种种现象表明,LLM其实已经学到了大量的知识,只是我们还没有找特别好的方法来开启它的能力,就好像今天的AI研究员就像古时候的炼金术师,在没有在原理层面突破之前,只能在一遍遍的实践中尝试不同的咒语去召回魔法。今天,ChatGPT好像找到了更好开启LLM能力的对齐方式,RLHF加GPT3.5,让AI产品化的能力提升了一截,但并不能说我们已经把LLM的能力完全发挥出来了。
因此,alignment的创新不会停止。Prompt、In Context Learning、Chain of Thoughts、Reinforcement Learning Human feedback,是整个行业多年来孜孜不倦努力下的阶段性产出。然而由于交互创新如此重要,我们不会停下创新的脚步。
LLM的创新是搜索引擎式的范畴还是AWS式的范畴
许多人谈论数据质量,但在简单交流后,发现大多数人仍然认为AI模型需要大量标注数据才能训练。实际上,NLP领域是在Masked Language Model的训练方式后,才得以扩展到如此规模,并衍生出一系列后续发展。MLM最大的特点是自监督,不需要真正的人工标注。其思想非常简洁,就是在现有的文本训练语料中,随机地遮盖掉一些词(准确来说是token),让模型来预测这些被遮盖掉的词。由于这些词事先是已知的,因此可以算作自监督学习。这种方法的好处是,可以大幅提升可用于训练的数据规模。对于理解语言模型来说,这一部分非常重要。如果感兴趣,可以进一步搜索相关资料进行学习。因此,所谓数据质量是指数据本身的优质程度,例如,Wikipedia的数据天然比reddit的要好一些。
算力的摩尔定律。很多年前,大家已经在说摩尔定律遇到了物理瓶颈,除非基础科学的突破,否则我们很快就无法在提升计算机的性能。但这几年我们看到GPU的发展很快,算力增长迅速。GPU和CPU一样,同样遇到了物理瓶颈,但GPU的场景天然是并行的,可以通过堆更多晶体管来缓解问题。这个领域涉略不深,在大模型时代,算力的需求侧不在存疑,算力的供给是否真的像大家预期的一样,成本快速下降,希望有更资深的人来解答算力这部分的问题。PS:最近看到一篇有意思的工作,Looped Transformer as Programmable Computers,在探讨是否有可能用Transformer做一个通用的计算机。前几年已经有人去证明transformer是图灵完备。
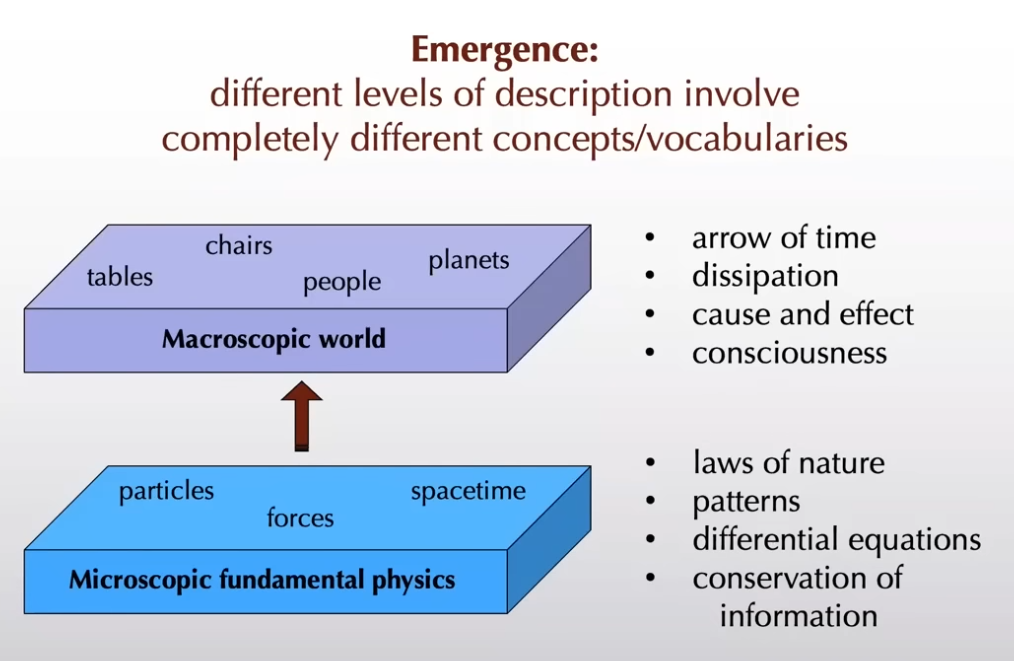
In philosophy, systems theory, science, and art, emergence occurs when an entity is observed to have properties its parts do not have on their own, properties or behaviors that emerge only when the parts interact in a wider whole.
Chemistry can in turn be viewed as an emergent property of the laws of physics. Biology (including biological evolution) can be viewed as an emergent property of the laws of chemistry. Similarly, psychology could be understood as an emergent property of neurobiological laws. Finally, some economic theories understand economy as an emergent feature of psychology.
今天晚上不务正业,花了一点儿时间看了两篇文章:
《Emergent Abilities of Large Language Models》[1]
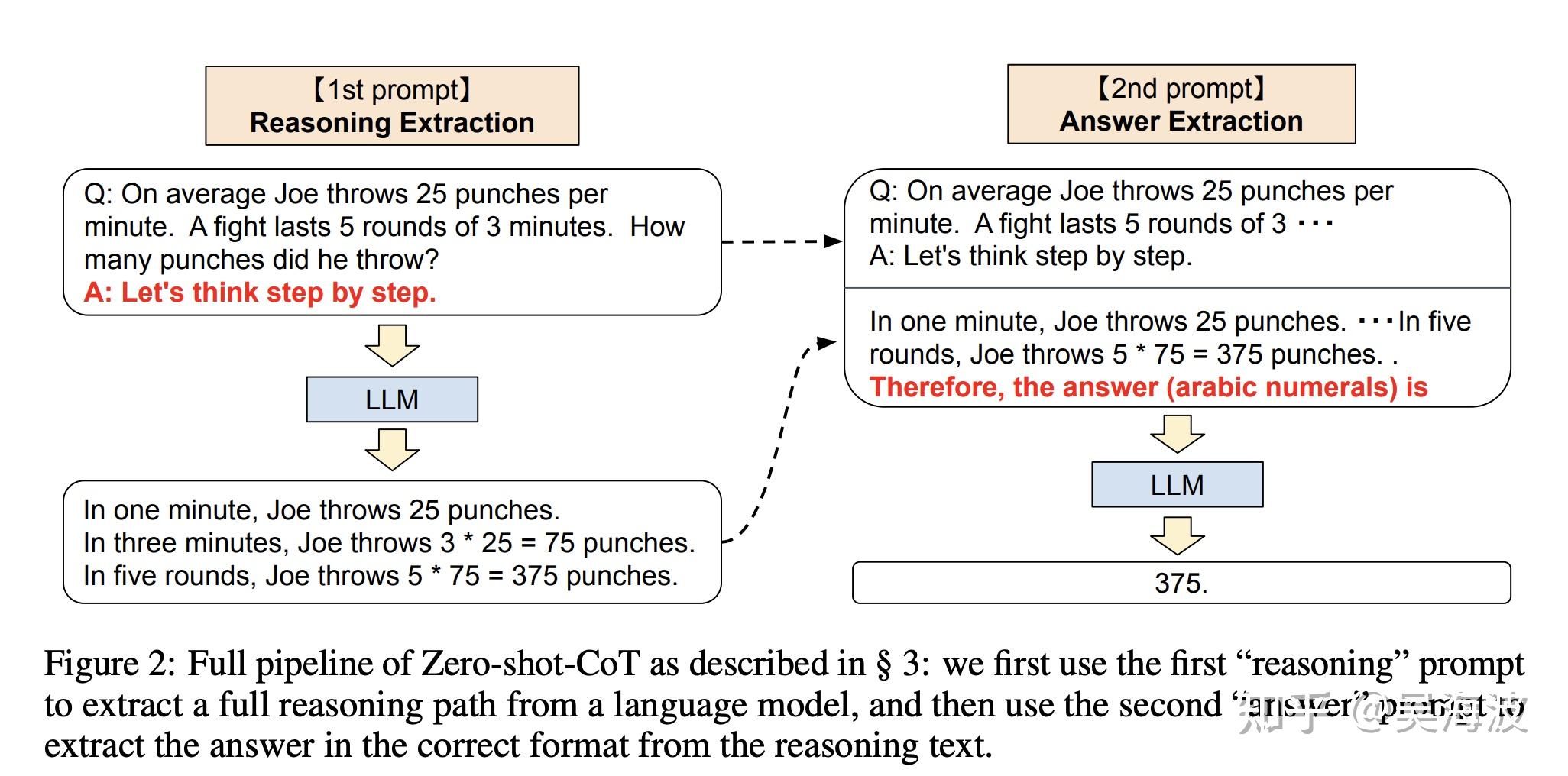
《PROGRESS MEASURES FOR GROKKING VIA MECHANISTIC INTERPRETABILITY》[2]
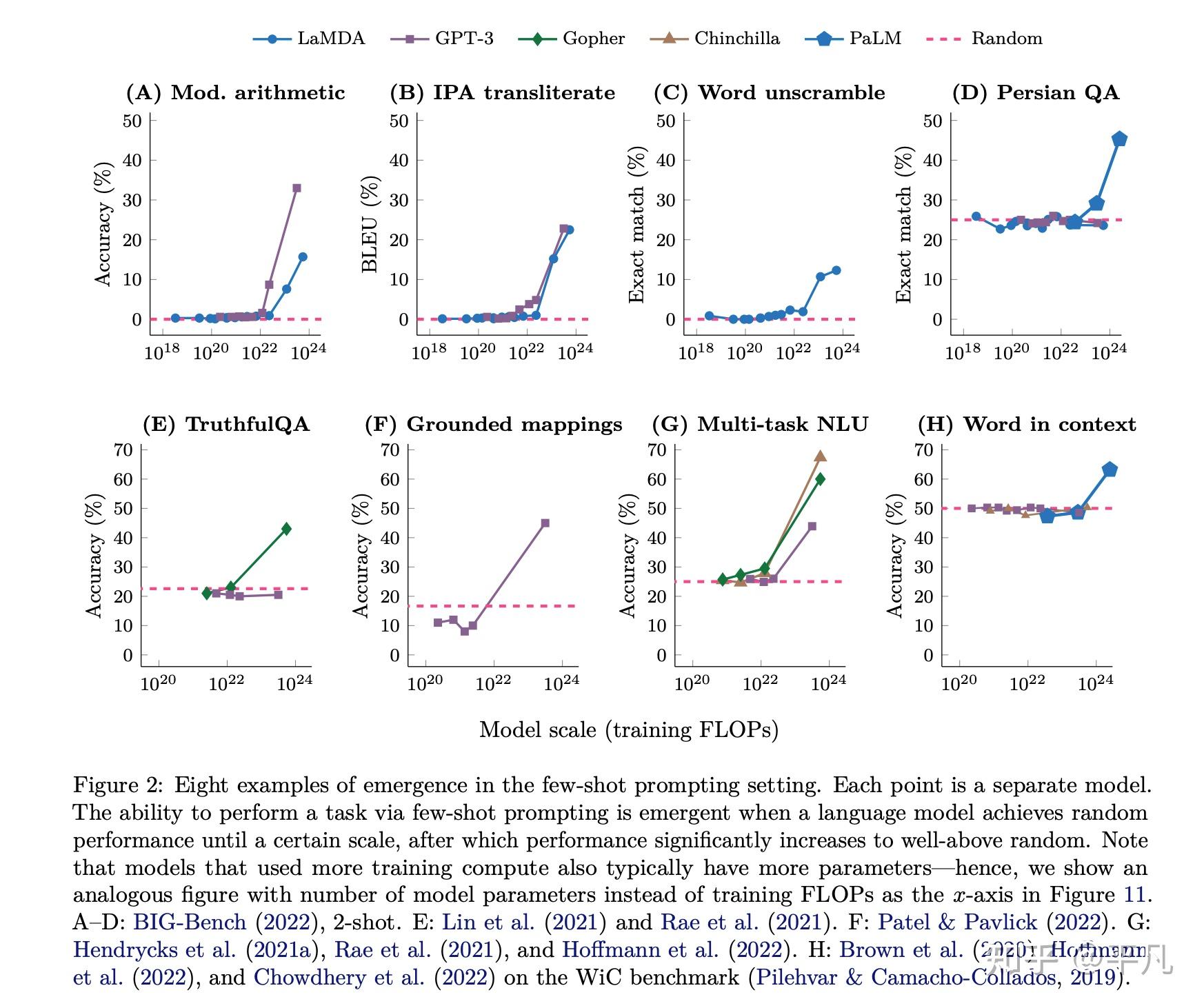
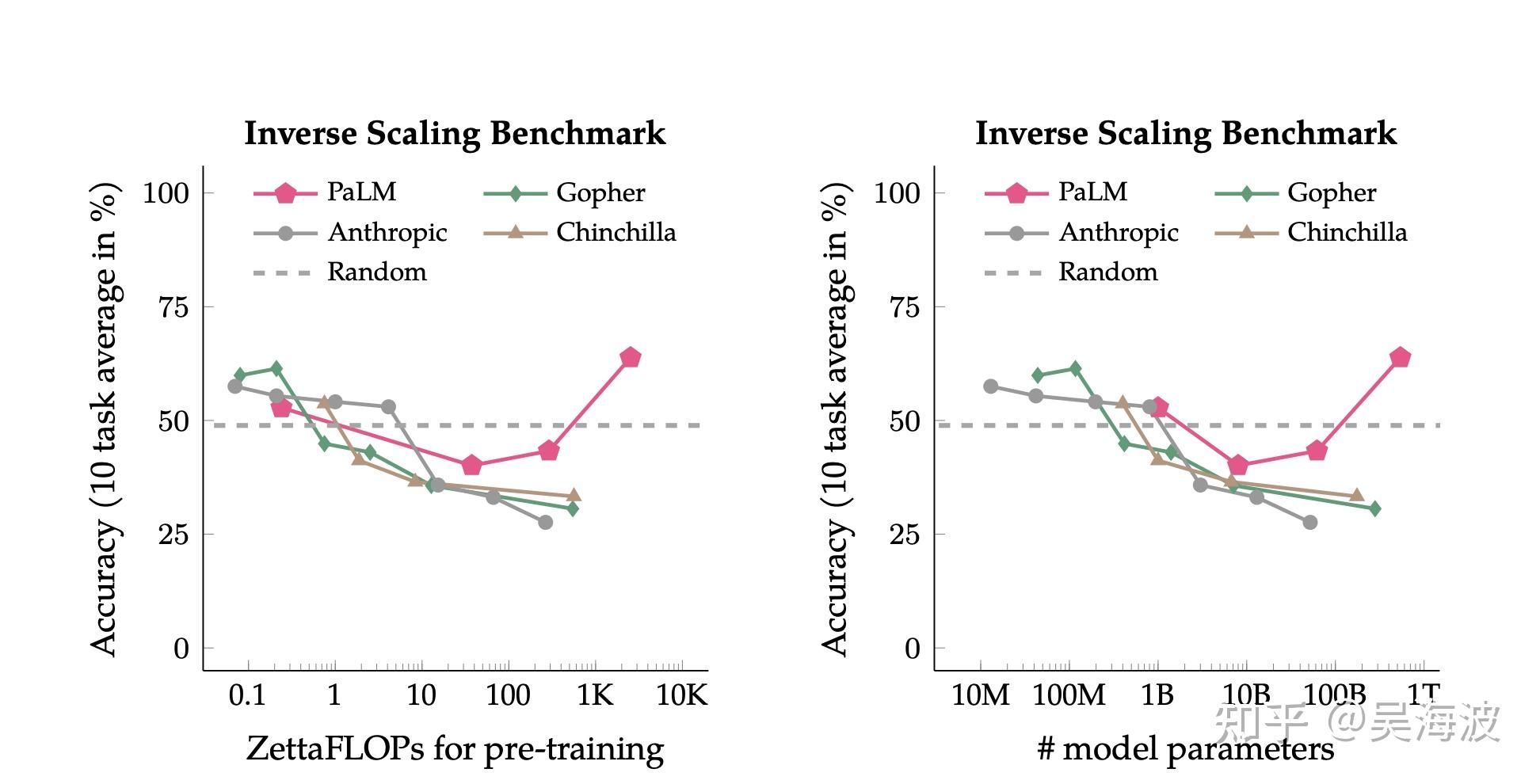
这两篇讲的都是emergent behavior,即涌现现象。
在机器学习中使用大规模神经网络时,由于增加了参数数量、训练数据或训练步骤等因素,出现了定性上的新能力和性质,这些能力和性质在小规模神经网络中往往是不存在的。
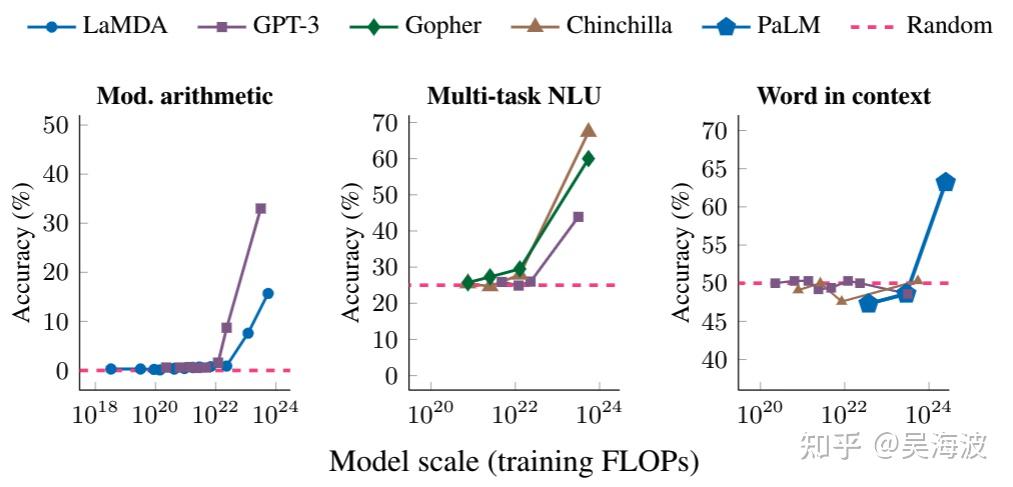
第一篇文章举了这个例子,每个图都可以理解为一个任务,横轴是神经网络的规模,而纵轴是准确率,可以理解为模型的性能。

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-3-31 22:45
发表于 2025-3-31 22:45


 提升卡
提升卡






 发表于 2025-3-31 22:46
发表于 2025-3-31 22:46