用户名
UID
Email
密码
记住
立即注册
找回密码
只需一步,快速开始
微信扫一扫,快速登录
开启辅助访问
快捷导航
门户
Portal
社区
BBS
资讯
会议
市场
产品
问答
数据
专题
帮助
签到
每日签到
企业联盟
人才基地
独立实验室
产业园区
投资机构
检验科
招标动态
供给发布
同行交流
悬赏任务
共享资源
VIP资源
百科词条
互动话题
导读
动态
广播
淘贴
法规政策
市场营销
创业投资
会议信息
企业新闻
新品介绍
体系交流
注册交流
临床交流
同行交流
技术杂谈
检验杂谈
今日桔说
共享资源
VIP专区
企业联盟
投资机构
产业园区
业务合作
投稿通道
升级会员
联系我们
搜索
搜索
本版
文章
帖子
用户
小桔灯网
»
社区
›
C、IVD技术区
›
基因测序技术
›
测序小白必看!5分钟搞懂测序数据
图文播报
2026庆【网站十三周
2025庆【网站十二周
2024庆中秋、迎国庆
2024庆【网站十一周
2023庆【网站十周年
2022庆【网站九周年
返回列表
查看:
6402
|
回复:
0
[讨论]
测序小白必看!5分钟搞懂测序数据
[复制链接]
青草
青草
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
发表于 2025-4-15 11:19
|
显示全部楼层
|
阅读模式
登陆有奖并可浏览互动!
您需要
登录
才可以下载或查看,没有账号?
立即注册
×
01
数据的产生
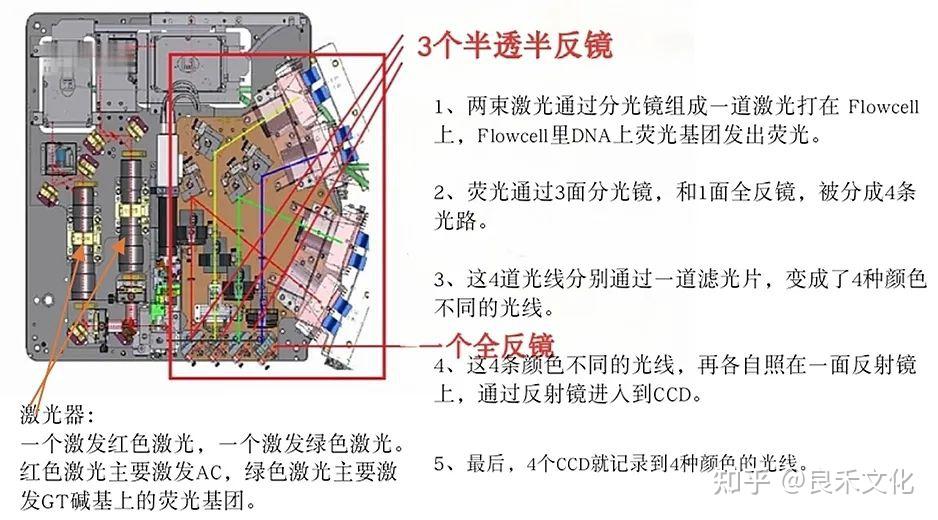
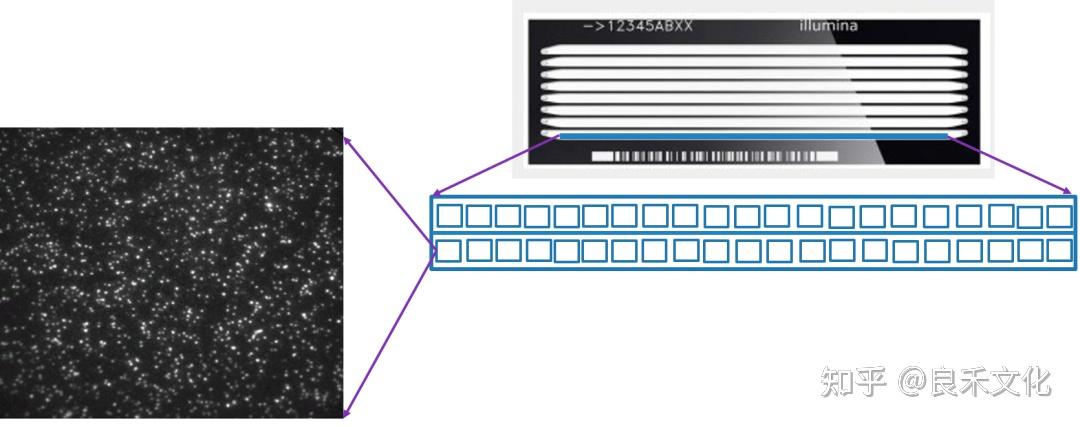
1、测序仪(Hiseq)
HiSeq测序仪由一台高精度的显微光学扫描仪(用于扫描芯片),一整套的液流和温控系统(用于扩增 DNA)以及计算机软硬件(测序数据获取及处理)组成。
HiSeq使用CCD作为其感光元件。CCD只能感光,不能分辨颜色,因此该机器使用四路 CCD+滤光片来分辨四种碱基。(使用4种荧光染料标记的dNTP,最新的为用两种荧光染料标记的双通道SBS技术以及基于CMOS感光元件的单通道SBS技术。)
TDI线扫描:
和传统相机一拍就是整张照片(面阵)不同,HiSeq 采取的是一种特定的叫TDI的线扫描方式。
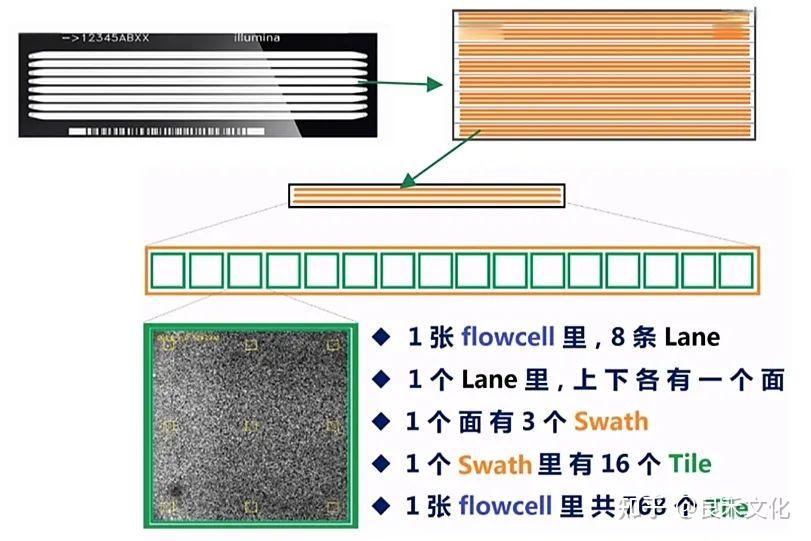
2、测序芯片
3、图像处理
1).tiff
扫描出来的最原始的文件,记录了每个像素点上采集到的光强度。
2)图像文件→光点文件
就是把4种颜色的4张照片组合在一起,变成一张有4种颜色的彩色照片。
4个CCD产生的4张照片,将它们合成首先要解决的是4张照片在空间位置上的匹配问题。软件是通过对4张照片上的亮点相互比对,找到最合适的、匹配的位置。
4、碱基不平衡
碱基平衡,即在测序过程当中,每个循环(A、C、G、T)四种碱基都是比较均匀的存在。如基因组文库。
碱基不平衡文库指的是A+T/G+C≤40%或≥60%的样本,最典型的就是PCR扩增子文库:特点是PCR有特定的起始位点,在一个特定的测序循环中,几乎所有的片段都是同一种碱基,而剩下的3种碱基特别少。
这在反映到测序照片上的时候,就变成一张照片特别亮,光点很多。而其它的三张照片就特别暗,上面的光点就很少。这时候,要软件做空间上的比对,软件就会觉得困难,因为对于那几张暗的照片,软件很难判断上面的光点是否与那张亮的照片上的光点真正对得上。结果,就是判断出来的可靠性变差。最后,就是测序的数据质量变差,有效数据量也会变少。
要解决这个问题,办法是在测序过程中掺入一些碱基平衡的文库。例如掺入全基因组文库,或者Ilumina提供的标准的Phix文库,这些都是碱基平衡文库。
常见的碱基组成不平衡的样本类型比如:甲基化、扩增子、转录组、ChIP、重复序列测序(16S rDNA,功能基因扩增文库……)等等,其中重亚硫酸盐处理后的甲基化样本是碱基组成极度不平衡的,基本没有C,只有A、T、G三种碱基,而T的含量又比正常样本增加几乎一倍。
5、Phix文库
PhiX文库中GC含量约为45%,PhiX DNA就是ΦX174噬菌体的DNA,其基因组的长度大约4kb,其序列已清楚地被测定。
PhiX DNA文库没有Index,所以在样本Demultiplex的过程中,被挪到undetermined的文件中,不会与别的有Index的文库相混。
PhiX的序列是已知的,所以,在测序过程中,
仪器会对PhiX的序列进行比对
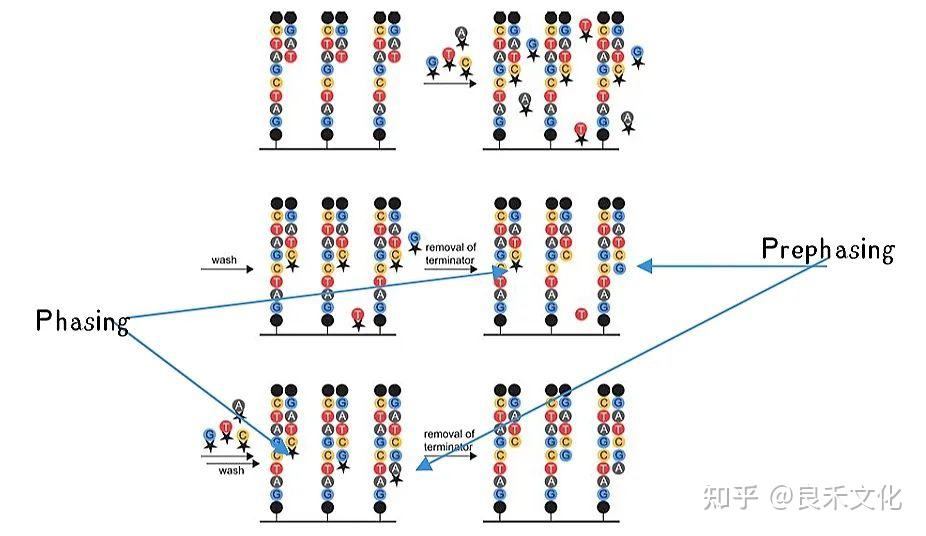
,算出Phasing和Pre-Phasing。(Phasing,一个簇中,有多少比例的DNA是少合成了一个碱基,Pre-Phasing,有多少比例的DNA是多合成了一个碱基。)
样本的碱基越不平衡,Phix文库的比例越高。PhiX可以同时起到两个作用:改善碱基平衡度,作为阳性对照监控测序操作是否成功。
<hr/>
02
数据质量控制
1、Phasing和Prephasing
1)Phasing
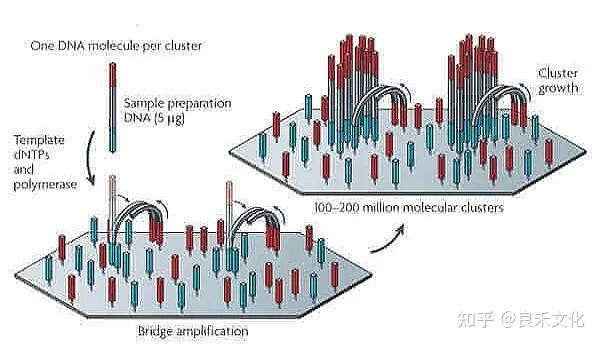
在Illumina的测序过程当中,一个簇大概有5千个到 1万个分子。但是在边合成边测序的过程当中,每一步酶反应,理想情况下,应该这5千个分子都延长1个碱基。
但实际情况,总有少量分子没有完成延长反应。也就是说,总有少量的分子会掉队,我们称这种掉队的现象叫Phasing。
Phasing主要是由于聚合酶活性不足所引起的,由于dNTP经过修饰,天然聚合酶对其活性必然会降低。
掉队的分子,它所发出的荧光信号,和大部队所发出的荧光信号是不一样的。这个循环的次数越多,掉队的分子就越多。所以,测序越到后面,它 Phasing 的分子数就越多。最后,信号的可靠性就越差。
2)Prephasing
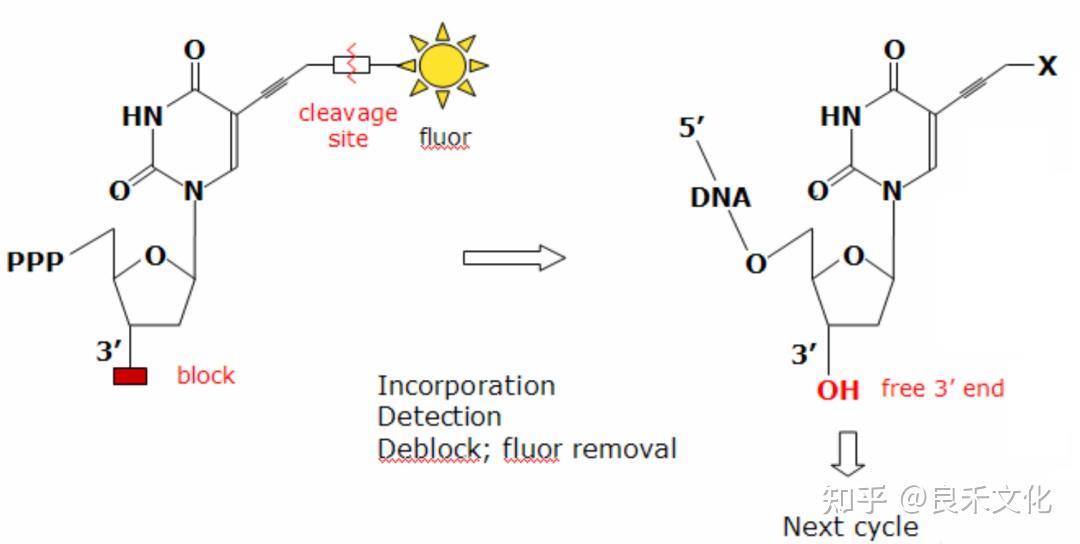
在测序过程中,还会有一部分分子会跑得超前,也就是在一个循环中,它延长了2个碱基。其主要原因是dNTP上标记的那个叠氮基团(-N₃)掉了,当其加到合成链的3´端之后,聚合反应不会终止,直到再加上了一个带叠氮基团的dNTP之后,这个聚合反应才停下来。其所发出来的荧光颜色,也是和大部队不一样的。同样也会使信号的可靠性变差。
叠氮基团在常温下不稳定,尤其是3´端的叠氮基脱落后,dNTP的3´端的羟基就会暴露出来。所以其测序试剂盒需要低温保存,测序仪中存放试剂的位置也是控低温的。
在illumina的SBS测序过程当中,Phasing和Prephasing是限制测长的最主要原因。即随着循环不断进行,越来越多的分子掉队,还有越来越多的分子超前。当它们所产生的噪音,掩盖了大部队的信号的时侯,也就是测序开始测不准的时侯。
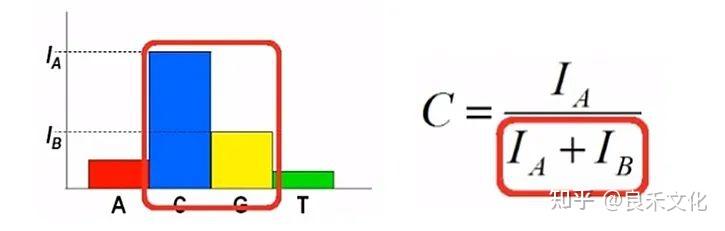
2、Chastity和Pass filter
1)Chastity
Chastity的定义,就是浓度最高的那个荧光素的量,去除以“它自己与排名第二的荧光素的量的和”,结果大于 0.6 是一个好碱基。
它的意义在于对光点当中荧光素的纯粹程度进行描述。
2)Pass filter
illumina对每个read的质量都要做一个pass filter检验。检验的标准是看前25个碱基当中,有几个是坏碱基。通过pass filter检验的标准是坏碱基数目不超过一个。
这个校验的作用,是去掉一个荧光点中,含多个cluster(read)的数据,留下纯粹的单克隆read,作为合格的数据交给用户。
PF data,指的就是Pass Filter(PF)的数据。而PF 率,则是指Pass Filter的Reads数占总的、测到的 Reads数的比例,它可以从一个侧面反映测序的质量。一般来说,如果上样密度过高,PF率就可能会下降。
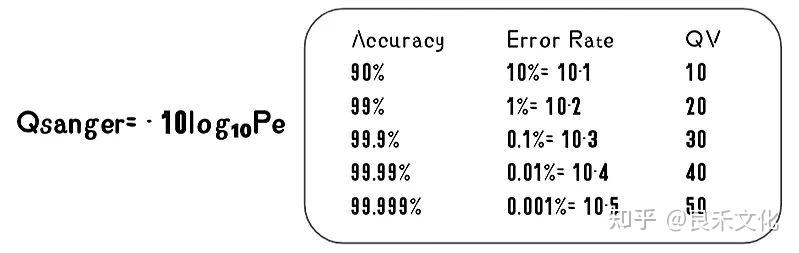
3、Quality Score
碱基的质量分数,即Q值,Sanger的定义是通过这个碱基被误判的可能性,换算出以 10 为底的对数,再乘以“-10”得到的这样一个数值。
1)Q30
常说的Q30,就是QV为30时对应一个碱基的可靠性达到99.9%。或者说,它的出错的可能性小于千分之一。同理,我们说Q40,就是指一个碱基的可靠性是99.99%。或者说,它的出错的可能性是万分之一。
2)Q30 比例
而所谓的Q30比例,就是在全部PF数据当中,达到或者超过Q30质量标准以上的数据占所有PF数据的比例。Q30比例可以表征一个测序过程的质量的好坏。一个碱基的质量分数,不是以数字方式,直接记录到最后的FastQ文件的。而是把它的Q值,加上 33,再用ASCII码表转换成一个字母,把这个字母录入FastQ文件。
二、Fastq与FastQC
1、Fastq格式
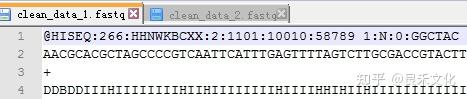
二代测序平台获得的原始数据为fastq(或为压缩文件fq.gz)格式,包含双端测序的2个read文件,每一个read包含四行内容。
第一行以@开头,后面是reads的属性信息,中间用“:”隔开。第二行为read的碱基序列信息。第三行以“+”开头,一般与@后面的内容相同,可以省略,但“+”一定不能省。第四行代表read每个碱基的测序质量。
例如上例中HISEQ为测序平台名称,266为测序运行run的编号,HHNWKBCXX为流通池(flowcell)编号。
接下来四个数字为位置信息:
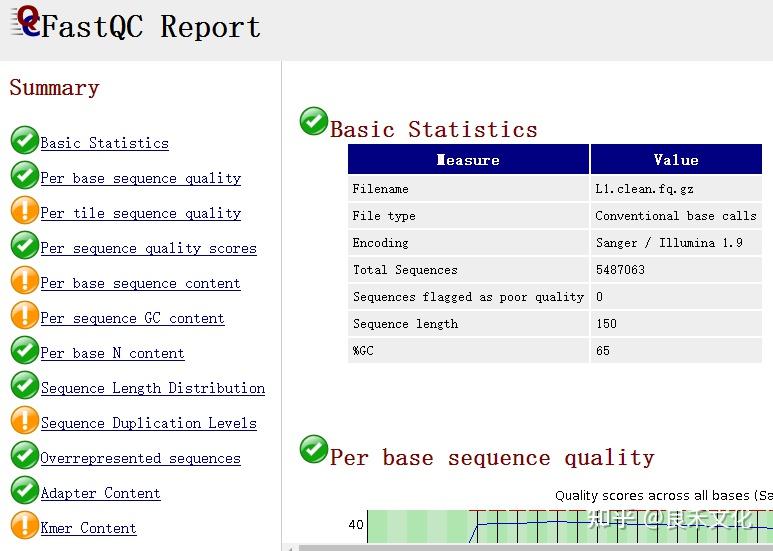
2、FastQC
对于新下机的原始数据,我们可以使用软件FastQC来对其测序质量进行质检。
质检报告包括有:
基因组/宏基因组鸟枪法测序数据reads比较随机均匀,碱基分布也会比较均匀,而扩增子数据由于两端都有引物,以及插入片段均为16S,所以会出现很多重复序列,且碱基分布非均匀。
PE表示paired-end数据的质量控制,SE也即single-end数据。
<hr/>
03
数据过滤
1、二代测序数据的指控步骤:raw reads→clean reads。
2、Trimmomatic工具的数据过滤步骤:
3、去除宿主序列
基于环境的复杂性与研究对象的不同,宏基因组数据在组装之前常需要过滤掉一些序列以防干扰研究。例如要研究动植物组织或肠道的微生物组,往往需要去除宿主的DNA序列。假如研究的是人类肠道微生物的宏基因组,需要去除属于人基因组的序列。具体方法为将质控后的序列和人类基因组序列进行比对,将比对上的序列去除。
参考文献:
[1]测序数据的解析:Fastq与FastQC-微生态与微进化
[2]《陈巍学基因》Hiseq测序仪工作原理
原文地址:https://zhuanlan.zhihu.com/p/1895053851008157385
回复
举报
返回列表
发表回复
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
分子仪器
病理检验
关闭
官方推荐
/3
AI助手<小桔子>来了!
欢迎来交流,可以回答IVD行业各类问题!
查看 »
IVD业界薪资调查(月薪/税前)
长期活动,投票后可见结果!看看咱们这个行业个人的前景如何。请热爱行业的桔友们积极参与!
查看 »
小桔灯网视频号开通了!
扫描二维码,关注视频号!
查看 »
返回顶部
快速回复
返回列表
客服中心
搜索
洽谈合作
关注微信
微信扫一扫关注本站公众号
个人中心
个人中心
登录或注册
业务合作
-
投稿通道
-
友链申请
-
手机版
-
联系我们
-
免责声明
-
返回首页
Copyright © 2008-2024
小桔灯网
(https://www.iivd.net) 版权所有 All Rights Reserved.
免责声明: 本网不承担任何由内容提供商提供的信息所引起的争议和法律责任。
Powered by
Discuz!
X5.0 技术支持:
宇翼科技
浙ICP备18026348号-2
浙公网安备33010802005999号
快速回复
返回顶部
返回列表

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-4-15 11:19
发表于 2025-4-15 11:19