金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
在用 OLS 估计出参数 \hat{w} 后,我们需要检验 \hat{w} 在模型中是噪音还是真的重要,把握又有多少,也就是最小二乘法的假设检验(参数检验),本文将重点讨论 t 检验和 F 检验,这两个检验和卡方分布、t 分布、F 分布有重要关系,因此这三个分布也会谈到。
这篇文章先在专栏上晾几天,修改后和上篇文章合并上传 GitHub。
最小二乘法的性质及假设
在前几篇 OLS 文章中,我们证明了,对于模型
y_i = w_0 + w_1x_{i1} + w_2x_{i2} + \epsilon_i \\
可用矩阵形式表示为
y = Xw + \epsilon\\
若以下假设满足:
假设 1:存在线性关系 y = Xw + \epsilon;
假设 2: X 为确定值,且满秩可逆,即不存在共线性(Multicollinearity);
假设 3:误差项均值为 0,\mathrm{E}(\epsilon) = 0;
假设 4:误差项同方差(homoscedastic), \mathrm{Var}(\epsilon_1)=\mathrm{Var}(\epsilon_2)...=\mathrm{Var}(\epsilon_i)=\sigma^2 ;
假设 5:误差项不相关(uncorrelated), \forall i \neq j, \mathrm{Cov}(\epsilon_i,\epsilon_j)=0 。假设 4 和假设 5 可合并为 \mathrm{Var}(\epsilon) = \sigma^2I 。
可以推导出最小二乘法估计得到的 \hat{w} 无偏且为最佳无偏线性估计(BLUE),注意,因为误差项是随机变量,这里的 \hat{w} 也是随机变量。
\begin{split} \hat{w} &= (X^TX)^{-1}X^Ty = w + (X^TX)^{-1}X^T\epsilon \\ \mathrm{E}(\hat{w}) &= w \\ \mathrm{Var}(\hat{w}) &= \sigma^2 (X^TX)^{-1} \end{split}\\
并得到 \sigma^2 的无偏估计 \hat{\sigma}^2 为
\hat{\sigma}^2 = \frac{\hat{\epsilon}^T\hat{\epsilon}}{n - k} = \frac{RSS}{n - k}\\
\Large \epsilon 的分布
\epsilon 是模型无法预测的误差值,它与 X 无关,对于数量少的样本,我们假设误差呈正态分布。
假设 6:各误差项 \epsilon 服从均值等于 0,方差为 \sigma^2 的正态分布,即 \epsilon \sim \mathcal{N}(0, \sigma^2I)。
为什么假设 \epsilon 呈正态分布?第一个原因是,对于噪音而言,正态分布是最常见的分布;第二个原因是,根据中心极限定理,随着样本数量增加,\frac {\hat{w}_j - w_j} {s.e.(w_j)} 的分布趋近于标准正态分布,和假设 \epsilon 服从正态分布的结果一致,最小二乘法的一致性(consistency)和渐进性(asymptoticy)我以后再作文解释。
由此可以推导 \hat{w} 和 \hat{\sigma}^2 的分布,这些结论将帮助我们对 \hat{w} 进行假设检验。
The weekend starts here.
\Large \hat{\sigma}^2 的分布
在「\sigma^2 的无偏估计」部分,我们得到了
\begin{split} \hat{\sigma}^2 = \frac{\hat{\epsilon}^T\hat{\epsilon}}{n - k} = \frac{RSS}{n - k} = \frac{\epsilon^TM\epsilon}{n - k} \end{split}\\
在「\epsilon的分布」部分,我们假设\epsilon \sim \mathcal{N}(0, \sigma^2I),可得
\frac{\epsilon}{\sigma} \sim \mathcal{N}(0, I_n)\\
包上对称矩阵(symmetric matrix)和幂等矩阵(idempotent matrix)M,结果服从卡方分布,这个卡方分布的参数(自由度)为 \mathrm{rank}(M)=\mathrm{trace}(M)=n-k,表示为
\frac{\epsilon^T}{\sigma} M \frac{\epsilon}{\sigma} \sim \mathcal{\chi}_{n-k}\\
该结果也等价为
\frac{\epsilon^T M \epsilon}{\sigma^2} \sim \mathcal{\chi}_{n-k}\\ \frac{\hat{\epsilon}^T\hat{\epsilon}}{\sigma^2} \sim \mathcal{\chi}_{n-k}\\ \frac{RSS}{\sigma^2} \sim \mathcal{\chi}_{n-k}\\ \frac{\hat{\sigma}^2(n-k)}{\sigma^2} \sim \mathcal{\chi}_{n-k}\\
至于卡方分布及其参数是如何得到的,我在下一部分给出简要证明,第一遍阅读的读者可以跳过。
卡方分布的矩阵形式
n 个独立且服从标准正态分布的随机变量,Z_j \sim \mathcal{N}(0, 1),将它们平方再求和得到V = Z_1^2 + Z_2^2 + ... + Z_n^2,V 服从卡方分布(chi-square distribution),显然 V 的分布形态只和 n 有关,也就是说,卡方分布仅接受一个参数n,这里的 n 称为自由度,即 V \sim \mathcal{\chi}^2_n。
用矩阵形式表示卡方分布,z为n个独立且服从标准正态分布的随机变量Z_j组成的随机向量。
\begin{split} z &= \begin{bmatrix} Z_1 \\ \vdots\\ Z_n \end{bmatrix} \quad z \sim \mathcal{N}(0, I)\ \end{split}\\
A 为对称矩阵,向量 q 表示为
q = z^TAz\\
对称矩阵 A 通过特征值分解,分解成对角矩阵(diagonal matrix)\Lambda 和正交矩阵(orthogonal matrix)C,可参考 MIT 线性代数的 Diagonalization 和 Symmetric Matrices and Positive Definiteness 章节。
q = z^TC \Lambda C^Tz\\
由于正态分布的性质,对 x \sim \mathcal{N}(\mu, \Sigma),可得 Ax+b \sim \mathcal{N}(A\mu+b, A\Sigma A^T)。由于 z \sim \mathcal{N}(0, I),可得
C^Tz \sim \mathcal{N}(0, C^TIC)\\
结合正交矩阵(orthogonal matrix)的性质,C^TC = I,可得
C^Tz \sim \mathcal{N}(0, I)\\
设 y = C^Tz,由上式可知 y 也服从标准正态分布,对角矩阵(diagonal matrix)\Lambda 的形式为
\Lambda = \begin{bmatrix} \lambda_1 \ldots 0 \\ \vdots \ddots \vdots\\ 0 \ldots \lambda_n \end{bmatrix}\\
因此
q = y^T\Lambda y = \lambda_1 y_1^2 + \lambda_2 y_2^2 + ... + \lambda_n y_n^2\\
如果各元素 \lambda_1...\lambda_n 等于 1 或 0,值为 1 的 \lambda 的数量 j = \lambda_1 + ... + \lambda_n决定了 q 中有 j 项平方相加,也决定了 q 的分布形态,j 就是自由度。
q \sim \mathcal{\chi}_{j}\\
举个例子,r = y^T\Lambda y = \lambda_1 y_1^2 + \lambda_2 y_2^2 + \lambda_3 y_n^2 = 1 \times y_1^2 + 0 \times y_2^2 + 1 \times y_3^2,这里 r 的自由度就是 2。
r \sim \mathcal{\chi}_{2}\\
在「\sigma^2的无偏估计」部分,我们得到的M是对称矩阵(symmetric matrix)和幂等矩阵(idempotent matrix),当上式的 A=M,幂等矩阵 M 分解后的对角矩阵(diagonal matrix)\Lambda 各元素 \lambda_1...\lambda_n 等于 1 或 0,且 j = \lambda_1 + ... + \lambda_n = \mathrm{trace}(M) = \mathrm{rank}(M) = n-k,因此可得
\frac{\epsilon^T}{\sigma} M \frac{\epsilon}{\sigma} \sim \mathcal{\chi}_{n-k}\\
以及
\frac{\hat{\sigma}^2(n-k)}{\sigma^2} \sim \mathcal{\chi}_{n-k}\\
上述证明我只涉及了关键部分,详细证明可参考 Econometric Analysis / William H. Greene p.1044 和这个知乎答案。
\Large \hat{w} 的分布
我们已知 \hat{w} = w + (X^TX)^{-1}X^T\epsilon,并假设 \epsilon \sim \mathcal{N}(0, \sigma^2I),w 和 X 均为确定值,因此 \hat{w} 也呈正态分布。在前几篇文章里,已经证明 \hat{w} 均值和方差分别为 w 和 \sigma^2 (X^TX)^{-1},即
\hat{w} \sim \mathcal{N}\big(w, {\sigma}^2 (X^TX)^{-1}\big)\\
用标量形式表示,随机向量 \hat{w} = \begin{bmatrix}\hat{w}_0\\\vdots\\\hat{w}_{k-1}\end{bmatrix},\hat{w}_j 的均值为 w_j,方差为协方差矩阵 {\sigma}^2 (X^TX)^{-1}对角线上的第 j 项 {\sigma}^2 (X^TX)^{-1}_{jj},即
\hat{w}_j \sim \mathcal{N}\big(w_j, {\sigma}^2 (X^TX)^{-1}_{jj}\big)\\
正态分布仅取决于均值和方差,结合均值和方差的计算性质,上式变换为
\frac{\hat{w}_j - w_j}{\sqrt{\sigma^2(X^TX)^{-1}_{jj}}} \sim \mathcal{N}(0,1)\\
t 检验
n 个独立且服从标准正态分布的随机变量,Z_j \sim \mathcal{N}(0, 1),将它们平方再求和得到V = Z_1^2 + Z_2^2 + ... + Z_n^2,得V \sim \mathcal{\chi}^2_n。
Y 为独立于 V 且服从标准正态分布的随机变量,Y \sim \mathcal{N}(0, 1),通过下式变换得到自由度为 n 的 t 分布(Student's t-distribution)。
T = \frac{Y}{\sqrt{V/n}} \sim \mathcal{t}_n\\
t 分布(Student's t-distribution)的由来也很有趣,发现者 William Sealy Gosset 当时为吉尼斯啤酒厂(对就是吉尼斯世界纪录的吉尼斯)工作,吉尼斯不希望竞争对手发现自己雇了统计学家,所以 William Sealy Gosset 化名 Student 发表论文,论文成果因此得名 Student's t-distribution。Gosset 为人谦逊且崇拜好友 R. A. Fisher(也就是下文 F-distribution 的发现者),他如此评价自己的发现:「反正 Fisher 也会算出这个分布的(Fisher would have discovered it all anyway)。」
Gosset 曾在伯明翰大学学过酿酒技术,写这篇文章的时候我就在学校图书馆地底下的 Costa 喝咖啡续命,这里敬他一杯。
前面已证明
\frac{\hat{w}_j - w_j}{\sqrt{{\sigma}^2(X^TX)^{-1}_{jj}}} \sim \mathcal{N}(0,1)\\
以及
\frac{\hat{\sigma}^2(n-k)}{\sigma^2} \sim \mathcal{\chi}_{n-k}\\
因此,使 Y = \cfrac{\hat{w}_j - w_j}{\sqrt{(X^TX)^{-1}_{jj}}},V = \frac{\hat{\sigma}^2(n-k)}{\sigma^2},可得
t_j=\frac {{\hat{w}_j - w_j}\Big/{\sqrt{{\sigma}^2(X^TX)^{-1}_{jj}}}} {\sqrt{{\hat{\sigma}^2(n-k)}\big/{\sigma^2(n-k)}}} \sim \mathcal{t}_{n-k}\\
n-k 和 \sigma^2 消掉,得到
t_j=\frac {\hat{w}_j - w_j} {\sqrt{\hat{\sigma}^{2}(X^TX)^{-1}_{jj}}} \sim \mathcal{t}_{n-k}\\
\hat{\sigma}^{2}(X^TX)^{-1}_{jj} 是 w_j 方差 \mathrm{Var}(w_j) 的估计值 \widehat{\mathrm{Var}(w_j)},\sqrt{\hat{\sigma}^{2}(X^TX)^{-1}_{jj}} 是 \widehat{\mathrm{Var}(w_j)} 的平方根,称为 w_j 的标准误(standard error),因此上式简写为
t_j=\frac {\hat{w}_j - w_j} {s.e.(w_j)} \sim \mathcal{t}_{n-k}\\
对于模型 y = w_0 + w_1x_1 + ... w_jx_j ... w_{k-1}x_{k-1},比如说,w_j 是房子面积,我们需要通过数据解答房子面积 w_j 是否显著影响房价,对 w_j 进行假设检验(显著性检验),作如下假设
H_0\colon w_j=0\\ H_1\colon w_j \neq 0\\
若 H_0 成立,带入 t_j 可得
t_j=\frac {\hat{w}_j} {s.e.(w_j)} \sim \mathcal{t}_{n-k}\\
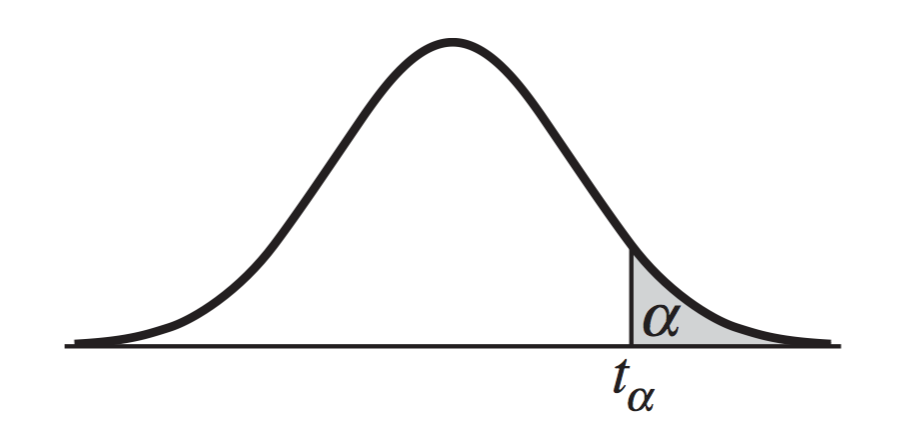
注意这里是双边检验(two-sided test),在表格中找到对应显著值 \alpha(significance value)的 t_{\alpha/2},由此得出 w_j=0 条件下 \hat{w}_j 的概率是否低于 \alpha,如果低于 \alpha,则拒绝 H_0,采纳 H_1,参数 w_j 显著,面积影响房价;如果高于 \alpha,则无法拒绝 H_0,参数 w_j 不显著,面积不影响房价。
t 检验也可以用矩阵形式,上文中的 w_j=0 是 w 的线性变换,等价于
H_0\colon \begin{bmatrix}0 \cdots 1 \cdots 0\\\end{bmatrix}\begin{bmatrix}w_0\\ \vdots\\ w_j\\\vdots\\w_{k-1}\\\end{bmatrix} = 0\\
对于模型 y = w_0 + w_1x_1 + w_2x_2 + w_3x_3,如果我们要检验假设 w_1+w_2=1,等价于
H_0\colon \begin{bmatrix}0\ 1\ 1\ 0\\\end{bmatrix}\begin{bmatrix}w_0\\ w_1\\ w_2\\w_3\\\end{bmatrix} - 1 = 0\\
线性变换后的假设可以写作
H_0\colon Rw - r = 0\\ H_1\colon Rw - r \neq 0\\
R 是 1 \times k 的行向量,r 是标量,因此 Rw - r 也是标量,我们已知
\hat{w} \sim \mathcal{N}\big(w, {\sigma}^2 (X^TX)^{-1}\big)\\
由于正态分布的性质,对 x \sim \mathcal{N}(\mu, \Sigma),可得 Ax+b \sim \mathcal{N}(A\mu+b, A\Sigma A^T)。因此若 H_0\colon Rw - r = 0 成立,随机变量 R\hat{w} - r 的分布为
R\hat{w} - r \sim \mathcal{N}\big(0, R{\sigma}^2 (X^TX)^{-1}R^T\big)\\
因此
\frac {R\hat{w} - r}{\sqrt{R{\sigma}^2(X^TX)^{-1}R^T}} \sim \mathcal{N}\big(0, 1)\\
由此可得 t 分布
t=\frac {{R\hat{w} - r}\Big/{\sqrt{R{\sigma}^2(X^TX)^{-1}R^T}}} {\sqrt{{\hat{\sigma}^2(n-k)}\big/{\sigma^2(n-k)}}}= \frac {R\hat{w} - r}{\sqrt{R\hat{\sigma}^2(X^TX)^{-1}R^T}} \sim \mathcal{t}_{n-k}\\
之后的假设检验步骤和标量形式相同,不再赘述。
F 检验
如果同时检验两条以上的假设,我们需要 F 检验,举例来说,有模型y = w_0 + w_1x_1 + w_2x_2 + w_3x_3,我们想检验模型整体显著,H_0 \colon w_1=w_2=w_3=0,这其实是假设 w_1 = 0,w_2=0 和 w_3=0 同时成立。和 t 检验类似,用 Rw - r = 0 的形式表示为
\begin{bmatrix} 0\ 1\ 0\ 0 \\ 0\ 0\ 1\ 0\\ 0\ 0\ 0\ 1 \end{bmatrix} \begin{bmatrix}w_0\\ w_1\\ w_2\\w_3\\\end{bmatrix}- \begin{bmatrix} 0\\ 0\\ 0 \end{bmatrix} = \begin{bmatrix} 0\\ 0\\ 0 \end{bmatrix}\\
但这里的 R 为 p \times k 的矩阵,r 为 p \times 1 的列向量。
对于形状 p \times 1 为 p \times 1随机向量 g \sim \mathcal{N}(\mu, \Sigma), 用「卡方分布的矩阵形式」部分提到的特征值分解,变换得到自由度为 p 的卡方分布(chi-square distribution)。
(g-\mu)^T\Sigma^{-1}(g-\mu) \sim \mathcal{\chi}_p\\
随机向量 R\hat{w} - r 是形状为 p \times 1 随机向量,分布为
R\hat{w} - r \sim \mathcal{N}\big(Rw - r, R{\sigma}^2 (X^TX)^{-1}R^T\big)\\
因此
\frac{(R\hat{w} - r)^T{[R(X^TX)^{-1}R^T]}^{-1}(R\hat{w} - r)} {{\sigma}^2} \sim \mathcal{\chi}_p\\
前文已得
\frac{\hat{\sigma}^2(n-k)}{\sigma^2} \sim \mathcal{\chi}_{n-k}\\
对于随机变量 X 和 Y,X \sim \mathcal{\chi}_a,Y \sim \mathcal{\chi}_b,
通过下式变换得到参数为 a、b 的 F 分布(F-distribution)。
F = \frac{X/a}{Y/b} \sim F_{a,b}\\
将上面两个卡方分布拼起来,可得
\begin{split} F &= \frac{{(R\hat{w} - r)^T{[R(X^TX)^{-1}R^T]}^{-1}(R\hat{w} - r)} \big/{p{\sigma}^2}}{{\hat{\sigma}^2(n-k)}\big/{\sigma^2(n-k)}} \\ &= \frac{{(R\hat{w} - r)^T{[R(X^TX)^{-1}R^T]}^{-1}(R\hat{w} - r)}}{p\hat{\sigma}^2} \sim F_{p,n-k} \end{split}\\
\hat{\sigma}^2 = \frac{RSS}{n-k},因此上式还可写作
\begin{split} F &= \frac{{(R\hat{w} - r)^T{[R(X^TX)^{-1}R^T]}^{-1}(R\hat{w} - r)}\big/p}{RSS\big/(n-k)} \\ &=\frac{(RSS_r - RSS_u)\big/p}{RSS_u\big/(n-k)}\sim F_{p,n-k} \end{split}\\
这个形式在初级计量经济学教材里更常见,特地写出,就不给出详细解释了。之后的假设检验步骤和 t 检验相同,不再赘述。
原文地址:https://zhuanlan.zhihu.com/p/36782834 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-3-12 13:20
发表于 2025-3-12 13:20
 提升卡
提升卡


