金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
对抗样本
- 现象:在输入中添加肉眼几乎无法察觉的微小扰动(如噪声),即可让模型以高置信度输出错误结果。例如,一张熊猫图片加上噪声后,模型可能将其误判为“长臂猿”。
- 神奇之处:模型对高维空间的方向极度敏感,而人类感知无法捕捉这种扰动。
- 原因:高维空间的线性特性被非线性模型放大,导致决策边界脆弱。
- 应用与风险:对抗训练、模型鲁棒性研究,同时暴露安全漏洞。
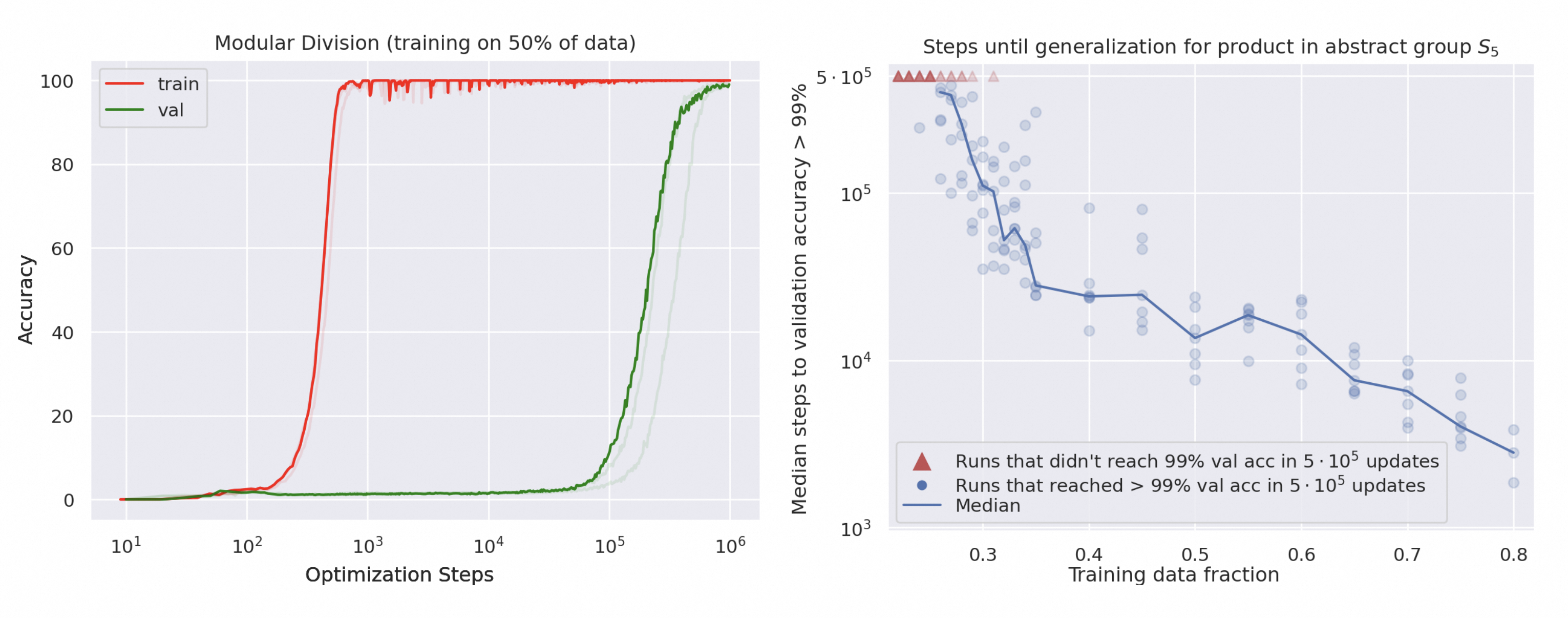
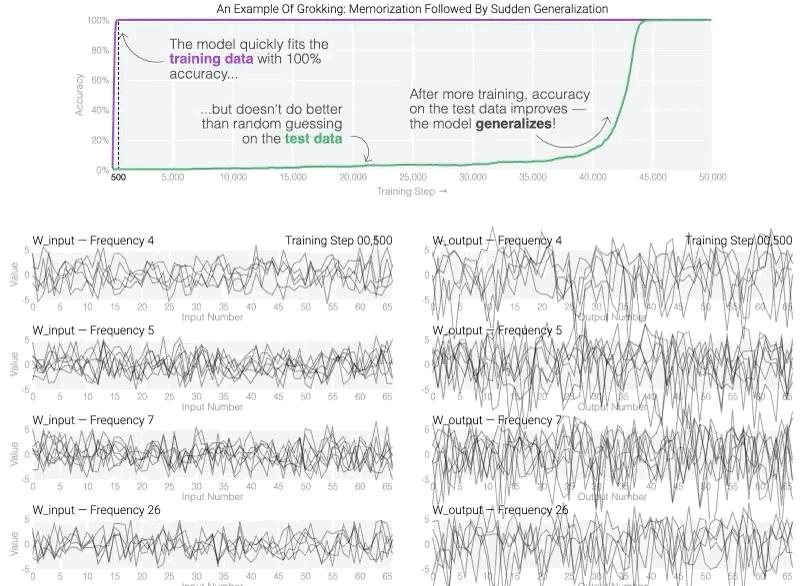
过参数化的“反直觉”优势
- 现象:神经网络参数数量远超样本量时(如百万参数训练几千样本),泛化性能反而更好。
- 传统认知:奥卡姆剃刀原则认为简单模型泛化更好。
- 解释:
- 隐式正则化:梯度下降偏好平坦极小值,降低过拟合风险。
- 双下降曲线:模型性能随参数增加先变差再变好(传统U型→扩展的钟型曲线)。
- 意义:颠覆了“模型复杂度需匹配数据量”的传统观念。
损失曲面中的“鞍点逃生”
- 现象:非凸损失曲面上存在大量鞍点(梯度接近零但非极值点),但SGD(随机梯度下降)能有效逃离。
- 机制:
- 噪声助力:小批量梯度估计的随机性提供扰动,推动参数逃离鞍点。
- 高维空间特性:鞍点在某些方向的曲率为正,梯度噪声可沿负曲率方向下降。
- 可视化:低维空间中鞍点是障碍,高维中却是“通道”。
神经网络的“彩票假设”
- 现象:随机初始化的稠密网络中,存在某个稀疏子网络(“中奖彩票”),单独训练该子网络可达到原网络性能。
- 实验:通过剪枝保留特定连接,子网络性能不降反升。
- 启示:参数初始化与架构共同决定模型能力,而非单纯参数数量。
批归一化(BN)的“玄学”效果
- 现象:BN层不仅加速训练,还能提升模型最终性能。
- 传统解释:减少内部协变量偏移(每层输入分布稳定)。
- 新发现:
- BN实际使损失曲面更平滑,允许更大学习率。
- 对梯度传播有隐式正则化作用。
- 争议:部分实验显示,某些场景下BN可被其他方法替代。
模型“涌现能力”:小模型做不到,大模型突然行
- 现象:当模型参数量超过某个阈值(如千亿级),突然展现出零样本学习、复杂推理等能力。
- 例子:GPT-3能完成未曾明确训练的任务(如写代码、解数学题)。
- 机制:海量参数隐式编码了世界知识,并通过上下文学习激活。
知识蒸馏:小模型“偷师”大模型
- 现象:通过让小型学生模型模仿大型教师模型的输出,小模型性能显著提升,甚至接近教师模型。
- 原理:教师模型的软标签(Softmax概率分布)携带了类别间相似性信息。
对比学习的“无监督奇迹”
- 现象:无需人工标注,通过最大化相似样本的一致性、最小化不相似样本的相似性,模型能学习高质量表征。
- 经典方法:SimCLR、MoCo通过数据增强构建正负样本对。
- 效果:在ImageNet上,自监督模型的线性评估(冻结主干+训练分类头)准确率超过早期监督模型。
神经切核(NTK):无限宽网络的“确定性”
- 现象:当神经网络宽度趋近无穷大时,其训练动态可由确定的核函数(NTK)描述,且梯度下降等同于核回归。
- 意义:为理解深度学习提供了理论工具,解释了宽网络易于训练的原因。
|
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-5-26 13:44
发表于 2025-5-26 13:44


 提升卡
提升卡