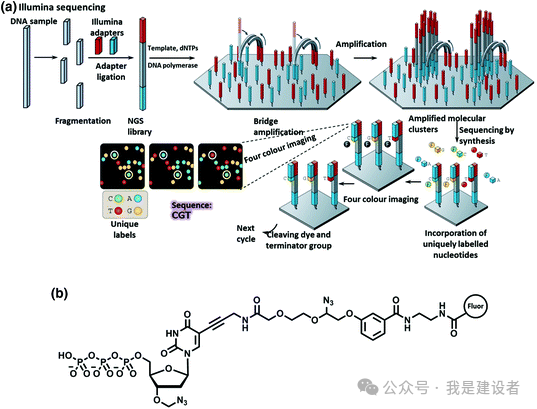
合成测序SBS被广义地认定为短读长测序,这区别于对天然DNA分子不间断读取所获取的长读长。 SBS,特别是以可逆终止子为核心的测序手段,成为Illumina或者说高通量测序(也就是所谓的二代测序)的代名词。可逆终止子带有聚合的阻断基团和可断裂荧光基团标记,通过掺入这样的可逆终止子来提示被测序的碱基信息,通过去除阻断基团来进行循环。
Element和PacBio Onso的创新将可逆终止与通过荧光探测碱基信息的步骤分开,部分消除了簇内分子反应不同步所带来的读取错误率。 可逆终止的SBS反应由于受到聚合酶效率的影响,因而更多产生150bp左右的读长。因此在Illumina主导NGS的这么多年中,受其读取准确率和读长的限制,我们习惯了30x人类基因组的标准(人类基因组的大小大约为3.2亿碱基对/3.2 Gb)。 当然Illumina在这么多年的发展过程中,也在不断提升读长(可接受的准确率前提下),比如在MiSeq上使用的PE300,在HiSeq/NovaSeq上使用的PE250试剂盒等。 但如果不对反应的生化体系进行优化和改进,读长再往上走就很困难,会带来准确率的极速下降。 后进入者多数构建并进化了自己的聚合酶,并大大优化了反应条件,使得现在很多公司都可以提供PE300或者SE400的测序试剂盒。 另一方面,采用不同的SBS测序路径,如上面说到的Element和PacBio Onso,不管称之为亲和力测序还是结合测序,由于掺入的修饰核苷酸只带有阻断基团,不会因荧光基团切割而产生“疤痕”,因此理论上可以实现更长的读长。 同样,MGI也开发了CoolMPS测序生化体系,与Element和Onso类似,将阻断核苷酸的掺入与碱基的探测分开,使用了抗体亲和的方式来识别掺入的修饰核苷酸,也具备高准确率和长读长的优势。 我们体内的DNA聚合酶可以完美的复制一个3.2 Gb的基因组(当然这个过程中有大量的相互作用的其他蛋白用于检查并矫正错误),具有良好processivity。因此,越是接近天然过程的DNA合成/测序,应该具有越好的效果和表现。 如果放弃PE150这个被时代桎梏的惯性,我们在合成测序上到底能实现多长的读长?
Sanger测序,虽然被称为一代测序,但突出优势则是长读长及高准确性,能够实现800bp-1kb的读取。 基于焦磷酸测序技术的罗氏454测序仪,虽然已经被淘汰,也能实现较长的读取,平度读长可以达到400bp。 依靠电化学测序的Ion Torrent由于更接近天然的核苷酸掺入过程,因此能够常规实现SE600的读取。 SE600似乎是一个现实的可参考的目标。 最近在ASHG上,MGI/Complete Genomics推出了DNBSEQ-G800测序仪,使用CoolMPS化学品实现了SE600,同时保持了相当的准确率(具体Q值比例没看到)。
这有什么用呢?与PE150相比,SE600在串联重复区域的覆盖率显著提高,对其他有挑战性的基因组区域的解析都很有帮助。
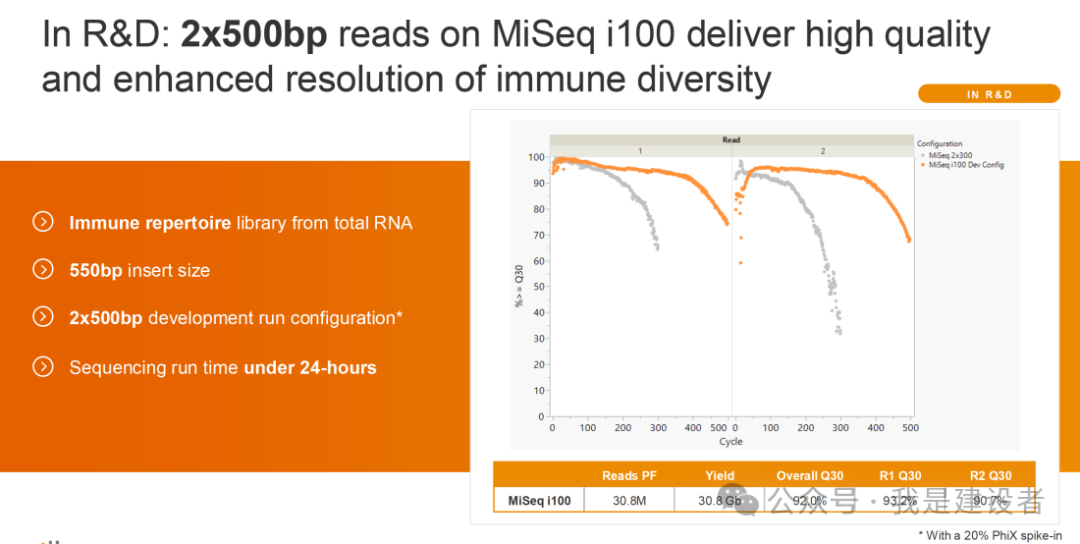
同样在今年的ASHG上,Illumina展示了在研的PE500读取,相比之前在MiSeq上运行的PE300来说,显著提高了读取质量。
时代变了… PE150、Q30、30x基因组这些传统的思考方式正在被打破,而提供高质量、更长读取的高通量测序正在被提上日程。 如果以80%以上读取Q30为准,合成测序的读长记录谁先来亮一个? |


 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号