【中英双语】Illumina测序原理详解 | 边合成边测序
为什么我要那样式儿录呢,因为我们要支持正版啊哈哈哈哈哈哈哈哈,在力所能及的情况下我们要尽量支持正版对不啦! 那我们就开始咯! 首先我们先简单介绍一下,Illumina 测序最基本的技术原理呢,就是基于可逆终止的、荧光标记 dNTP 来做边合成边测序(Sequencing by Synthesis)的工作。 接下来我们根据官方给出的视频对它进行一个相对详细的介绍! Illumina 测序的工作流程,主要分为四个基本步骤:
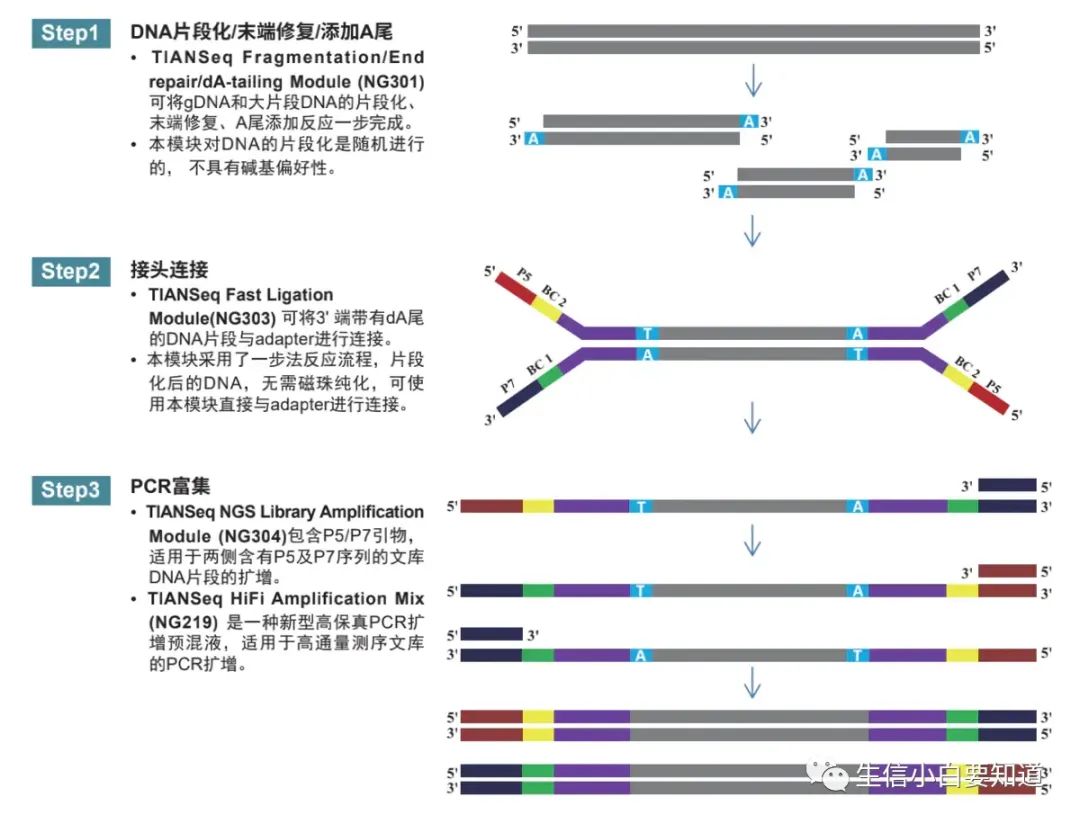
接下来我们把它们一个一个掰开了揉碎了给大家唠一唠! 1 样本准备(Sample Prep)样本准备,也就是我们常说的文库构建。 那么,文库又是什么呢?
样本准备方法有很多种,不过所有的制备方法都会在 DNA 片段的末端加接头(adapter),以便它们能够和测序流程中所需的引物和平台兼容。。 接头是一系列特定的寡核苷酸序列,它们在测序的不同阶段发挥关键作用。接头通常包含以下内容:
2 簇生成(Cluster Generation)簇生成就是每个DNA片段被扩增的过程。 有同学可能会疑惑,我们为什么一定要进行扩增呢?先来解释一波,后面我们就可以亲眼体会到啦!
首先我们先介绍一下到底什么是 flowcell(流动池)。 簇生成的过程就在 flowcell(如下图)上。
让我们打入内部瞅瞅它到底是个什么玩意儿!
上面这个图展示的就是 flowcell 放大好多好多倍的样子,不知道是多少倍,反正放大到了可以让我们肉眼看清的倍数! Flowcell,我们也可以把它叫做芯片,像一个载玻片,上面有一行字母,是这个 flowcell 的编号,中间的通道,我们把它们叫做 lane,这里就是我们测序反应发生的地方!每条 lane 的两端有两个小凹槽,液体就从这个凹槽的小孔那里加进去,然后就流进去啦,所以这个孔我们就叫它液流孔,是液体流进流出的地方。 然后,我们继续放大看! lane 又被分成了好多行,每一行我们把它叫做 swath,继续放大!每行 swath 又被分成好多小格子,每个小格叫做 tile。 以上这些就组成了一个完整的 flowcell。 下面这张图展示的是几个不同的 flowcell。最左边的是 EP 管,大家可以以它为参照,大概了解一下不同 flowcell 的大小。
继续! 进来啦进来啦!
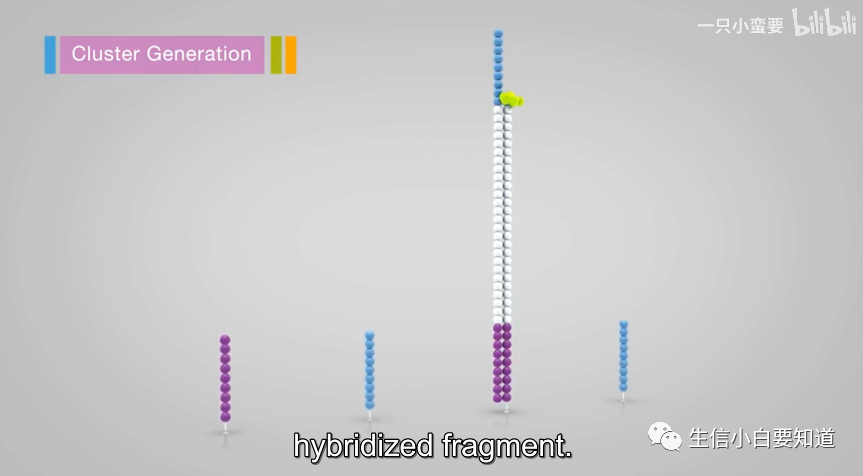
在 lane 的内表面其实做了专门的化学修饰,主要有用 2 种不同的寡聚核苷酸引物,它们被种在 flowcell 的表面,也就是我们前面提到的 flowcell oligo,它们会与 DNA 片段上的 P5 和 P7 适配器序列结合,使即将被测序的 DNA 片段可以被固定在 flowcell 上。图中的一个小圆球就代表一个碱基, 它们是通过共价键连接到 flowcell 上的。
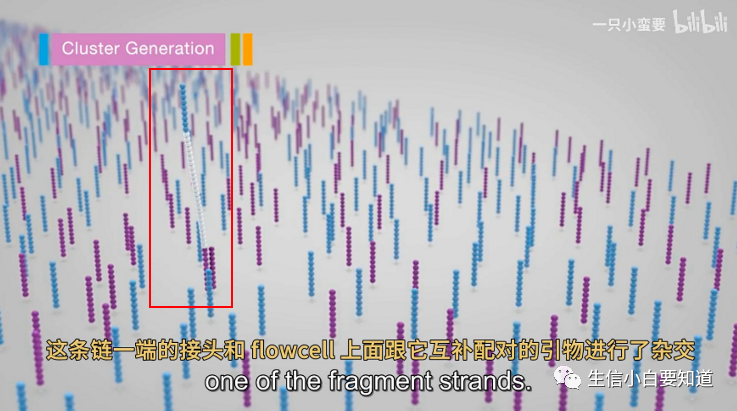
接下来,就要进行桥式 PCR 扩增啦,首先我们要先把文库种到 flowcell 上。
红色框框中的这条就是模板链,我们可以看到这条链一端的接头与 flowcell 上与其互补配对的引物(其中一种)进行杂交。
然后我们加入 dNTP 和聚合酶,聚合酶从引物开始,依靠模板链进行延伸合成互补链。
接下来,加入NaOH碱溶液,双链解开,原始模板链(也就是没有和 flowcell 共价连接的链)就被冲走啦!留下来的是互补链,互补链和 oligo 的连接依靠的是磷酸二酯键,即共价键,被保留下来。
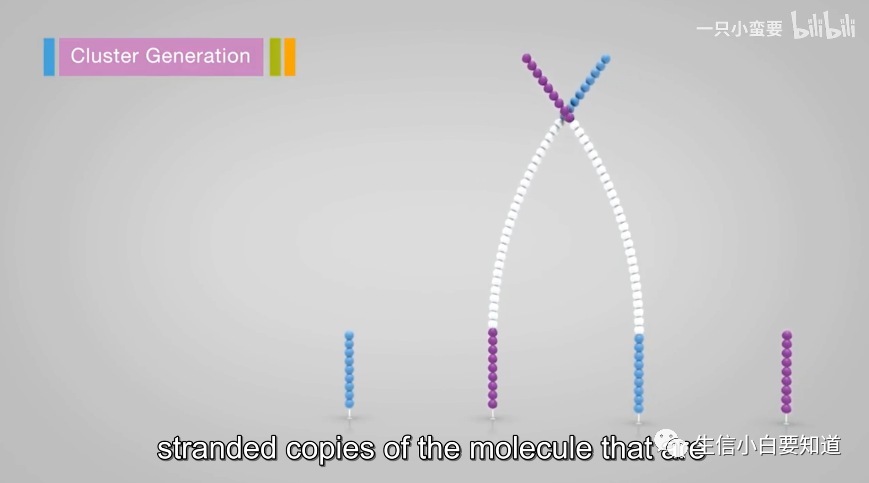
加入中性液体,主要是为了中和碱液,使环境变为中性。然后链会发生折叠,它的另外一端就会和 flowcell 上的另一种引物发生互补配对。
之后加入 dNTP 和聚合酶,聚合酶就会延着第二个引物合成出一条新的链来。
然后再加 NaOH 碱溶液,双链解开,再加入中和液,这两条链就会分别和新的引物杂交又通过新的引物合成出新的链。
这个过程反复进行,简直是指数级增长,然后就会形成一个簇,至此桥式 PCR 扩增完成。
接下来,就是把合成的双链变成可以测序的单链,它使用的办法就是通过一个化学反应把其中一个引物上的一个特定基团给切掉。 那么拿掉哪个呢?反向链!也就是与模板链互补的链,反向链被切断洗去,仅留下正向链,即模板链,也就是目的片段。 再用碱溶液来洗 flowcell,被切断了的链就被冲掉啦,留下的是共价键连在上面的那根链。
再加入中性溶液,加入测序引物,至此,测序正式开始! 3 测序
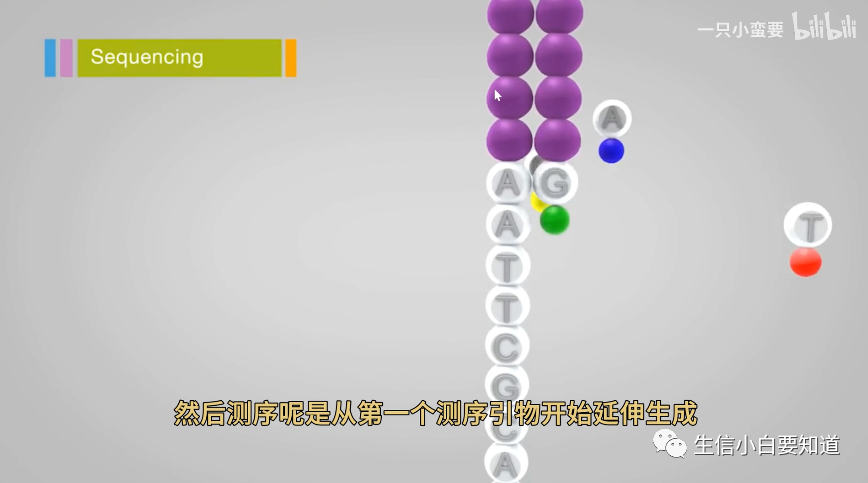
测序从第一个测序引物开始延伸,生成第一个读段。然后我们可以看到,测序加进来的是带荧光标记的 dNTP(红黄蓝绿)。
dNTP 的 3’ 末端连接了一个叠氮基团,这个叠氮基团在链延伸的时侯起到了阻止聚合的作用,所以一个循环只能延长一个碱基(这就是传说中的荧光修饰dNTP、可逆合成终止,Illumina测序的最核心技术)。
开始互补配对,一个碱基加入后呢,会发出特征荧光信号,通过激光扫描,我们就能根据发出来的荧光判断它是哪个碱基,从而推断原来模板链上的碱基是哪种。
一个循环结束后,就会化学试剂把叠氮基团和标记的荧光基团切掉,3’ 端的羟基暴露,再加入新的 dNTP 和酶,继续进行延长,不断反复这个过程。 这个过程就被称为边合成边测序。 那么如何确定循环次数呢? 循环的次数取决于 read 的长度。发射波长与信号强度一起决定了 base call(碱基读出)。
在大规模并行的过程中,数以千万计的簇被测序。上图仅代表整个 flowcell 中的一小部分。
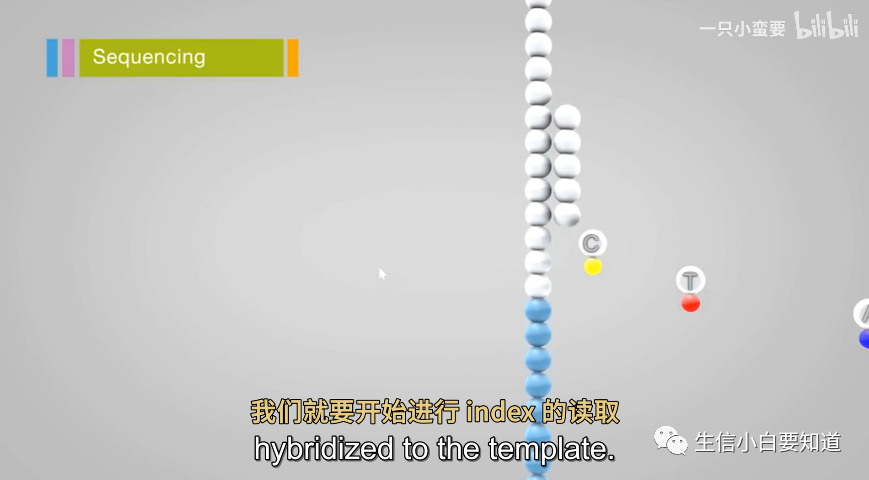
在第一次 read 读段结束后,我们就要开始进行 index 的读取。 这个 index 到底是啥玩意儿呢?
通过前面的介绍,我们可以知道,它是在接头里面的一个序列。那它具体什么呢?由于 Illumina 测序量很大,往往一个样本达不到几亿条 DNA,所以就在文库接头做了一些标记,每个样本都有特定的接头,每个接头都有特定的序列,这段序列可以标记样本的来源,我们就称之为 index,也叫 barcode。
那么,要读取这个 index1 序列(为什么叫 index1?因为后面还有 index2!),首先把上面测完的读段产物洗掉,然后加入 index1 的测序引物,它结合的位点呢,正好就在这个 index1 序列的旁边,接下来进行第二轮测序,一般读 6-8 个碱基,这段读出来我们就可以知道这个片段来源于哪个样本啦! 接下来,进入另一个重头戏! 双端测序(Paired-end sequencing),这就是 Illumina 测序的另一个核心技术啦! 与单端测序不同,双端测序是从 DNA 或 RNA 样本的两端进行测序,从而获得更多的信息和更高的测序覆盖度。 简单来讲就是,一根链除了从正向读一遍,还要从负向再读一遍,这样是不是就可以把测序的有效长度增加一倍。
和刚刚一样,index2 的引物也进来完成测序。
继续通过聚合酶完成桥式 PCR 扩增。
之后洗去原来的链,留下反向链。
现在开始进行另一端,也就是 read2 的测序,加入 read2 的引物,与 read1 测序步骤一样,开始一个一个读,直到达到预期长度。 这里要注意的是,read 2 测的是反向互补链。 测序结束后,我们就可以开始进行数据分析啦! 4 数据分析
前面的过程产生了数百万个 reads,代表所有的片段。来自样本文库的序列通过在文库构建过程中引入的独特 index 进行分离。
对于每个样本,具有相似延伸的 base calls 会被聚类。正向和反向 reads 被配对生成连续序列。
这些连续序列与参考基因组进行比对,用于突变识别。 结束!!! 0 常见问题解答评论区有很多同学们的提问非常有建设性且有趣味性!当然也有很多共性!所以,为了减少大家辛苦翻阅评论查找答案,我在这里总结了一部分常见问题并进行了解答,希望可以对大家有所帮助。 如有错误,请批评指正!我立正挨打!马上改进!
如有需要,我们后续补充它! 参考资料
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号