金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
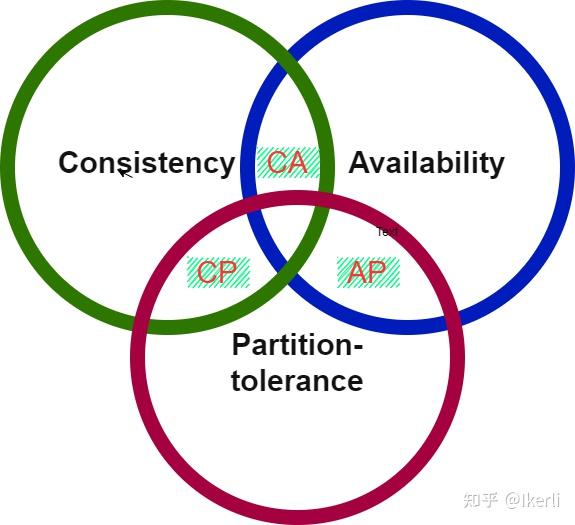
CAP定理:指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可同时获得。
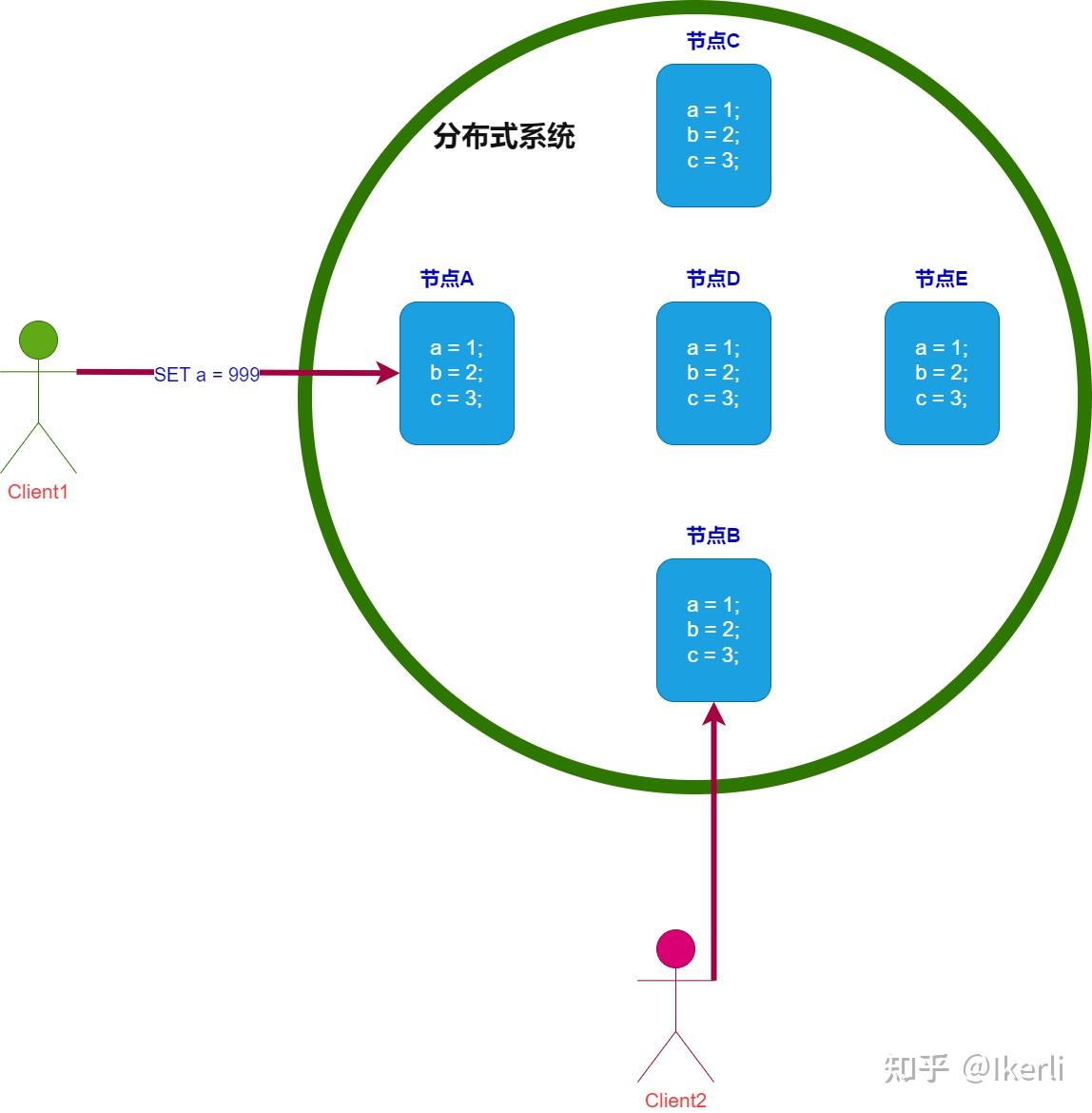
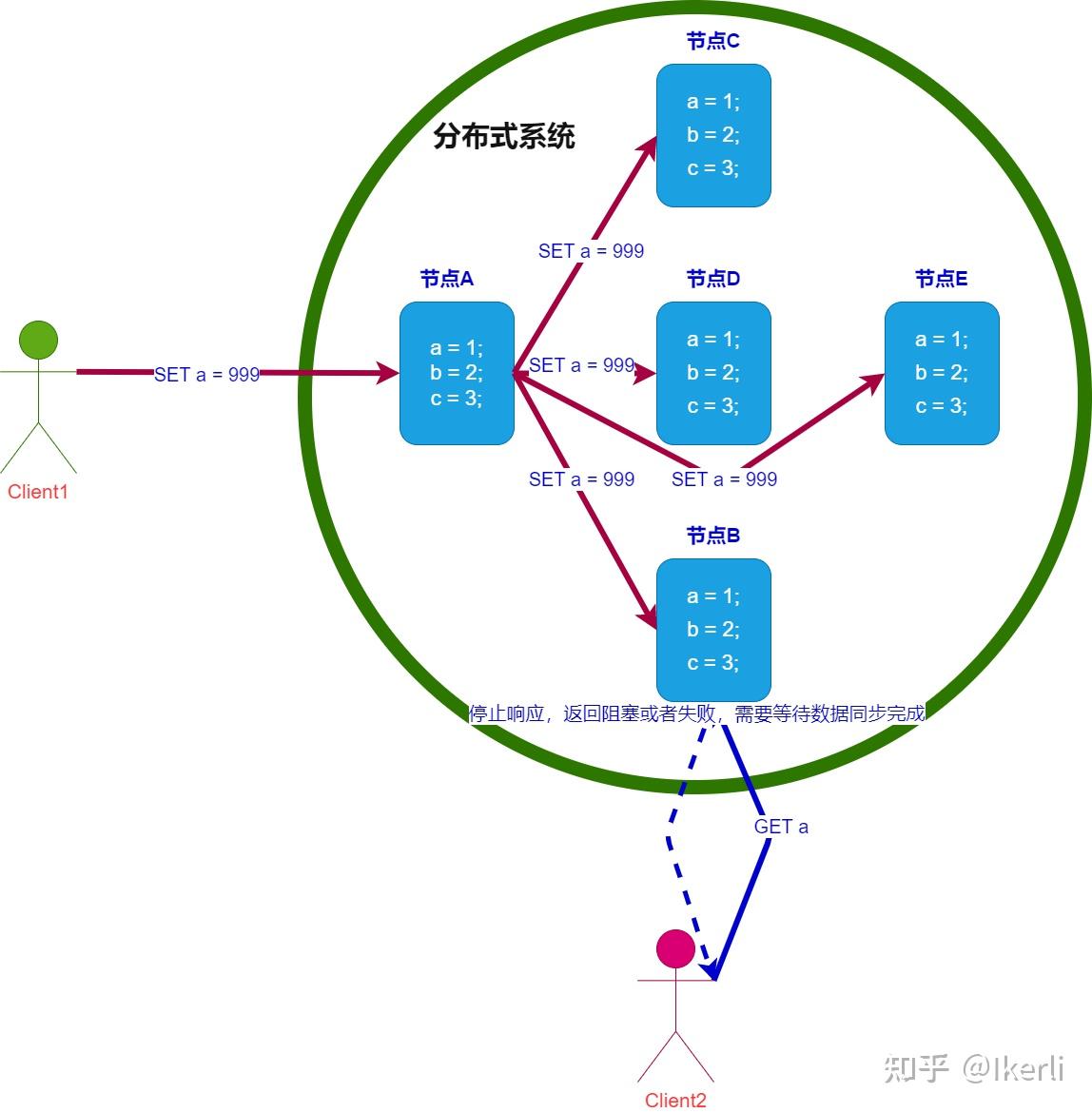
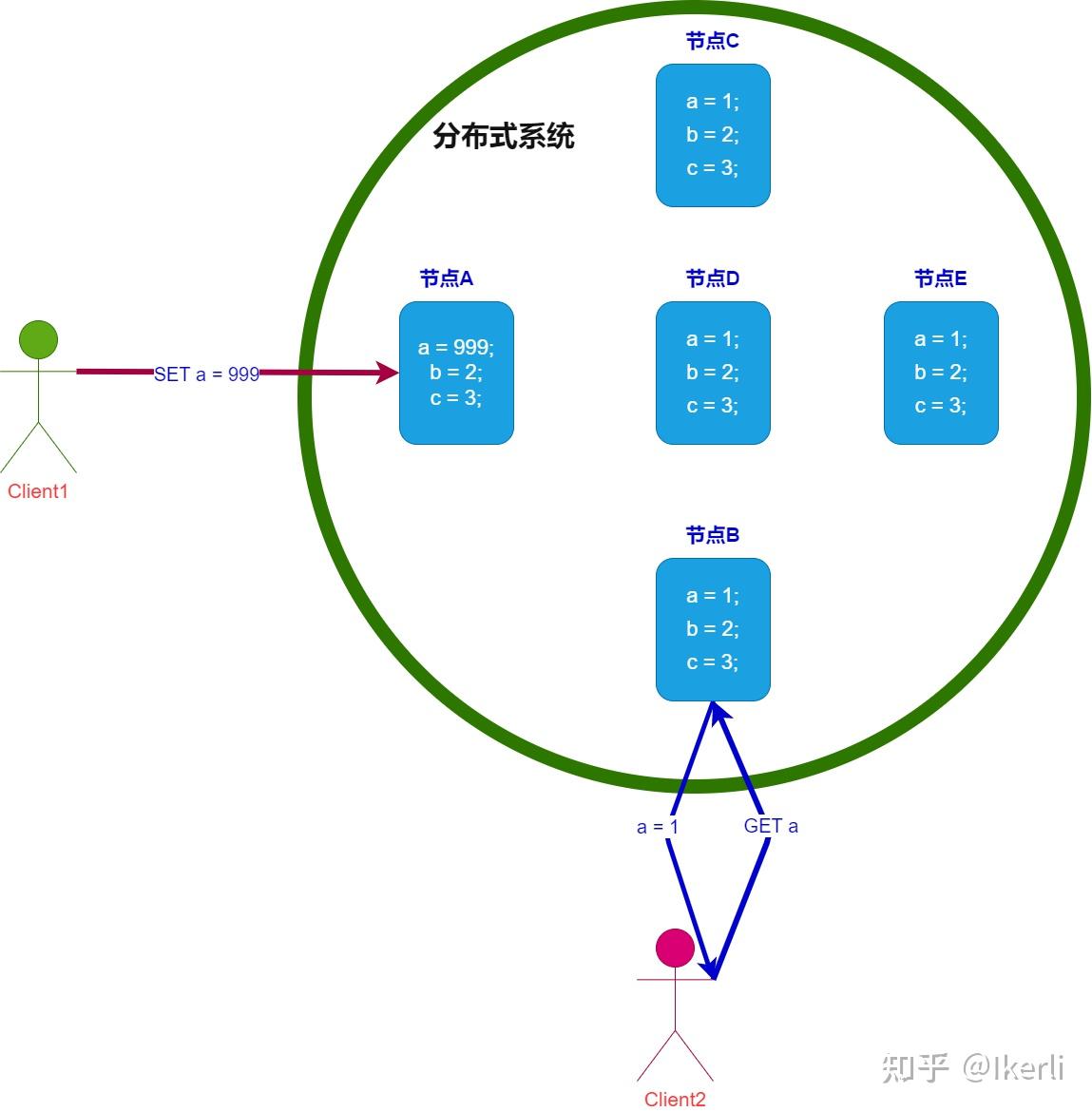
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(所有节点在同一时间的数据完全一致,越多节点,数据同步越耗时)
可用性(A):负载过大后,集群整体是否还能响应客户端的读写请求。(服务一直可用,而且是正常响应时间)
分区容错性(P):分区容忍性,就是高可用性,一个节点崩了,并不影响其它的节点(100个节点,挂了几个,不影响服务,越多机器越好)
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡
C A 满足的情况下,P不能满足的原因:
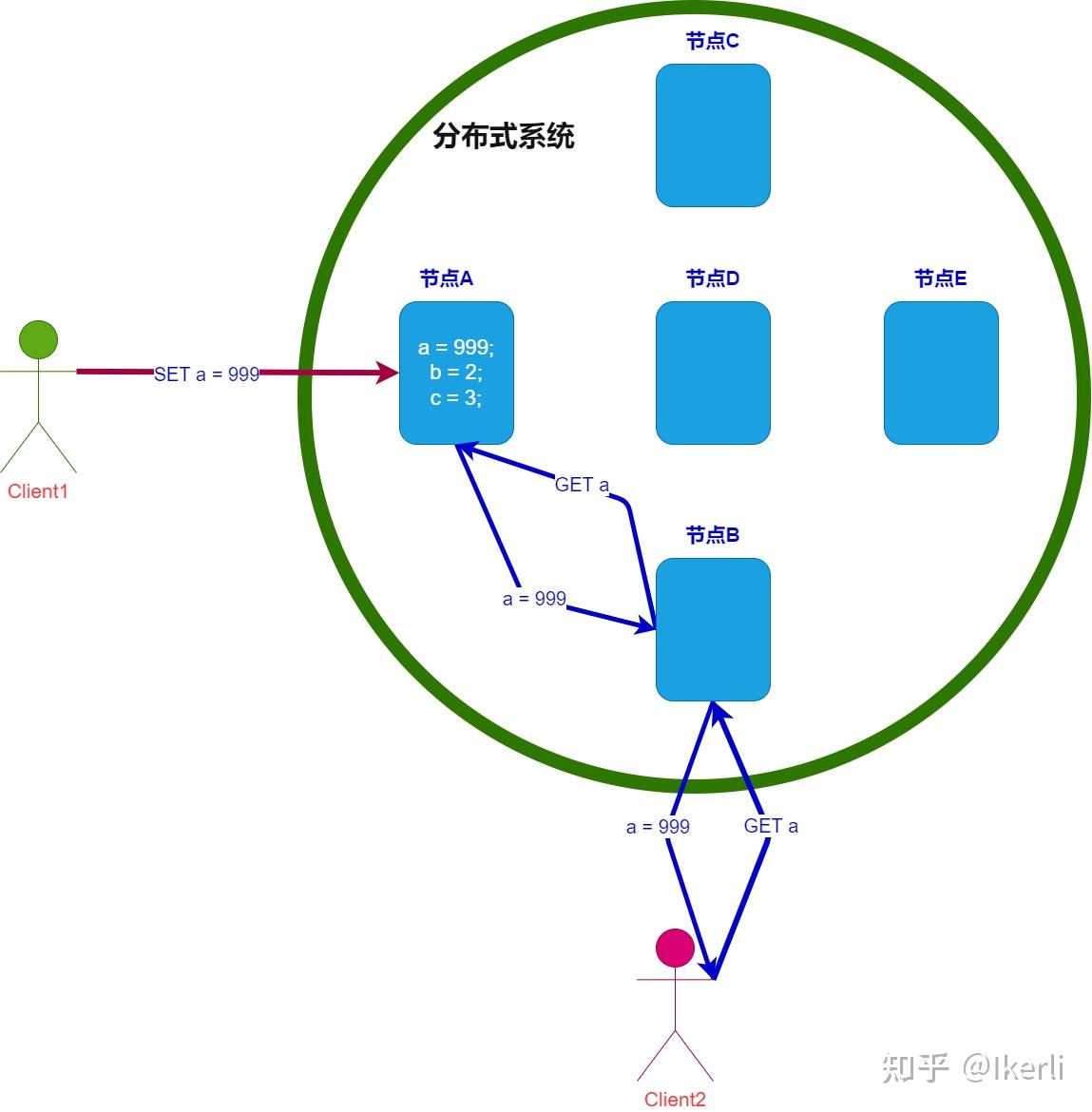
数据同步(C)需要时间,也要正常的时间内响应(A),那么机器数量就要少,所以P就不满足
CP 满足的情况下,A不能满足的原因:
数据同步(C)需要时间, 机器数量也多(P),但是同步数据需要时间,所以不能再正常时间内响应,所以A就不满足
AP 满足的情况下,C不能满足的原因:
机器数量也多(P),正常的时间内响应(A),那么数据就不能及时同步到其他节点,所以C不满足
使用场景 注册中心选择:
Zookeeper:CP设计,保证了一致性,集群搭建的时候,某个节点失效,则会进行选举行的leader,或者半数以上节点不可用,则无法提供服务,因此可用性没法满足
Eureka:AP原则,无主从节点,一个节点挂了,自动切换其他节点可以使用,去中心化
结论:分布式系统中P,肯定要满足,所以只能在CA中二选一
没有最好的选择,最好的选择是根据业务场景来进行架构设计
如果要求一致性,则选择zookeeper,如金融行业
如果要去可用性,则Eureka,如电商系统 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-11-7 17:53
发表于 2024-11-7 17:53