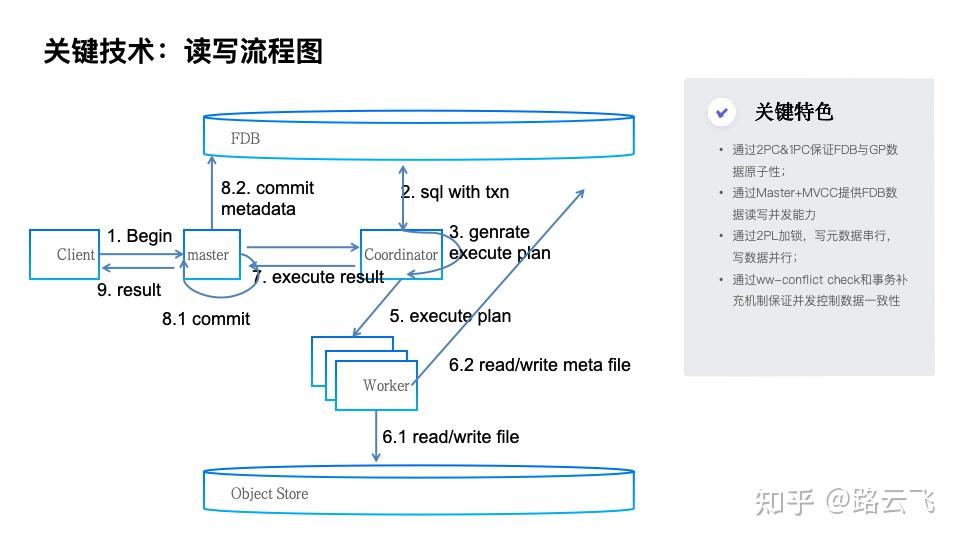
我们基本借鉴了PostgreSQL本身的MVCC算法,在此基础上根据上述数据结构调整。实现了基于KV的可见性判断算法:
/* tmp space自己事务的数据:可见性判断 */
/* t_xmin status = ABORTED 针对子事务*/
Rule 1: IF t_xmin status is 'ABORTED' THEN
RETURN 'Invisible'
END IF
/* t_xmin status = IN_PROGRESS */
IF t_xmin status is 'IN_PROGRESS' THEN
IF t_xmin = current_txid THEN
Rule 2: IF t_xmax = INVALID THEN
RETURN 'Visible'
Rule 3: ELSE /* this tuple has been deleted or updated by the current transaction itself. */
RETURN 'Invisible'
END IF
Rule 4: ELSE /* t_xmin ≠ current_txid */
RETURN 'Invisible'
END IF
END IF
/* work space数据:可见性判断 */
/* t_xmin status = COMMITTED */
IF t_xmin status is 'COMMITTED' THEN
Rule 5: IF t_xmin is active in the obtained transaction snapshot THEN
RETURN 'Invisible'
Rule 6: ELSE IF t_xmax = INVALID OR status of t_xmax is 'ABORTED' THEN
RETURN 'Visible'
ELSE IF t_xmax status is 'IN_PROGRESS' THEN
Rule 7: IF t_xmax = current_txid THEN
RETURN 'Invisible'
Rule 8: ELSE /* t_xmax ≠ current_txid */
RETURN 'Visible'
END IF
ELSE IF t_xmax status is 'COMMITTED' THEN
Rule 9: IF t_xmax is active in the obtained transaction snapshot THEN
RETURN 'Visible'
Rule 10: ELSE
RETURN 'Invisible'
END IF
END IF
END IF虽然实现具有一定的复杂性,但是好处是行为保持与PG的行为保持一致,降低了Relyt的学习成本。 Timetravel的实现

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-3-17 21:25
发表于 2025-3-17 21:25




 提升卡
提升卡


