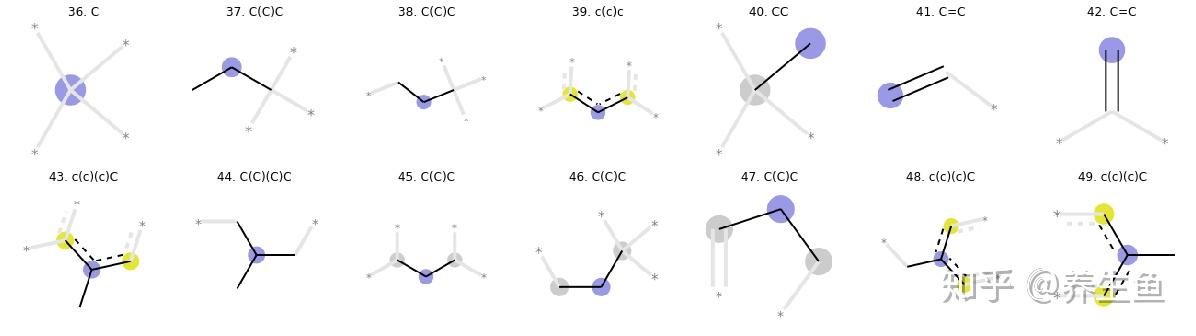
一些ECFP子结构示意图
需要注意的是,ECFP中的子结构由中心分子和步长内的分子组成,也就是说对于同一个“子结构”,如果起始的搜索中心分子不同也视为不同的子结构。其他的算法中也有不看中心原子或者不同的子结构定义的,例如FCFP等。可以说,在分子指纹中,不同子结构的定义就框定了这一指纹的信息量和适用范围。
mol2vec:子结构作为分子的 building block
mol2vec 算法将 ECFP 更进一步,在子结构上直接运用了 word2vec[2]。算法思想在NLP和分子之间搭建了一种对应关系,将子结构视为词语,将每一个化合物视为一个sentence,这样一来直接使用 word2vec 获得的词向量就是每个子结构的embedding。为了获得分子embdding,将一个分子中所能找到的所有子结构加和平均即得到一个分子的embedding。算法的具体步骤事实上也很简单,在得到每个分子的子结构(到这里是one hot encoding)后通过打包组成sentences,然后调调相关参数喂给 word2vec 模型就能用了。当然具体怎么实现化合物中的 CBOW/skip-gram 的方法,以及作者设计的对于蛋白质的特殊 prot2vec 等具体内容就不再展开,感兴趣的读者可以去看原文。不熟悉 word2vec 的化学背景读者可以先学习一下词向量相关的知识。
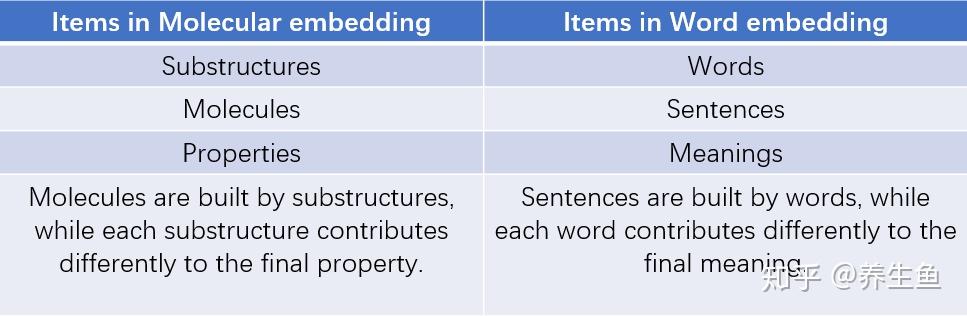
分子机器学习embedding和NLP词向量对应点
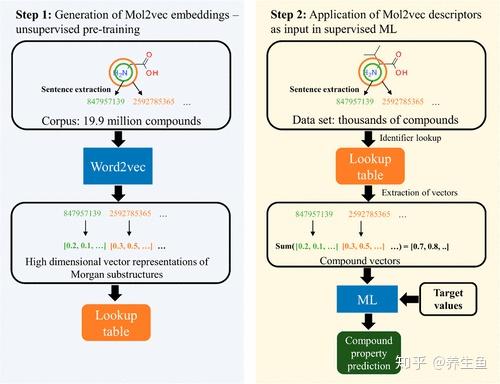
mol2vec算法流程[2]
相比于ECFP,这个算法我认为有以下几个优点:
- 稠密embedding比原来ECFP的稀疏指纹降维了:虽然ECFP不像纯的one-hot encoding那么稀疏,但是在一个巨大的训练集上维度也是爆炸的,一般都取最常见的一部分作为实际输入,降维后操作容易些。
- 体现了子结构之间的相关性:事实上就是word2vec的优势。因为训练中会根据分子中部分的子结构预测部分的分子结构,对于ECFP来说增加了不少分子内部的结构信息。
- 非监督性:由于分子机器学习中,所给的测试集在训练集以外的情况非常常见(药物设计/未知物质性质预测),因此分子embedding的泛化能力非常重要。mol2vec算法是非监督的,这意味着 embedding 和性质预测可以分成两个不同的部分来做。如果我们已有的数据只是想要预测的所有分子中的一小部分,在大分子集上做mol2vec可能能获得更好的效果。我在测试这个算法的时候选择了几个不同大小的化合物集做预测,目前的结果发现在更大的分子集上做mol2vec再在小的有数据的上面做性质预测效果似乎会好不少。
而这个算法值得讨论的地方也有:
- sentence embedding:在从子结构得到分子embedding的过程中实际上就是从word embedding得到sentence embedding的过程。mol2vec算法中直接用了加和平均,会损失部分信息。可能需要用其他 sentence embedding 的方法来获得更好的效果。这一步骤和graph embedding中readout部分事实上也是类似的。这一点会在后面讲graph2vec的时候提到,也可以看我专栏之前讲图网络的文章。
- 子结构是无序的:这大概是子结构和词语之间最大的不同。句子中的词语是有序的,但分子里的子结构是无序的。因此一些基于语序的内容不能直接套用,例如seq2seq或者一些memory network把词向量一个个输进去获得sentence embedding的方法。
总之,mol2vec算法将基于子结构的 embedding 向前更推进了一步,但子结构还是一开始那个子结构。在下面的算法中我们会看到在产生子结构上也可以进行操作。
Graph2vec:加一点子结构之间的联系会不会更好
近几年图网络(Graph Neural Network)非常流行,在我之前的文章中也有一篇简要介绍图网络在分子机器学习中的应用[3]。与推荐系统中的一些问题不同的是,图网络在机器学习中主要用于获得分子的graph embedding进而进行预测,因此需要的是获得graph embedding的算法[4]。
graph2vec 是基于图的子图进而得到graph embedding的算法[5],而这里的子图实际上就是一种子结构。算法过程类比了 word2vec 以及 doc2vec,把化合物中的子结构作为基础 embedding 单元进而得到最终分子的 embedding。与mol2vec不同的是,mol2vec中的子结构是一次搜索后定死的,而graph2vec中的子结构会通过相邻节点的子结构更新其neighbourhood的信息。换言之,mol2vec中的子结构只是个指定步长一次搜索后的哈希值(lower order substructure),而graph2vec中的子结构是图中的真正的结构(higher order substructure)。(虚假的子结构/真正的子结构.jpg)

subgraph的获得过程,即WL relabeling process。在迭代中邻近节点的信息被不断聚合,最终的子结构事实上比一次性的步长搜索更有代表性。[5]
因为这一方法事实上还是word2vec(doc2vec无非是word2vec的升级版),所以首先要准备语料库。在graph2vec中,语料库的word是subgraph,而sentence/document是整个graph。子图的产生使用了 Weisfeiler-Lehman relabeling process。这一算法起初用于检测两个图是否同构,但也可用于聚合相邻节点的信息。在每一步迭代中,这个算法聚合自身和领域节点的所有node embedding,并将hash后新的值得到该节点新的node embedding(具体算法可参阅其他文献,不详细展开[6])。由此得到的 subgraph 即认为是聚合了相邻乃至整个 graph 的结构信息,也可以简单地认为这种subgraph是包含了邻近关系的子结构。训练时采用doc2vec算法来同时得到word2vec以及document embedding。在doc2vec 的PV-DM方法中,每一次的 word2vec训练都要拼接一个 document embedding,用上下文以及这个document embedding 进行预测并训练。即在训练中,不同文本的word embedding共享,document embedding不共享,但每次都根据特定文本接一个特定的document embedding。详细算法介绍可参考“Distributed representations of sentences and documents”[7]。总之,这一步在训练word2vec中的word embedding(事实上是subgraph embedding)的同时训练出了doc2vec中的document embedding(事实上是graph embedding)。准备好上面的语料后,训练过程直接喂到doc2vec模型上就好。
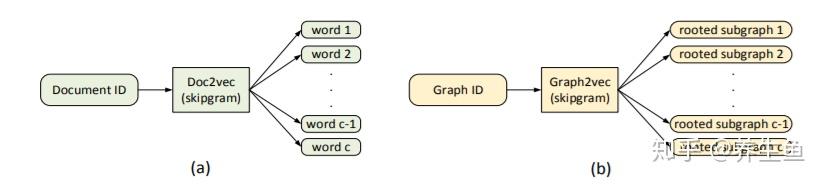
doc2vec与graph2vec的类比[5]
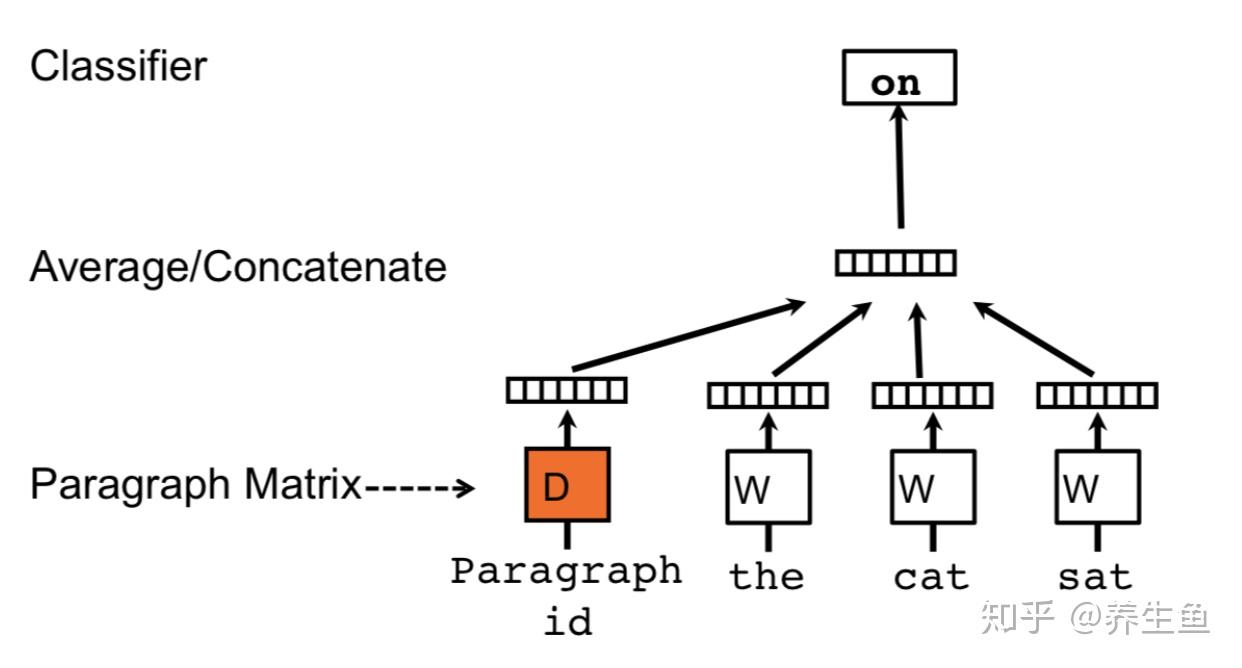
word2vec中PV-DM方法的示意图。注意paragraph id被加入到常规的word2vec训练中。不同paragraph之间的word embedding依然共享。[7]
接下来简要对比图卷积网络和graph2vec的异同点。我在之前的文章中提到,获得graph embedding 一般需要两个步骤:graph convolution layer 和 readout layer[3]。在图卷积网络中(Graph Convolutional Network),图卷积层会逐渐传播节点信息,最终在每个节点上得到有意义的 node embedding,进而通过 readout 获得graph embedding。而相比于graph2vec算法:
- 从卷积层来看:为了得到比较好的node embedding,两者自然都要聚合相邻节点的信息,不过一个是graph convolutional layer,一个是WL relabeling process。也有一种说法说WL test是GNN性能的上限[8]。
- 从readout算法来看:doc2vec自然比部分暴力加和的readout要好一些,具体情况似乎还要具体分析。
- 从目标函数来看:由于GCN常常是监督学习,怎么传播节点信息,图卷积层的参数就由这一监督学习的目标所决定。而graph2vec是类比word2vec的非监督学习的方法,目标函数是提高相邻节点的预测率而非直接得到最终的性质预测值。
garph2vec运用的仍然是subgraph与word之间的类比,与mol2vec相比,主要把子结构的方法变得更高级了一些。这使得它可以获得更能体现分子结构的子结构特征,并且可以体现分子中局部的结构信息,这都是mol2vec做不到的。
Discussion
本文主要讨论了ECFP,mol2vec 和 graph2vec 三种算法,依次从单纯的子结构,子结构之间的联系,子结构周围的子结构对embedding方法进行了一定程度的提升。值得注意的是本文中的几个方法都是非监督学习,而事实上图网络或是自编码器都可以进行监督学习同时学习分子embedding和性质预测。同时进行性质预测的监督学习还会起到规范相关化合物空间的作用,具体内容可以参考我之前写的文章或参考相关论文[9]。相比于直接从化合物表达式暴力训练和从化合物各个原子空间坐标来训练embedding的方法,我认为子结构embedding是一个效率和效果都不错的出发点,与NLP中各种算法的对应关系也很有启发。
参考
- ^分子指纹简介 http://blog.molcalx.com.cn/2019/01/29/fingerprint.html
- ^Jaeger S, Fulle S, Turk S. Mol2vec: unsupervised machine learning approach with chemical intuition[J]. Journal of chemical information and modeling, 2018, 58(1): 27-35. https://pubs.acs.org/doi/abs/10.1021/acs.jcim.7b00616
- ^ab论文笔记:图网络和分子性质预测 https://zhuanlan.zhihu.com/p/53355626
- ^Goyal P, Ferrara E. Graph embedding techniques, applications, and performance: A survey[J]. Knowledge-Based Systems, 2018, 151: 78-94. https://www.sciencedirect.com/science/article/pii/S0950705118301540
- ^Narayanan A, Chandramohan M, Venkatesan R, et al. graph2vec: Learning distributed representations of graphs[J]. arXiv preprint arXiv:1707.05005, 2017. https://arxiv.org/pdf/1707.05005.pdf
- ^WL test和GNN https://zhuanlan.zhihu.com/p/66589334
- ^Distributed representations of sentences and documents https://blog.acolyer.org/2016/06/01/distributed-representations-of-sentences-and-documents/
- ^Xu K, Hu W, Leskovec J, et al. How powerful are graph neural networks?[J]. arXiv preprint arXiv:1810.00826, 2018. https://arxiv.org/abs/1810.00826
- ^论文笔记:基于SMILES的连续化合物空间 https://zhuanlan.zhihu.com/p/42318383
原文地址:https://zhuanlan.zhihu.com/p/101562880 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-1-19 21:53
发表于 2025-1-19 21:53



