金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
在老张还是小张的时候,有过如下对话:
小张:我对CAP有所了解。
面试官:[惊喜的语气]你了解CAP?展开讲讲?
小张:C是“一致性”、A是“可用性”、P是“分区容错性”,形成不可能三角,最多保全两项。
面试官:ok。 当时误以为自己面试稳了,完全是一个装逼成功的心情~
多年后才明白:面试官的“ok”是失望,小张的阐述约等于“听说过CAP,但不理解”~
本文来扒一扒CAP相关的论文和文章,仔细说说这个定理。
一. 涉及的论文
主要有3篇:
1.《Harvest, Yield and Scalable Tolerant Systems》[1]
1999年,Armando Fox 和 Eric A. Brewer 以定理的形式提到了CAP。 2.《Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services》[2]
2002年,Seth Gilbert 和 Nancy Lynch 对CAP给出了一个形式化的证明。 3.《CAP twelve years later: How the "rules" have changed》[3]
2012年,Brewer给出了一些补充说明。 本文将这3篇论文综合在一起,分4部分解释CAP:
- CAP基本概念;
- CAP典型误区;
- 如何基于CAP原理构建系统;
- CAP证明;
二. CAP的基本概念
CAP三个字母分别指的是强一致性、强可用性、强分区容错性 (注意这三个“强”,很重要,不可省)。
强一致性(Strong Consistency):写请求成功后,其影响立即可见,后续的读请求永远不会读到老数据;
强可用性(Strong Availability):只要请求打到了未宕机的节点,客户端必然能接收到合理的响应;
两个关键点:
1. 能收到Response;
2. Response内容符合预期; 强分区容错性(Strong Partition Tolerance):无论内部有多少消息丢失,系统都能对外提供服务;
CAP定理:分布式系统无法同时保证强一致性、强可用性和强分区容错性。
三. CAP典型误区
3.1 误区一:一致性、可用性、分区容错性只能“3选2”
各性质不是二元模型,要么有,要么没有,只能“3选2”:

不是这种二元模型
而是连续值:
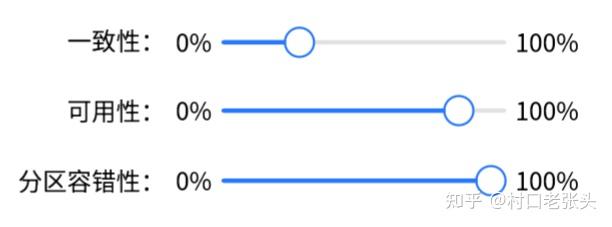
是这种连续值模型
其中,CAP原理也只禁用了全100%的方案:
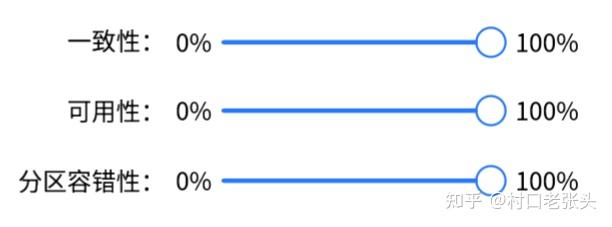
全百分百方案
除该“强CAP原理”外,Brewer也提出了一个“弱CAP定理”:
在一致性、可用性、分区容错性三者中,对其中两者的保障越高,对第三个所能提供的保障就越低。
3.2 误区二:完全放弃强一致性或强可用性
由于强C、强A、强P不能三全,所以有的同学会直接放弃对强C或强A的追求。
但这过于武断。因为虽然强分区容错性一般要保障到底,但网络产生分区毕竟是小概率事件。系统大部分时间是在无分区的状态下运行,是有希望同时保障强一致性和强可用性的。
3.3 误区三:ACID和CAP之间的C字母含义相同
虽然都叫“一致性”,但二者有着本质性的区别。
ACID中的C:指数据库中的数据满足预期的业务约束;
CAP中的C:指的是写操作对后续的读操作可见;
3.4 误区四:一个系统不是AP就是CP
“保障一致性 or 保障可用性”的决策可以发生在很细的粒度,比如子系统、模块、甚至功能等层次。对于一个复杂的系统而言,CAP原理允许其中部分模块选“AP”,部分模块选“CP”;此时很难断定该复杂的系统到底是“AP”还是“CP”。
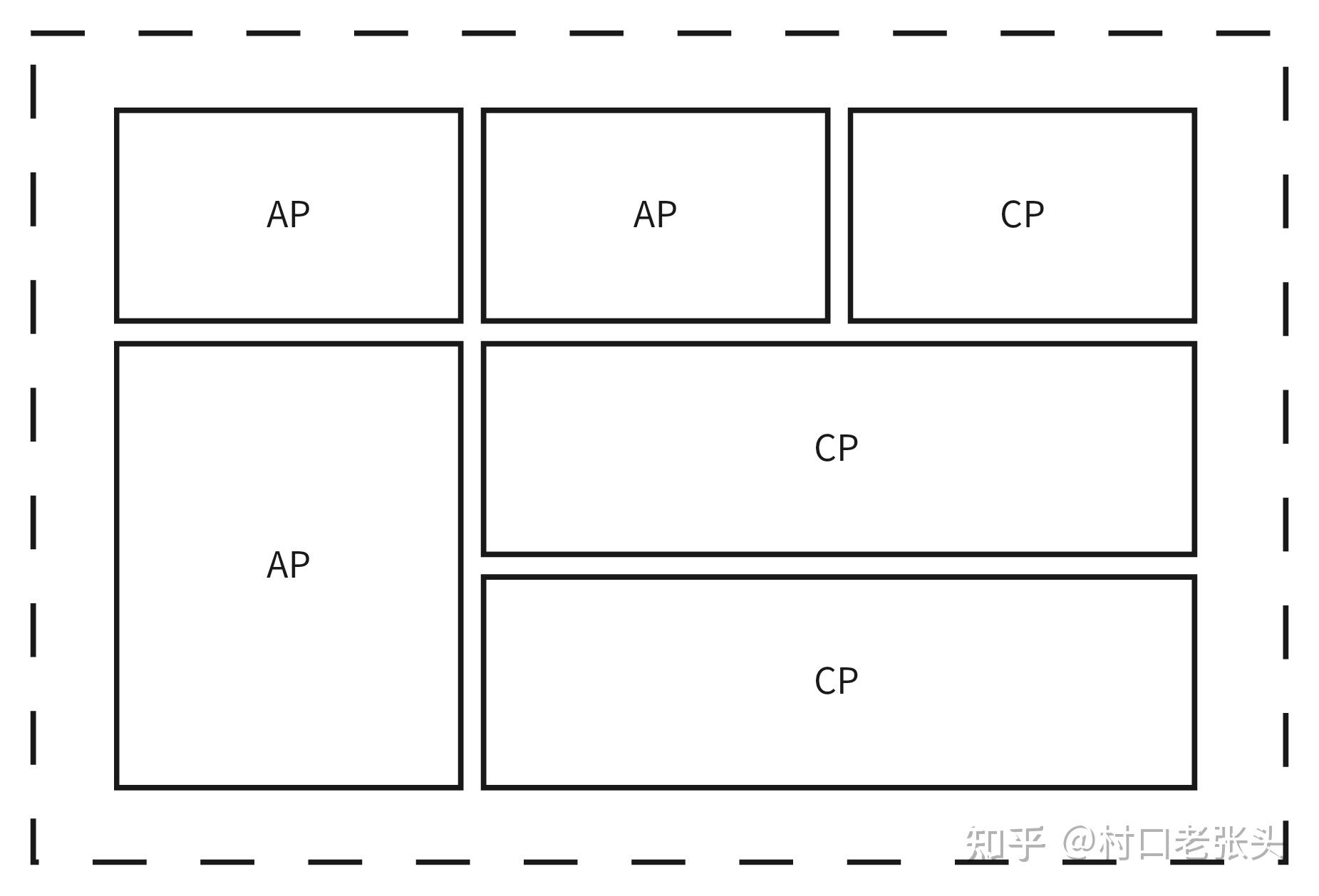
可以在很细的层次进行决策
四. 如何基于CAP原理构建系统
系统设计过程中,以“分区检测-分区进行中-分区恢复后”三个阶段为脉络评估各功能,基本就可以得到想要的答案。
4.1 仔细分析各功能重A还是重C
Brewer给了一个思路:先找系统中的“不变式”(也可以理解为业务约束),然后评估两个问题:
- 在出现网络分区时,是否能够接受系统暂时违反“不变式”?
- 在分区结束后,是否有办法恢复或修正违反“不变式”的数据?
在两个问题的回答都为“是”时,对应的系统或子系统才能选择可用性优先。
4.2 合理选择分区探测口径
在实际系统中,分区检测的口径有建连失败、请求超时等等。
其中超时时间的选取需要仔细考量;长了,会影响系统吞吐量;短了,系统会频繁进入“分区模式”。
4.3 对于可用性优先的功能
分区中:在正常处理用户请求的同时,可能也需要为后续的数据恢复过程记录一些额外信息。
分区后:找出违反“不变式”的数据,并执行数据恢复或补偿。
4.4 对于一致性优先的功能
首先,要尽可能缩小一致性的范围;在整个大规模分布式系统上实现强一致性是高成本行为。
其次,虽然为了保一致性而使可用性受到损失,但业务模型层面若能兼容这点,那影响将大大降低。
比如跨银行转账功能。系统从未承诺过转账会立即成功,当对方银行系统发生故障或延迟时,转账操作的完结可能需要一定的时间。用户在业务模型层面认可这个规则,不会觉得可用性的短暂降低有什么问题。
五. CAP的证明
Seth Gilbert 和 Nancy Lynch 在异步网络环境和半同步网络环境下都给出了CAP的形式化证明。
首先,解释一下两个网络概念,老张的论文解读系列后续文章也会涉及到。
异步网络:一个无时钟的网络环境;每个节点能感知到的事件只有“自己发出了一条消息”和“自己收到了一条消息”;无法衡量时间长短,更没有超时的概念;
半同步网络:有时钟,各节点的时钟时间流速是一致的,但其时间的绝对值不一定相同;比如三个节点时间分别为12:00/11:00/13:00,但他们对于1s、1min、1h这种时间长短的概念是相同的。
其次,说一下大致的证明思路。
Seth Gilbert 和 Nancy Lynch 在针对两个网络环境给出的证明思路很类似,都是反证法,我们放一起说。
假设一个系统同时具备强一致性、强可用性和强分区容错性。
现在,该系统被网络分区划分为两个部分,之间的消息完全丢失(异步网络)或在超时前不可达(半同步网络):
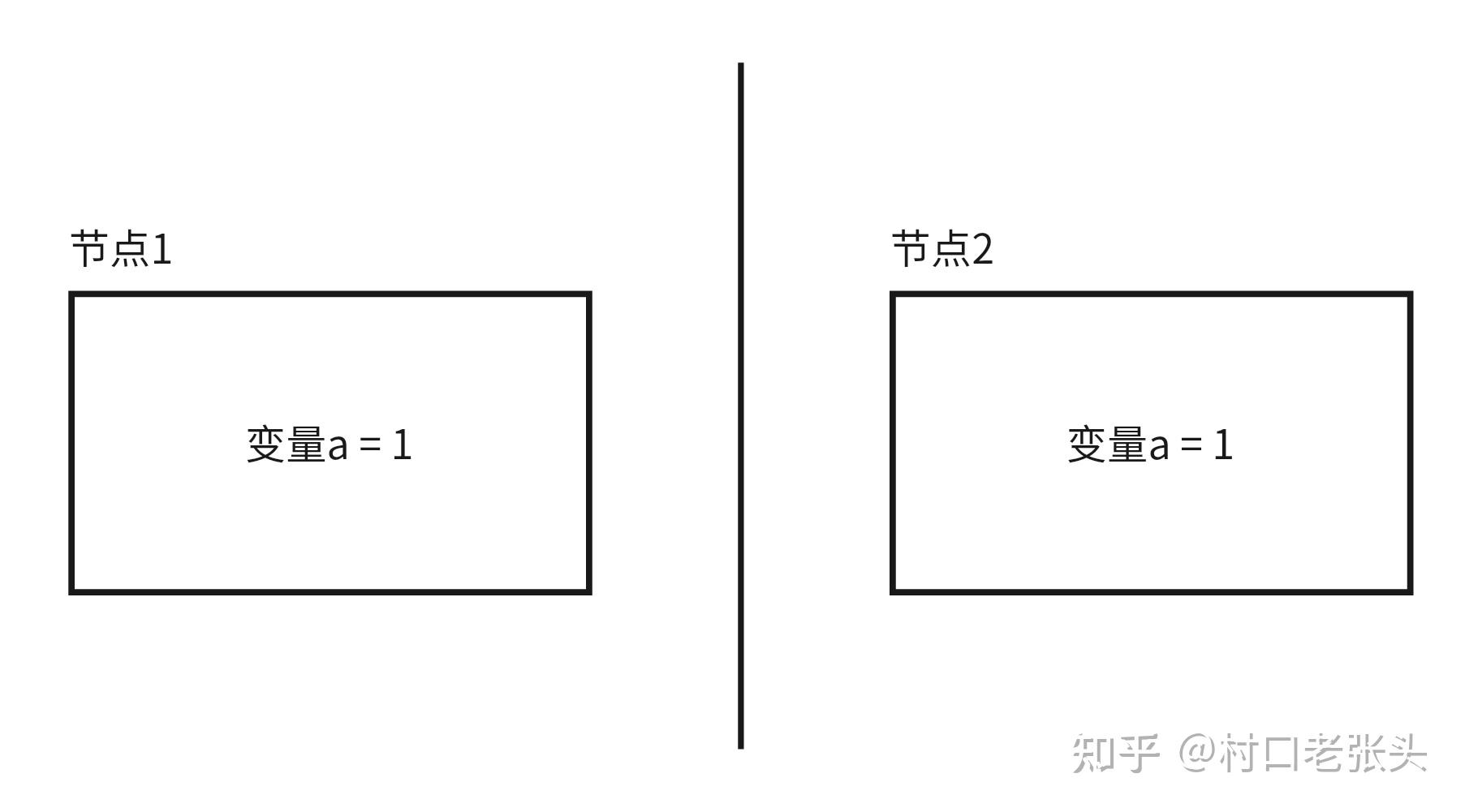
初始状态
此时节点1和节点2上的变量a具备相同的值。
然后一个“将a赋值为2”的写请求打到节点1;因为系统具备强可用性,所以节点1必须正常处理:
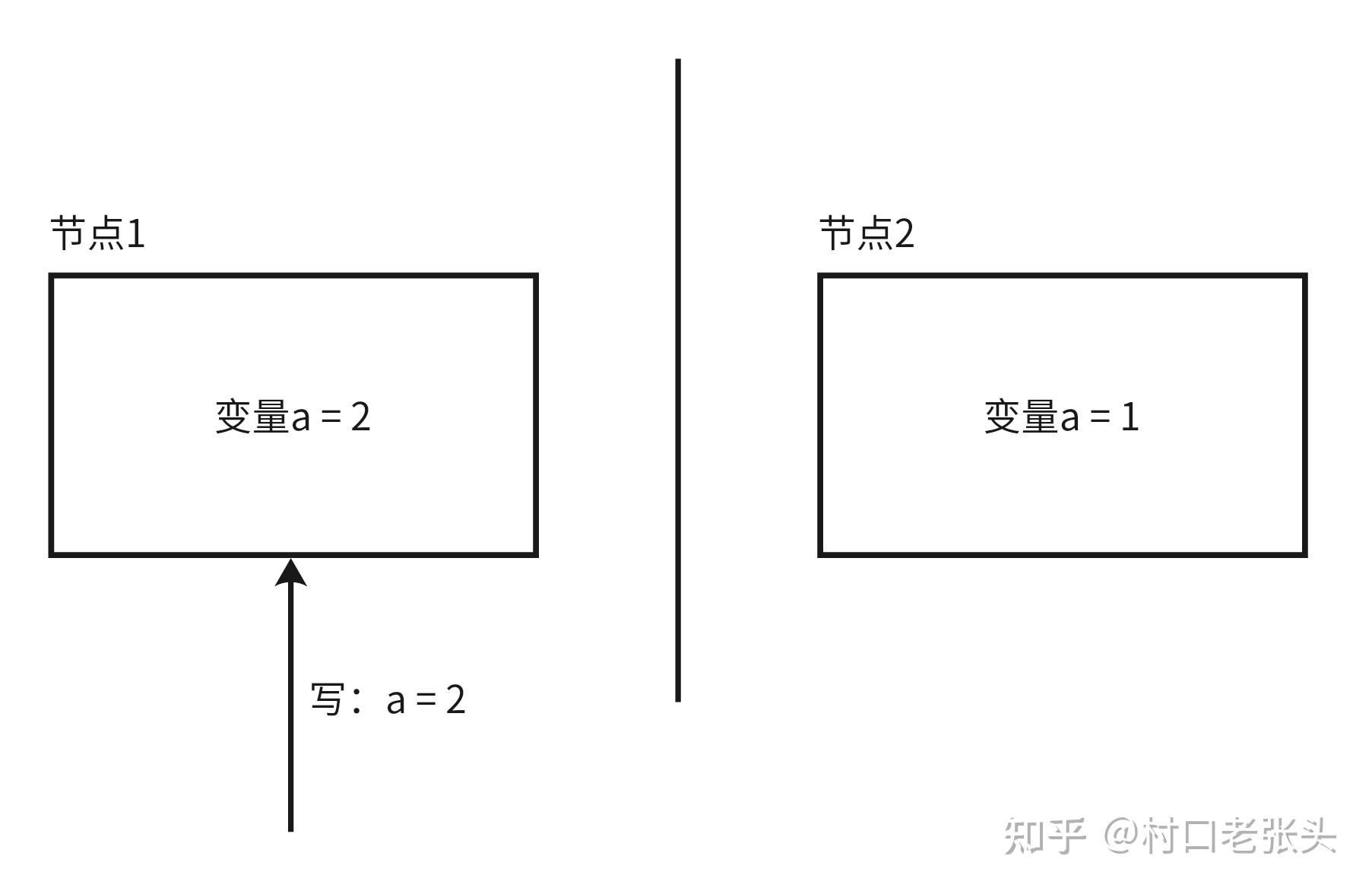
节点1收到写请求
然后,一个a的读取请求打到节点2;因为系统具备强可用性,所以节点2也必须如实返回本地a的值,为1:
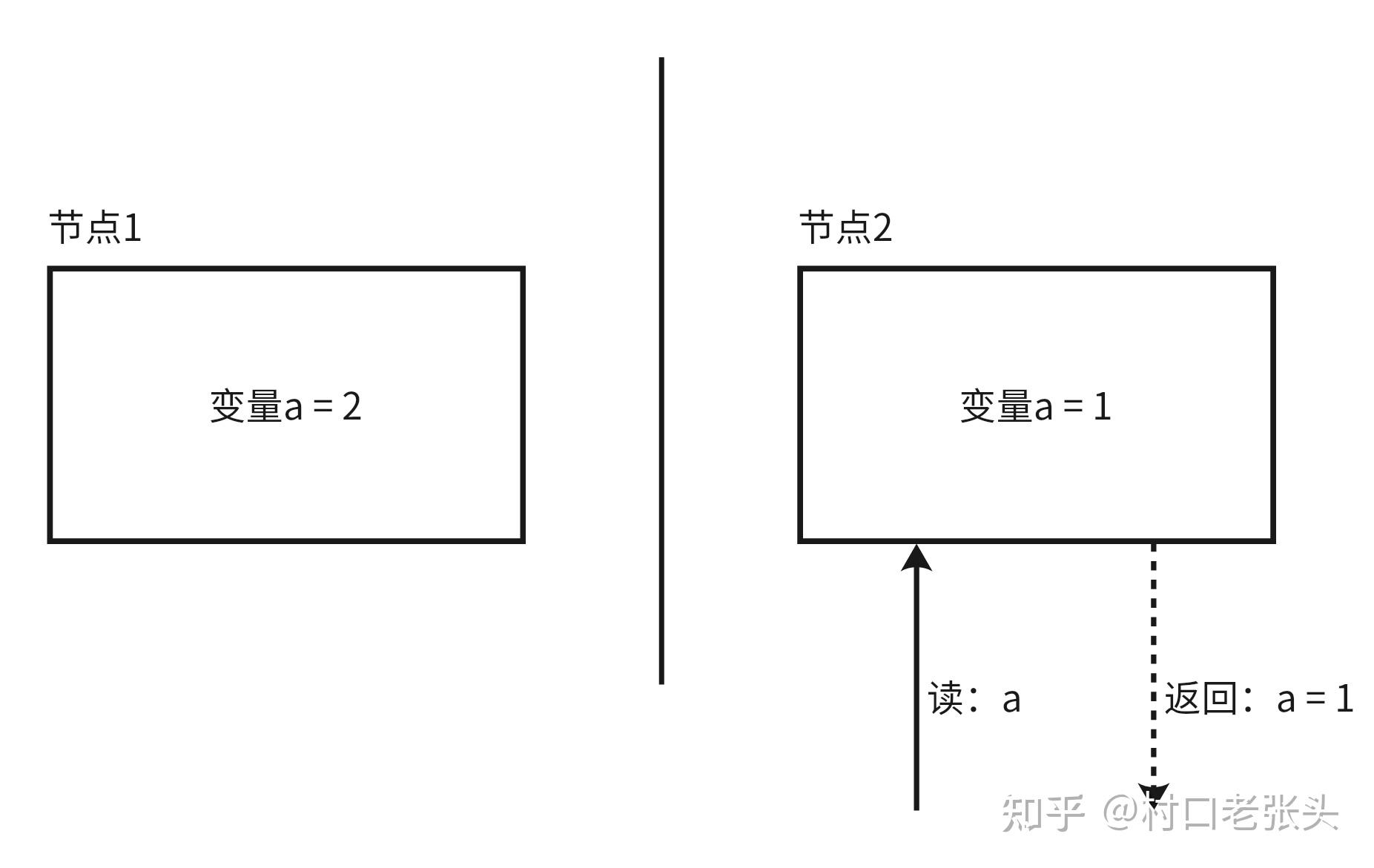
节点2收到读请求
因为该读请求取到了a的老版本值,所以违反了假设中的强一致性。证毕。
总结
本文从基本概念、典型误区、系统构建、定理证明四个方面介绍了3篇文章的大致思路。
才疏学浅,未能窥其十之一二,欢迎交流补充~
觉得过关的话,记得点赞关注加以鼓励哦,我继续更新论文解读系列~
参考
- ^A. Fox and E.A. Brewer. "Harvest, Yield and Scalable Tolerant Systems," Proc. 7th Workshop Hot Topics in Operating Systems (HotOS 99), IEEE CS, 1999, pp. 174-178.
- ^Gilbert, Seth; Lynch, Nancy (2002). "Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services". ACM SIGACT News. 33 (2). Association for Computing Machinery (ACM): 51–59.
- ^Brewer, Eric (2012). "CAP twelve years later: How the "rules" have changed". Computer. 45 (2). Institute of Electrical and Electronics Engineers (IEEE): 23–29.
原文地址:https://zhuanlan.zhihu.com/p/719990516 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-9-24 16:15
发表于 2024-9-24 16:15



