金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
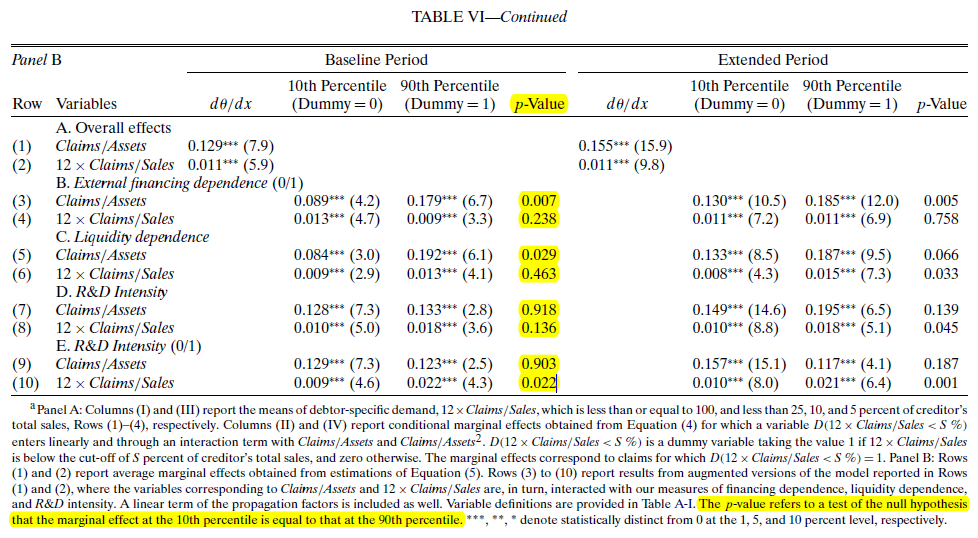
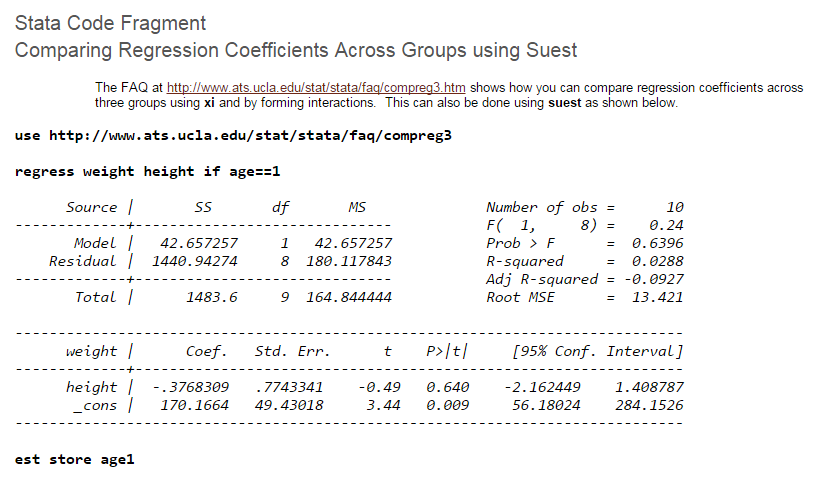
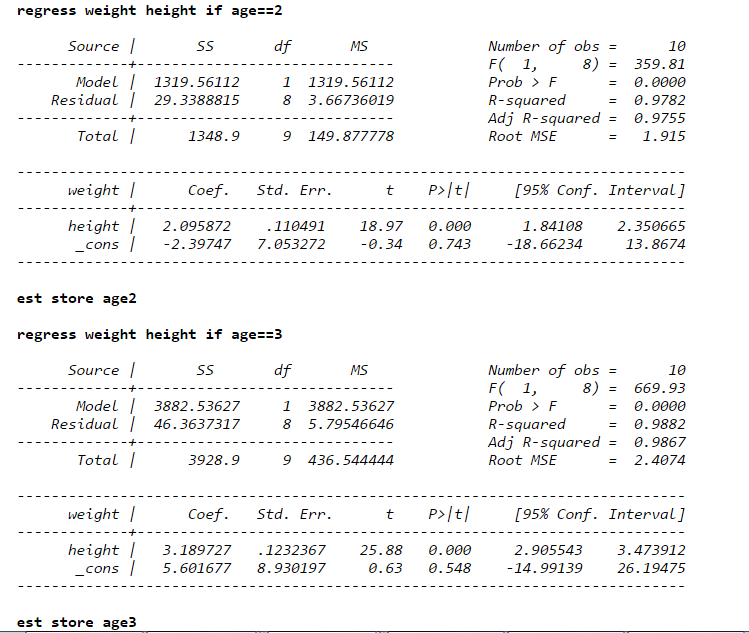
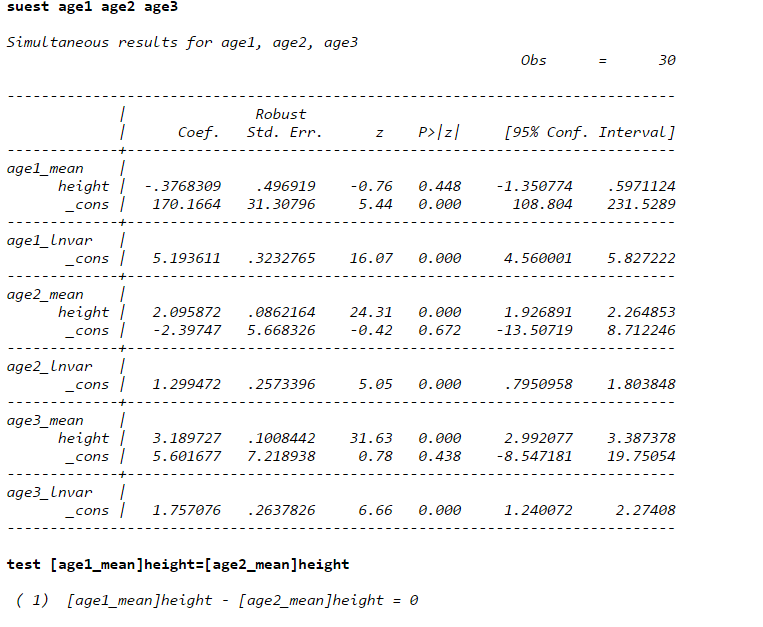
如果你想比较两组的系数是否一致,加虚拟变量。没有别的办法了。分开做的大有人在,但是没办法做这两个的系数检验。要想检验,就得放在一起加虚拟变量。
===================
科普,反对
@徐惟能的答案。
他对Hausman test的理解有偏误。
Hausman test的应用场景:存在同一组系数的两个估计b1 b2,满足:
在H0的条件下,b1 b2均一致,但是b1是最有效的
在H1的条件下,b1 是不一致的,但是b2是一致的
Hausman证明了,在H0的条件下,var(b2-b1)=var(b2)-var(b1)
故而可以构造统计量,(b2-b1)(var(b2)-var(b1))^(-1)(b2-b1)~chi2
比如,检验线性回归是不是有内生性:
H0:不具有内生性
H1:具有内生性
那么b1 就是ols回归结果,b2就是iv的回归结果。
同样,检验固定效应还是随机效应,b1是随机效应结果,b2是固定效应结果。
但在这里例子中,显然不满足Hausman test的前提
所以。。。绝对不能用Hausman test
============================
@徐惟能给出的wiki的网址,摘抄一下:
Consider the linear model y = bX + e, where y is the dependent variable and X is vector of regressors, b is a vector of coefficients and e is the error term. We have two estimators for b: b0 and b1. Under the null hypothesis, both of these estimators are consistent, but b1 is efficient (has the smallest asymptotic variance), at least in the class of estimators containing b0. Under the alternative hypothesis, b0 is consistent, whereas b1 isn’t. 翻译一下就是我说的意思。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-3-11 17:55
发表于 2025-3-11 17:55



 发表于 2025-3-11 17:58
发表于 2025-3-11 17:58