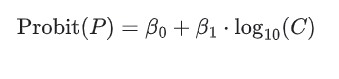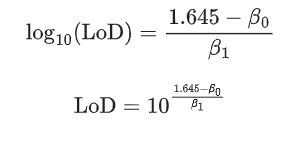插图100%用AI生成。本文严格遵循CLSI EP17-A2 指南的内容,保证内容的权威性,术语定义与原文对应逐字翻译,案例数据经原博士手工验算。
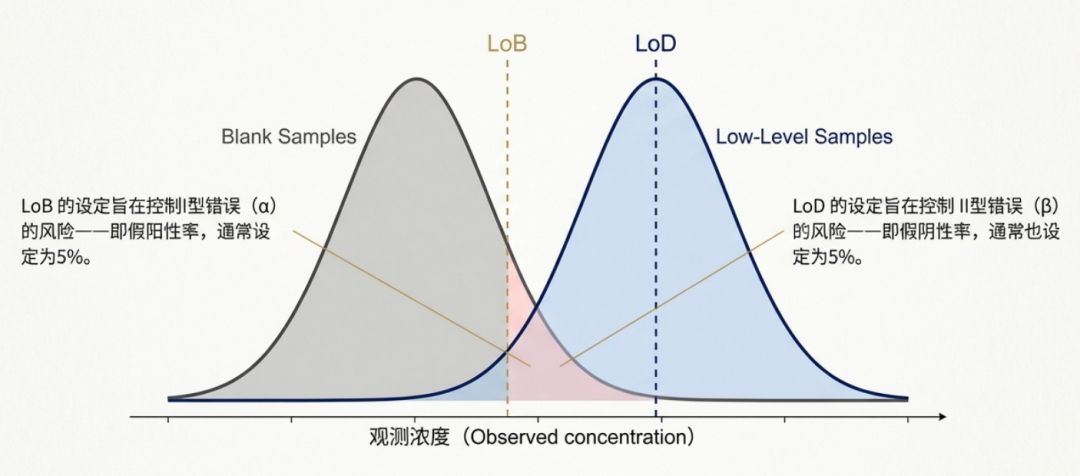
一、 核心概念1. 什么是 Probit 方法?Probit 方法(概率单位法)是一种统计回归分析技术,专门用于处理二项分布数据。在核酸检测性能评估中,它通过建立被测物浓度与检出概率(阳性阳性率)之间的函数关系,来推断出特定检出概率下的浓度阈值。 对于分子测量程序,当样本浓度极低时,结果往往不是连续的数值,而是“有”或“无”。因此,我们无法计算标准差,而是通过阳性率(Hit Rate)来衡量检测能力。 2. 关键术语定义根据 CLSI EP17-A2 标准,以下术语至关重要:
二、Probit 方法计算LOD的实验要求
1. 最小实验设计针对每个待评估的测量程序,建议的最小样本量和配置如下:
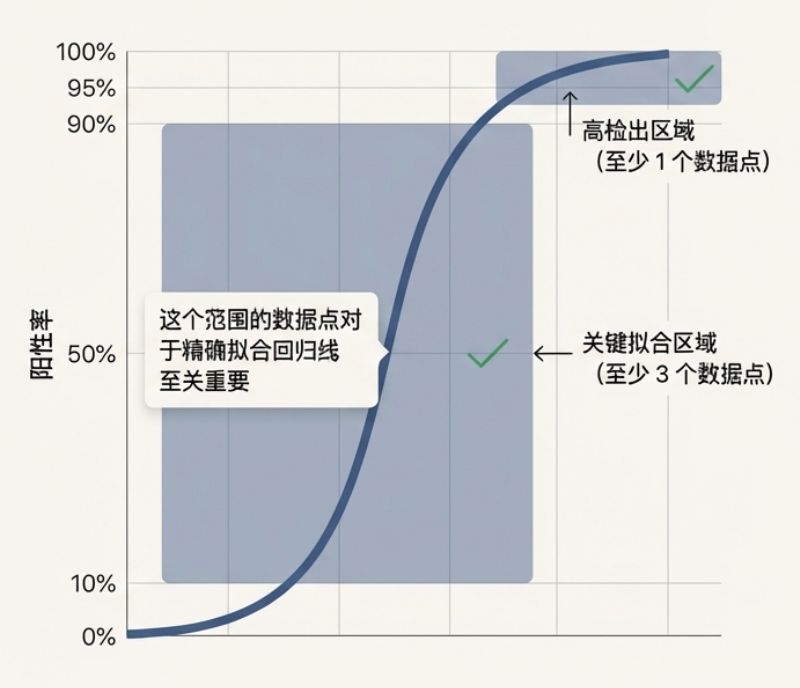
2. 关键:稀释液的分布要求稀释梯度的设计直接决定了 Probit 回归的拟合质量。如果所有数据点都是 100% 或 0% 检出,模型将无法收敛。因此要求:
3. 基因型与亚型如果被测物(如病毒、细菌)存在遗传变异,实验设计应纳入所有主要基因型的代表性样本,确保 LoD 覆盖临床常见的亚型。
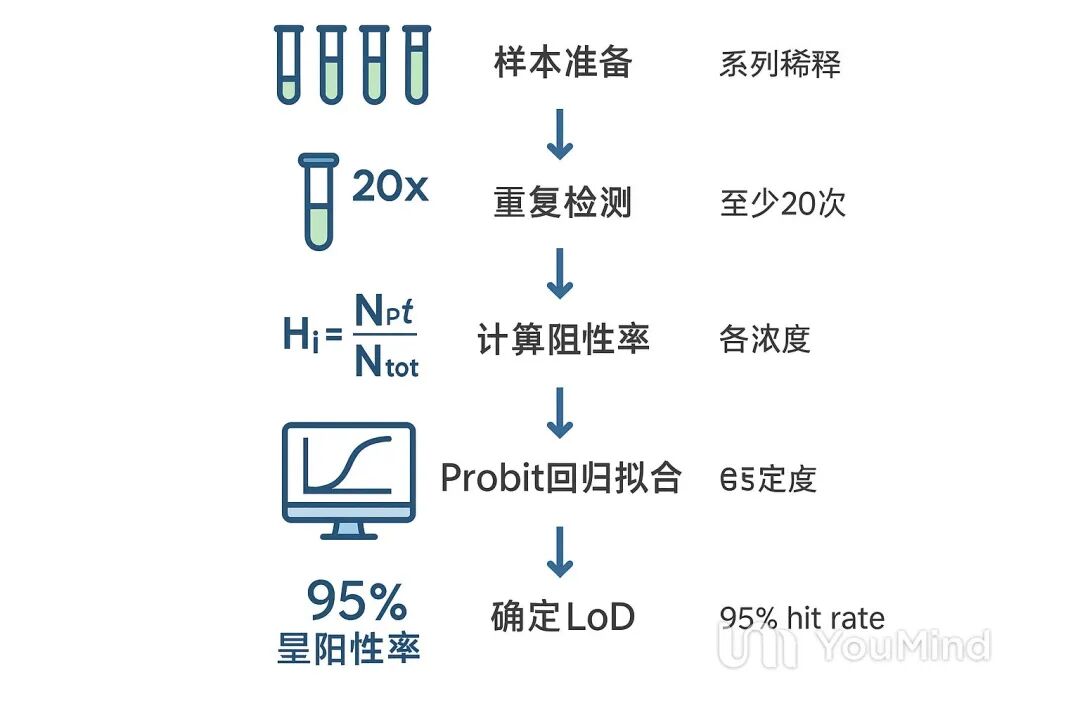
4. 数据分析步骤
汇总数据:计算每个浓度点的阳性率。 模型拟合:使用统计软件(如 SAS, JMP, R, Minitab 等)进行 Probit 回归。 质量检验:使用 Pearson 卡方检验评估拟合优度。如果拟合不佳(p < 0.05),可能需要增加稀释点或重复次数。 计算 LoD:从模型中推导出 95% 概率对应的浓度值。 最终定值:如果评估了多个试剂批次,应取各批次 LoD 计算值的最大值作为该产品的最终 LoD。 三、 Probit 方法计算原理与公式 Probit 方法是一种统计回归分析技术,核心在于将非线性的“浓度-概率”关系转化为线性的数学模型。主要用于评估分子测量程序(如核酸检测或传染病检测)的检测限 (LoD),这些程序的检测能力以阳性率(即阳性结果数与重复测试总数之比,也称为 Hit Rate)来衡量,。 1. 阳性率(Hit Rate)计算对于第
1 实验数据收集我们制备了一系列已知浓度的流感病毒 RNA 标准品(单位:copies/mL),并对每个浓度进行了 20 次重复检测。数据如下:
2 数据分析步骤Excel 计算演示(以流感 qPCR 为例):假设重复次数 N=20。
得到方程:Y = 2.78 X-2.53 3.3 结果解释与报告
小结 精确定义检测限(LoD)不仅仅是一个技术要求,它是确保诊断结果可靠性的基石。Probit方法提供了一个强大、标准化的框架,使我们能够以科学的严谨性和统计学的确定性,来证明和沟通我们检测能力的真实极限。 Probit方法是评价分子诊断方法LOD的金标准。但是很多情况下大家并非用这种方法获得LOD的数据。我始终认为LOD是每种诊断试剂的底线。诊断试剂LOD参数的公示应成为行业共识。 诊断试剂的系统评价除了LOD还有敏感性、特异性等指标,需要参照ROC法进行系统评价。解锁ROC 曲线,从此告别试剂选择障碍。 对于检测来说,未来不应还是一次次独立的检测结果,而是会在流行病学大数据和人工智能的加持下变得更加准确和贴近实际。 CLSI EP17-A2 Evaluation of Detection Capability for Clinical Laboratory Measurement Procedures; Approved Guideline—Second Edition 制作了一个probit法计算最低检测限(LOD)的计算器,输入浓度、阳性数和总数就可以自动计算LOD并且绘制出剂量-反应曲线和probit回归曲线。大家可以用我的文章作为附件上传,让大语言模型生成一下。成功了记得打赏哦。
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号