金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
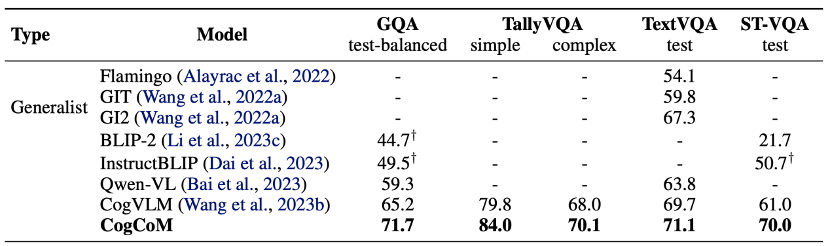
AGI的本质还是期待能获得一个无所不能的大语言模型,在这一年里我也是在这个领域探索和成长。在真实的环境中发现持续提升大模型的效果并不是一件很简单的事情,其中有很多关键的挑战和值得持续研究的方向,在此给大家分享一下。
其中pretraining的部分和 @王焱 @孙培钦 at鼎叮 进行的交流沟通
Pretraining部分
Data Collection
整个pretrain阶段最重要的部分就是数据收集,尽管OpenAI已经给我们了一套标准化的数据收集流程并也有很多开源机构给予了预训练数据(例如common crawl [1],starcoder等网络数据 [2]),但是
- 如何持续获取最新的互联网数据来更新模型的预训练知识,这是一个值得研究的重要问题。
- 模型如何针对新的互联网数据,主动发现和判断哪些数据是已经掌握的,哪些数据是新的知识,并进行自动地持续学习,这也是一个衍生出来的可能方向。
- 模型依据新获取的知识,如何更新相关一系列问题的答案,这也是一个比较有挑战的问题,举个例子,美国总统现在是谁,这个问题就是一直动态变化的,而2024年的答案也许和2018年的答案是冲突的,那么怎么依据2024年的新数据更新这个问题答案,也是一个non trivial的问题。
- 丰富的高质量数据获取是也是预训练阶段数据收集的一个重要研究方向。在Deepseek-math [3] 论文中,他们通过反复对common crawl数据进行清洗,提取丰富的高质量预训练数据,大大提升了其7B模型在math类bench mark的效果。这个实验也说明了,对于一个尺寸偏小的模型(7B以下)丰富的高质量的预训练数据是非常重要的,因为更小的模型容噪能力是偏低的,那么一个更加干净且丰富的数据集就显得尤为重要。
Data Organization
整个预训练数据收集完毕后,如何组织成为结构化的预训练数据供给模型训练是现阶段很多科研机构研究的方向。
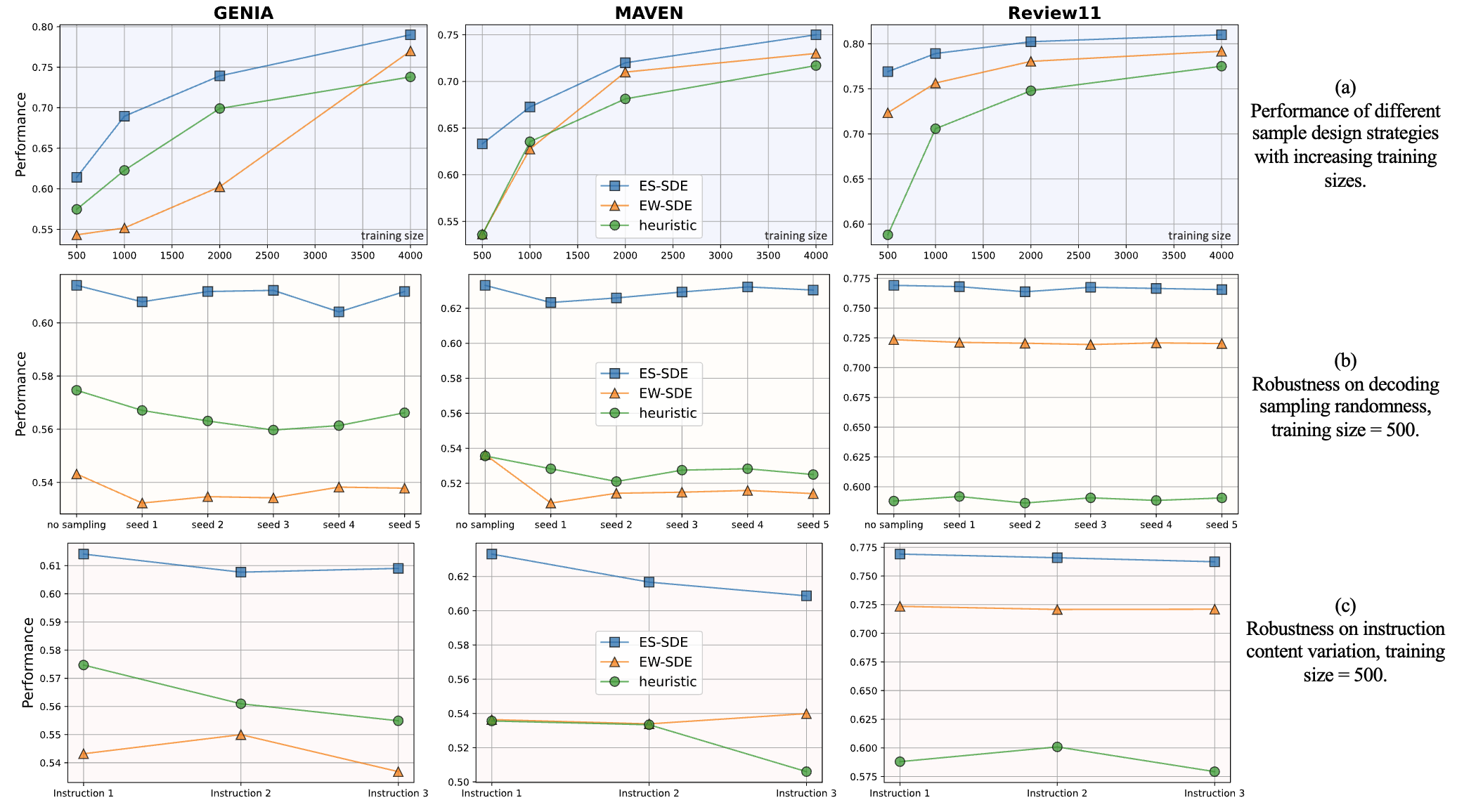
5. 如何通过数据的依赖关系组织预训练数据可以最大限度地让模型学习到存储在预训练数据的知识,这是现阶段大家最关注的方向。其中构造更长依赖的文本数据似乎是现阶段的一个突破口,更长的文本依赖可以激活模型更丰富的attention模式,以及可以激活模型更强的reasoning的能力。例如,In context pretraining [4] 文章通过将相关的文本构建在一起,来提升模型的reasoning能力,还有Deepseek Coder [5] 也将多个code文件组合在一起成为repo-level的code文本,以获得模型更强的code能力。
6. 如何组织高质量文本进入预训练阶段,最大化发挥这些高质量数据也是数据组织的一个比较重要的方向。比如minicpm公司在预训练的第二阶段,也就是lr退火阶段加入了高质量的数据(包括sft数据,高质量code数据等)[6],在benchmark上获取了非常大的提升。但是否该仅在退火阶段加入高质量数据,以及高质量数据的比例如何和低质量数据进行混合也是比较值得研究的方向之一。
7. 数据组织的组织格式的一些小的技巧。尽管这个问题听上去很trivial,是一些工程上的事情,但从实际提升效果的角度,也许这是尤其重要的环节。比如训练code里的python代码,选四个空格还是TAB作为你的缩进token,比如数学中的公式应该是用latex表示还是其它形式。这些选择里一定有更利于模型学习的形式,而且很可能某个trick对小模型的智能提升会有很大作用。期待有一篇可以和李牧老师的imagenet training trick [7] 媲美的论文揭露这些trick。
Synthetic Data Generation
合成数据的生成现在是一个业界和学界重点关注的问题,这个方向其实和知识蒸馏,知识编辑以及数据飞轮都有一定关系。
8. 如何通过合成数据的方式蒸馏一个大模型的知识(比如GPT4),是现阶段大家比较关注的点。由于很多著名机构会在预训练数据阶段购买很多高价值的数据,在对齐阶段引入大量人工标注,使得包括GPT4在内的很多模型的能力很强。但是对于没有这么多资源的公司或者开源机构,如何通过明文的方式蒸馏GPT4的能力,补充自己的大模型能力,这是一个非常重要的方向。现在大量的工作都是利用sft阶段来引入GPT4的能力,比如metamath [8],wizardcoder [9] 等工作。但是我认为这个问题可能比想象得困难,因为对于不同预训练数据的底座模型,蒸馏的困难程度会非常高,你需要从对齐后的模型去想办法还原出pretrain模型在某一方面的能力。(比如你很难在对齐后的模型还原模型在长文本上的续写能力)。
9. 如何通过合成数据的方式蒸馏一个大模型的知识进入一个小模型,这也是个很有趣的问题。这个问题和8的区别可能在于模型的预训练数据是否一致。对于预训练数据一致的模型,其实这种明文蒸馏也许效率和效果上可能可以媲美soft的方式的蒸馏,类似于GPT4(3.5)-turbo应该都是采取了这种方式蒸馏。当然在蒸馏过程中,如何选择合适的prompt,来作为传输手段把大模型的所有知识蒸馏到小模型上,这是一个比较重要的点。
10. 如何通过纯合成数据进行预训练,对齐来获得某个子方向的专精模型,这是一个最近很多公司在做的任务。微软的phi系列 [10] [11] 在这个方向上做的比较深入,他们模型从pretrain到sft,甚至是rm都是合成数据做出来的。但是这样的做法的短板也很明显,模型对于prompt的鲁棒性比较低。
Metrics in Pretraining
Pretrain Model 本质是一个中间产物,它只有一定的续写能力,它最终需要服务于downstream task。那么怎么评估Pretrain Model需要一定的手段和方法。除此之外,对于数据的质量,丰富度的评估的metric也是缺失的,这样对于我们数据选择就会有影响。
11. 预训练评估metric,以及这些metric与下游任务的关系。尽管现在预训练模型有很多维度的metric,比如math的GSM8k,Code的human eval,推理的MMLU数据集 [1]。但是这些数据集效果的提升和下游任务的关系是怎么样的?以及是否有更合理更高效的预训练评估的metric是值得深入研究的方向。
12. 数据质量和丰富度的metric。尽管我们知道数据质量和丰富度在pretrain阶段依然重要,但是如何衡量数据的质量和丰富度,依然缺少有说服力的metric。以及我个人认为不同的方向也许有不同的数据质量的定义。著名的Deepseek coder & math [3][5] 就是以pretrain数据质量高闻名,但是什么是高质量数据,他们的论文中也没有详细描述和体现。所以我觉得数据质量和丰富度的metric是未来很值得研究的方向。
Scaling Law & 超参数选择
听说当年Open-AI就是靠着Scaling-Law来说服投资者相信AGI的,尽管Open-AI的论文以及后续一系列论文已经把这个方向探索得比较清楚,但Scaling law这个方向仍然有一些值得探索的地方。
13. 每个子方向(code,math,通用等)的loss收敛和benchmark预测都是符合一套公式么?在star-coder-v2中,他们在小模型上训练了接近3.3 to 4.3 trillion tokens得到最好的benchmark效果 [2],这个数字远超了Chinchilla给予的最佳训练量,这个也说明了不同类型的数据的超参数选择也许是不一样的,不同方向也许存在specific得scaling law。
14. loss曲线的变化和超参数选择以及优化器的选择的关系。比如面壁智能在自己的分享中介绍了training loss会在lr退火阶段迅速下降,并设计了新的变化lr机制,方便进行post-pretrain [6]。
在这部分我主要介绍了pretraining相关业界比较关心的能提升模型效果的问题和可能的方向。希望大家有任何想法和有趣的问题也可以提出来分享。
[1] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[2] Lozhkov A, Li R, Allal L B, et al. StarCoder 2 and The Stack v2: The Next Generation[J]. arXiv preprint arXiv:2402.19173, 2024.
[3] Shao Z, Wang P, Zhu Q, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models[J]. arXiv preprint arXiv:2402.03300, 2024.
[4] Shi W, Min S, Lomeli M, et al. In-Context Pretraining: Language Modeling Beyond Document Boundaries[J]. arXiv preprint arXiv:2310.10638, 2023.
[5] Guo D, Zhu Q, Yang D, et al. DeepSeek-Coder: When the Large Language Model Meets Programming--The Rise of Code Intelligence[J]. arXiv preprint arXiv:2401.14196, 2024.
[6] MiniCPM:揭示端侧大语言模型的无限潜力.
[7] He T, Zhang Z, Zhang H, et al. Bag of tricks for image classification with convolutional neural networks[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 558-567.
[8] Yu L, Jiang W, Shi H, et al. Metamath: Bootstrap your own mathematical questions for large language models[J]. arXiv preprint arXiv:2309.12284, 2023.
[9] Luo Z, Xu C, Zhao P, et al. Wizardcoder: Empowering code large language models with evol-instruct[J]. arXiv preprint arXiv:2306.08568, 2023.
[10] Gunasekar S, Zhang Y, Aneja J, et al. Textbooks are all you need[J]. arXiv preprint arXiv:2306.11644, 2023.
[11] Li Y, Bubeck S, Eldan R, et al. Textbooks are all you need ii: phi-1.5 technical report[J]. arXiv preprint arXiv:2309.05463, 2023.
<hr/>接上一篇,本篇会列举对齐策略中SFT比较值得研究的方向和需要解决的问题。先给一个粗浅的认识,其实SFT可能是整个LLM流程中最容易做的过程,或者说是难度和收益都比较低的一个过程。尽管OpenAI建议大家只做SFT去微调模型,以及大量的公司focus在SFT数据构建上,但我个人认为,SFT里可能只起一个指令遵循的作用。除此之外,无论是知识蒸馏还是提升LLM效果都不该期待在SFT中完成。这个认知大概也是我个人在实践一年大模型效果优化中形成的。Anyway,其实SFT做指令遵循依然有很多具有挑战的问题和值得继续研究的方向。
SFT部分
How to construct a suitable SFT data for a specific pretrained language model ?
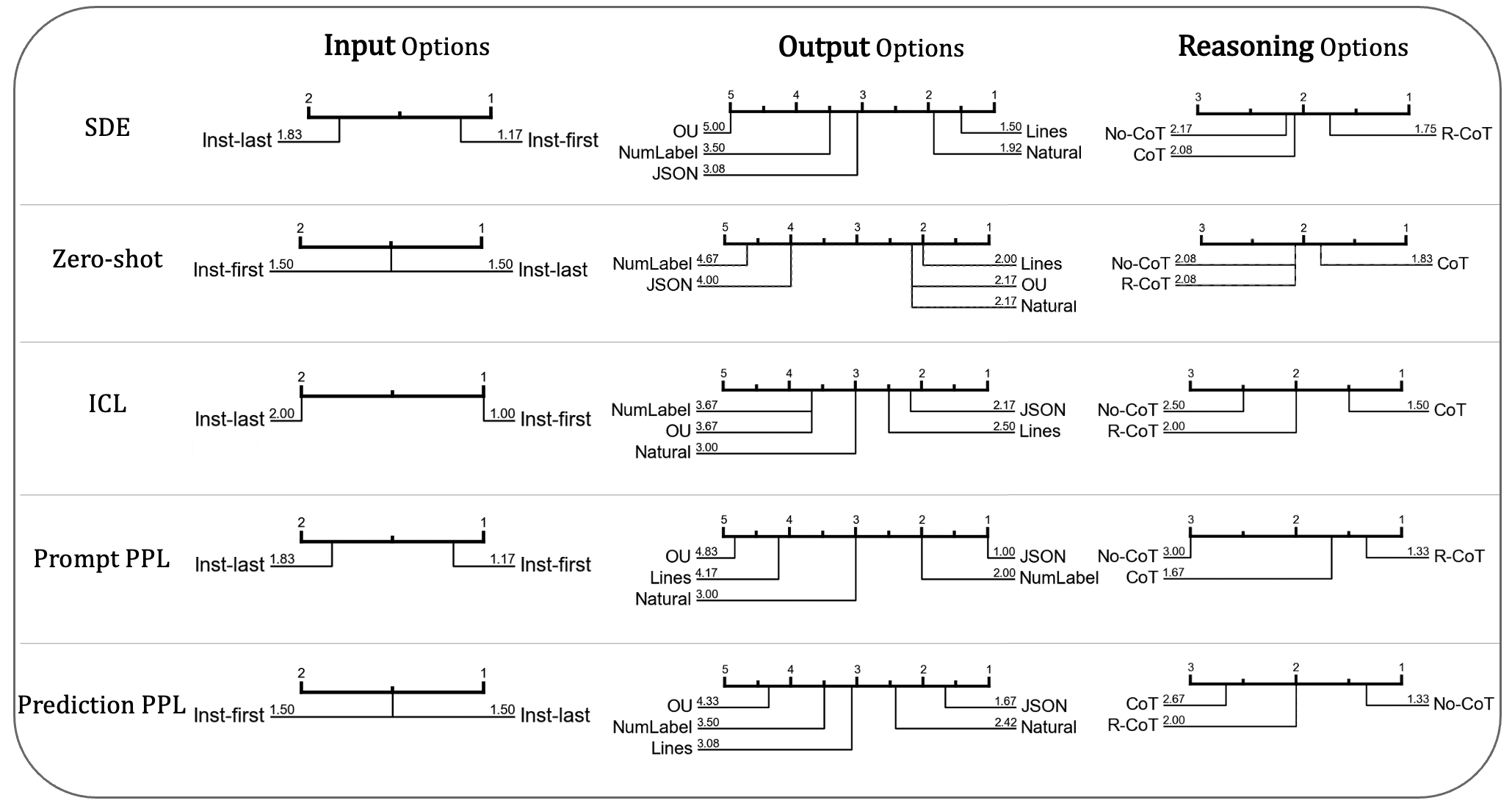
13. 如何选择合适的query来构造SFT数据。假设你有一个query数据集合,选择合适的query作为sft的prompt现在是SFT方向的主要工作。这个类型工作的开山鼻祖是LIMA [1],他们通过质量和diversity选择1k query集合,beat了万级别的query集合。后续有一些延续的工作。比如:
- Embedding based method:Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning [2]. 阿里的这篇论文主要从query的diversity出发,从一个子集合慢慢扩展开来到一个大query集合。他们主要靠模型内部embedding表示的距离衡量query的diversity。对于embedding based method,我个人觉得未来主要研究方向应该集中在挑选更能表示模型内部对prompt的表征的embedding,如何加入answer的embedding表征,以及如何找出更高效的挑选方法。
- Tag based method:InsTag [3] 利用给不同的query打tag,然后从动词维度和名词维度对query数据去重。这个工作的好处就是可解释性很强,但缺点是如何收集tag,打tag以及tag的准确性问题很难保证。Instag这个工作也是focus在query的diversity。我个人觉得未来主要研究方向应该集中在Tag打标工具更能和模型本身能力结合,以及如何调整不同Tag下prompt的分布来提升模型的效果。
- Complexity based method:对于同意的query,其实并不一定要进行语意去重,可以通过升级query complexity的方式来提升query的diversity。比较著名的是 Wizard LM [4],利用5种prompt从不同维度来升级query的complexity。但是一味对难度的升级并不能提升query的语意覆盖度,其次过高的complexity的query,如果模型pretrain本身的能力不够,反而会损害sft后模型的效果。升级难度的这一系列工作,未来的方向可能是根据模型的能力对于特定的query进行难度升级,而不是全部升级。
14. 如何为选定的query获取合适的answer?假设已经选择好合适的query集合,如何获取相应的answer来建立合适的sft数据集。现阶段比较多的方法有三类:
- 人工改写pretrain生成的续写结果,这个应该是原始open-ai使用的方式,但这种方式需要人工很多,现在使用的人比较少。
- 利用GPT4生产结果,这个是现在比较多的公开dataset使用的方式,比如Wizard LM [4]等,这个方向主要研究方向还是如何提升GPT4的生成质量,来保证sft结果的正确性?例如 Self Repair等工作 [5]。
- 利用一些生产环境筛选pretrain生成的续写结果,这个是code,math类型sft数据的筛选方法。Code llama [6]就是采用这个方式筛选sft数据的。这个方法的未来发展方向,是如何建立多种多样的生产环境(或者global rm model 或者是更强的world model)来筛选数据。
15. 如何在公开数据的sft dataset的筛选合适模型的sft数据。
毕竟获取query和answer是一个成本极高的事情,那么如果可以从开源的一系列数据中筛选合适自己模型的sft数据会比较低成本。
- Hybrid Method (混合了多种之前列举的指标和方法。):例如 What Make Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning [7] 文章,从complexity,diversity和quality三个方向对sft数据建模,训练了多个模型对各个指标维度进行分别衡量。我觉得混合式方法一定是最终会采取的方式,那么如何高效得混合策略,将是混合方法的一个方向。因为过复杂过重的数据筛选方式不适合实际场景。
- 利用sft model和pretrain model的关系筛选模型的sft数据。因为pretrain model和sft model我们是可以获得的,那么利用sft model和 pretrain model中prompt下answer的概率变化是可以直接建模出来的(贝叶斯学派)。那么通过这个建模可以更好的筛选sft数据,比如IFD [8] 方法。那么更好地建模pretrain model,sft data 和 sft model的关系,然后通过这个建模筛选sft data,也是一个值得研究的方向。
How to efficiently do supervised fine-tuning ?
16. 如何混合不同的SFT数据?
- 不同方向的sft数据混合:对于理科和文科的SFT数据混合是一个比较特殊的方向,由于第一版本的chatgpt是在codex基础上继续训练的,所以对于理科文科sft是否也应该先训理科后训文科,还是应该混合训一直是个疑问。对于这个问题已有的paper是来自于千问团队的 HOW ABILITIES IN LARGE LANGUAGE MODELS ARE AFFECTED BY SUPERVISED FINE-TUNING DATA COMPOSITION [9],他们提出数学和代码应该先训,然后在训通用sft数据的时候再加少量代码和数学的sft数据。但由于他们的base model是Llama2,其本身的数学和代码能力就不太好,所以可能结果也不solid。因此不同方向的sft数据混合仍应该继续研究。
- 不同sft数据集合的配比问题:SFT数据集以及pretrain数据集的配比问题一直有researcher在研究,但现在的pretrain数据配比过于精细化的配比也许会过于拟合benchmark。尽管sft数据配比也有此问题,但sft方向至少有一个值得研究的问题,就是难易数据的配比问题。其中比较著名的sft数据配比的paper是skill-it [10],通过skill建模评估数据集,通过模型loss来确定各个阶段对eval数据中skill的学习情况,然后确定最终sft数据配比。但整个过程建模有些繁琐,在过大的模型,过复杂的eval set上不太实用。所以,怎么在大模型上高效地解决sft数据配比问题是一个值得研究的方向。
- 不同类型sft数据的互相促进关系?尽管有很多说法,code,math会提升模型整体的推理能力。但是并没有一篇论文完整地讨论各个方向sft数据互相之间的促进减弱关系,因此这是一个很值得深入研究的方向。
17. 如何做SFT packing,以及不同SFT packing对模型的效果的影响?
这个方向其实看到的论文非常少。虽然现阶段为了充分利用batchsize的token计算量,SFT数据会像pretrain 数据一样,pack在一起。一般比较简单的做法,就是暴力地连接在一起,多余的数据进行截断。比较精巧的方法是block diagonal attention [11]。总体而言,sft packing对整体sft后模型效果的影响,是值得研究的方向之一。
How to design the format of sft data ?
18. 对于不同类型的数据,什么样的data format能够激发模型更好的泛化能力?
对于math的sft数据,COT data or (detailed scratchpad data) [12] 可以更好地激发模型的数学能力。但是其余关于代码,通用类的data format并没有很多细致地研究。那么如何设计合理的sft data format来激发模型各个方向对齐后的能力,是未来值得研究的方向之一。
[1] Zhou C, Liu P, Xu P, et al. Lima: Less is more for alignment[J]. Advances in Neural Information Processing Systems, 2024, 36.
[2] Wu S, Lu K, Xu B, et al. Self-evolved diverse data sampling for efficient instruction tuning[J]. arXiv preprint arXiv:2311.08182, 2023.
[3] Lu K, Yuan H, Yuan Z, et al. # InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models[C]//The Twelfth International Conference on Learning Representations. 2023.
[4] Xu C, Sun Q, Zheng K, et al. Wizardlm: Empowering large language models to follow complex instructions[J]. arXiv preprint arXiv:2304.12244, 2023.
[5] Olausson T X, Inala J P, Wang C, et al. Demystifying gpt self-repair for code generation[J]. arXiv preprint arXiv:2306.09896, 2023.
[6] Roziere B, Gehring J, Gloeckle F, et al. Code llama: Open foundation models for code[J]. arXiv preprint arXiv:2308.12950, 2023.
[7] Liu W, Zeng W, He K, et al. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning[J]. arXiv preprint arXiv:2312.15685, 2023.
[8] Li M, Zhang Y, Li Z, et al. From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning[J]. arXiv preprint arXiv:2308.12032, 2023.
[9] Dong G, Yuan H, Lu K, et al. How abilities in large language models are affected by supervised fine-tuning data composition[J]. arXiv preprint arXiv:2310.05492, 2023.
[10] Chen M, Roberts N, Bhatia K, et al. Skill-it! a data-driven skills framework for understanding and training language models[J]. Advances in Neural Information Processing Systems, 2024, 36.
[11] Qiu J, Ma H, Levy O, et al. Blockwise self-attention for long document understanding[J]. arXiv preprint arXiv:1911.02972, 2019.
[12] Lee N, Sreenivasan K, Lee J D, et al. Teaching arithmetic to small transformers[J]. arXiv preprint arXiv:2307.03381, 2023.
<hr/>接上一篇,本篇会列举对齐策略中RLHF比较值得研究的方向和需要解决的问题。RLHF可能真的算是整个LLM比价难和吃纯技术的一个方向,相比于pretrain更多的来源于对混沌未知的洞见(除了scaling law以外,可能还没有特别有指导性的工作),SFT来源于精细化处理和更多的人工干预,那么RLHF则是需要多年的技术积累和丰富的理论保证。个人从16年开始做RL,包括理论的,学术的,业务线的RL都做过很多,之前多少有点对RL的落地有些失落,但RLHF的出现真都让我感受到奥特曼所谓的compound effect。给一个比较直观的感受,RLHF一定是AGI皇冠上的明珠,它决定了对齐后模型的上限。下面列举了我认为RLHF未来值得研究的方向:
RLHF部分
Online Algorithm 问题:
19. 提升online algorithm的efficiency的问题, 这里首先需要解决的就是online algorithm的efficiency的问题。因为online algorithm一个过程就是on policy的采样,和reward model对这些采样打分。但是如果采样的过程和打分的过程非常耗时,那么会拉长整体模型的训练时常。无论是PPO [1]和iterative DPO [2]都逃避不了这样的问题。在Instruct GPT[3] 中使用的是小型的reward model,小型的reward model就是为了降低打分过程的耗时。那么如何提升algorithm的采样和打分耗时问题会是一个重要研究方向,个人认为可以做模型performance和efficiency的trade-off。
20. 如何优化PPO算法的GPU显存占比?由于PPO里需要有4个模型,policy model,value model,ref policy model和reward model。如果四个模型同大小且需要同时放入GPU显存里,那么一个PPO过程的GPU显存占比会需要4个大模型的大小,对于现阶段算力来说是十分吃紧的。deepseek math[4]试图将value model去掉,使用类似Reinforce算法里baseline的算法,直接通过batch的平均预测值当作state baseline(value model的预测的state value)。但这种方法会使得PPO失去credit assign的能力,不利于最终模型的效果。除此之外Lora-based 方法,以及混合式Lora based 算法[5]也有人提出,但这类型case在解决编辑距离较低的response pair会有模型表达能力不够的情况。所以如何降低PPO的GPU显存占比且不伤害模型效果,是一个未来研究的重要方向。
21. PPO的reward hacking问题?在PPO过程中,尽管reward持续增加,但是很容易会发现模型会突然输出一些不符合人类价值观的输出,本质还是找到了达到reward 最高的捷径(比如length bias [5]等),但并不符合人类价值观。尽管这里有一部分是reward model的问题,一部分也是PPO这个模型灵活度过高,容易hack reward而不是generalize reward。现有一些思路还是做一些reward hack的惩罚项 [6],但是我觉得没有找到问题地根本。如何修改PPO使得它可以找到一个generalize reward的方案或者regularize的方案,而不是one by one地增加惩罚项,将是未来一个研究方向。
22. PPO的稳定性问题?PPO的稳定性问题一直是被人诟病最多的问题之一,这里超参数的调整简直是炼丹,前有OpenAI公布一些小游戏上的stabe-ppo baseline[7],现在大模型中,调参数使得其稳定更是有很多trick,有一些工作已经开始focus在这个问题上了[8]。因此如何找出PPO稳定性的trick,在RLHF算法届十分值得研究。
23. Online RLHF的停止问题?因为现在默认RLHF的上限就是pretrain model的上限,但是本质Online RLHF是可以无限更新的,但是何时模型已经到了pretrain model的上限,何时继续更新虽然reward在上升(这个和21有一些联系,但21也许不要early stop),但是效果不再提升了。这样既可以提升模型效果防止reward hacking,还可以减少模型训练量,最后也可以评价rm 模型做到如何程度就可以了。因此如何直接选择一个指标衡量决定何时停止Online RLHF是一个重要研究方向。
Offline Algorithm
尽管Online Algorithm是现在公认效果最好的算法簇,但是Offline Algorithm依然有很大的市场和影响力。主要原因还是Online Algorithm资源消耗太大,很多公司和研究者负担不起。
23. 如何利用Offline算法完成On-policy的采样?这个问题似乎现在已经有了很好的答案,就是做Iterative的offline算法[9]。但是依然需要探讨的问题可能是,如何选择Iteration的评次和轮数,或者定义一个指标去规约Offline Model在一个iteration里不能过于偏离Ref Model。
24. 如何设计一个好的Offline Algorithm?其实Offline Algorithm一直是RL里一个重要方向,因为毕竟在任何一个系统中做RL都有sample efficiency问题。曾经的一系列解法主要focus在Importance Sampling[10],Natural Policy Gradient[11], One step TRPO和One step PPO[12]。但这些算法好像还未引入到RLHF中,而且我觉得RLHF其实是个可以self-reward的model[13][14],但好像很少Offline Algorithm 在深入利用这部分的性质改进Offline Algorithm。如何利用Offline Dataset的分布以及LLM模型的特性设计适合LLM的Offline Algorithm是一个值得研究的方向。
25. DPO算法的改造?尽管DPO这个算法本身很成熟,而且有很多工作试图对齐改造,包括loss方向的:IPO[15]和DPOP[16],采样方向的:Iterative DPO[2]和RSO[17], 样本构造方向的:KTO [18], RLCD[19]和Self-reward [14]。但是还是没有解决DPO的一些其他问题,例如Token的Credit Assign问题。那么持续地改造提升DPO算法,会是一个很好的方向。
[1] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.
[2] Xiong W, Dong H, Ye C, et al. Gibbs sampling from human feedback: A provable kl-constrained framework for rlhf[J]. arXiv preprint arXiv:2312.11456, 2023.
[3] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744.
[4] Shao Z, Wang P, Zhu Q, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models[J]. arXiv preprint arXiv:2402.03300, 2024.
[5] Shen W, Zheng R, Zhan W, et al. Loose lips sink ships: Mitigating length bias in reinforcement learning from human feedback[J]. arXiv preprint arXiv:2310.05199, 2023.
[6] Chen L, Zhu C, Soselia D, et al. ODIN: Disentangled Reward Mitigates Hacking in RLHF[J]. arXiv preprint arXiv:2402.07319, 2024.
[7] https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html
[8] Zheng R, Dou S, Gao S, et al. Delve into ppo: Implementation matters for stable rlhf[C]//NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following. 2023.
[9] Guo S, Zhang B, Liu T, et al. Direct language model alignment from online ai feedback[J]. arXiv preprint arXiv:2402.04792, 2024.
[10] Tokdar S T, Kass R E. Importance sampling: a review[J]. Wiley Interdisciplinary Reviews: Computational Statistics, 2010, 2(1): 54-60.
[11] Kakade S M. A natural policy gradient[J]. Advances in neural information processing systems, 2001, 14.
[12] Ghraieb H, Viquerat J, Larcher A, et al. Single-step deep reinforcement learning for open-loop control of laminar and turbulent flows[J]. Physical Review Fluids, 2021, 6(5): 053902.
[13] Yuan W, Pang R Y, Cho K, et al. Self-rewarding language models[J]. arXiv preprint arXiv:2401.10020, 2024.
[14] Liu A, Bai H, Lu Z, et al. Direct Large Language Model Alignment Through Self-Rewarding Contrastive Prompt Distillation[J]. arXiv preprint arXiv:2402.11907, 2024.
[15] Azar M G, Rowland M, Piot B, et al. A general theoretical paradigm to understand learning from human preferences[J]. arXiv preprint arXiv:2310.12036, 2023.
[16] Pal A, Karkhanis D, Dooley S, et al. Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive[J]. arXiv preprint arXiv:2402.13228, 2024.
[17] Liu T, Zhao Y, Joshi R, et al. Statistical rejection sampling improves preference optimization[J]. arXiv preprint arXiv:2309.06657, 2023.
[18] Ethayarajh K, Xu W, Muennighoff N, et al. Kto: Model alignment as prospect theoretic optimization[J]. arXiv preprint arXiv:2402.01306, 2024.
[19] Yang K, Klein D, Celikyilmaz A, et al. Rlcd: Reinforcement learning from contrast distillation for language model alignment[J]. arXiv preprint arXiv:2307.12950, 2023.
未完待续… 下一章Reward Model |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-3-14 10:46
发表于 2025-3-14 10:46