金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
只想浇盆冷水,别人已经深度学习、各种大模型轮番上阵,bioinformatics还在用CS背景用剩下的技术来找挖掘点…
合作一段时间后,一些纯生物背景的人(很可能还是控制funding的人)还在和你信誓旦旦的说,这东西计算机支撑不起来,最终还是得回归wetlab blah blah blah
作为一个计算机背景的毕业生,你所面临的同侪竞争压力一般来自那些和你背景类似的CS同学,而并不是绝大多数做bioinformatics的人。你的同学在毕业后,一部分去了互联网企业,数年之后也有一些开始创业(例如张一鸣),或者走到了管理岗位。留在学术界的人,无论是纯理论还是交叉方向,很多人都会找到自己喜欢的研究领域,数理功底会上一个台阶。例如非常有名的The PhD Grind,把这方面的体验写的入木三分。bioinformatics作为一个交叉领域,的确也有一部分人在做算法优化、深度学习、分布式计算等等这些东西。但是大部分组更偏向生物或者医学应用,因为交叉学科的关系,研究深度恐怕比不上纯CS的组。有些人肯定要怼,我在xx那里也做深度学习/云计算/数据库安全…,几个conference我都有被接收的文章。你说的对,但是这些组其实本质上做的是computer science的事情,他们招的人绝大多数也是纯CS背景的学生,和一般情况下的bioinformatics的组有区别。打个比方,统计学院的biostatistics其实做的还是统计方面的工作,和纯生物组的生物统计难度是不一样的,两者的publication目标也不同。
真的建议每个计算机转生信的人,好好看一下互联网企业对于人工智能的应用方向和相关技术。从deep learning, AlphaGo到ChatGPT,哪一个不是瞬间突破了很多人的固有思维?这才叫做技术突破。
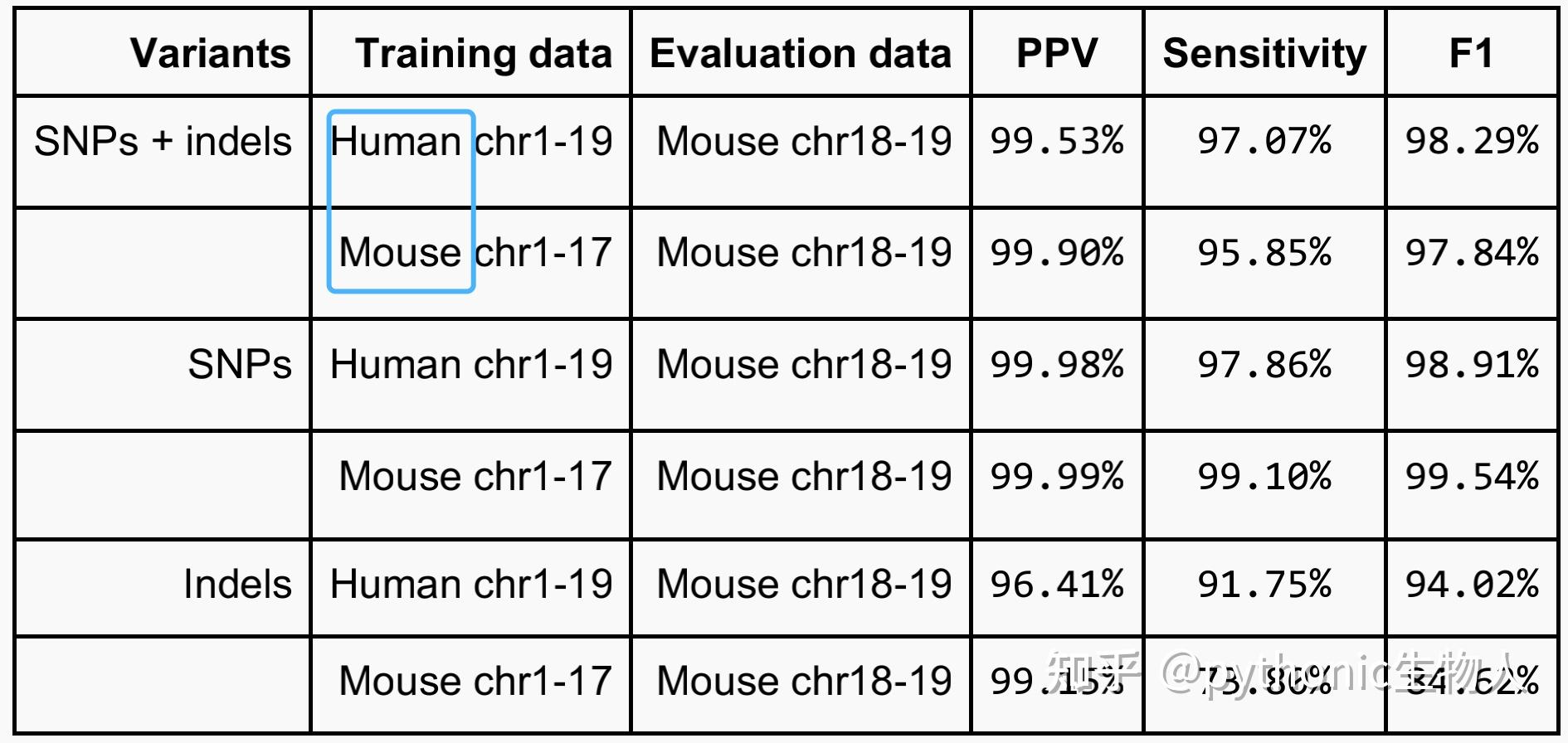
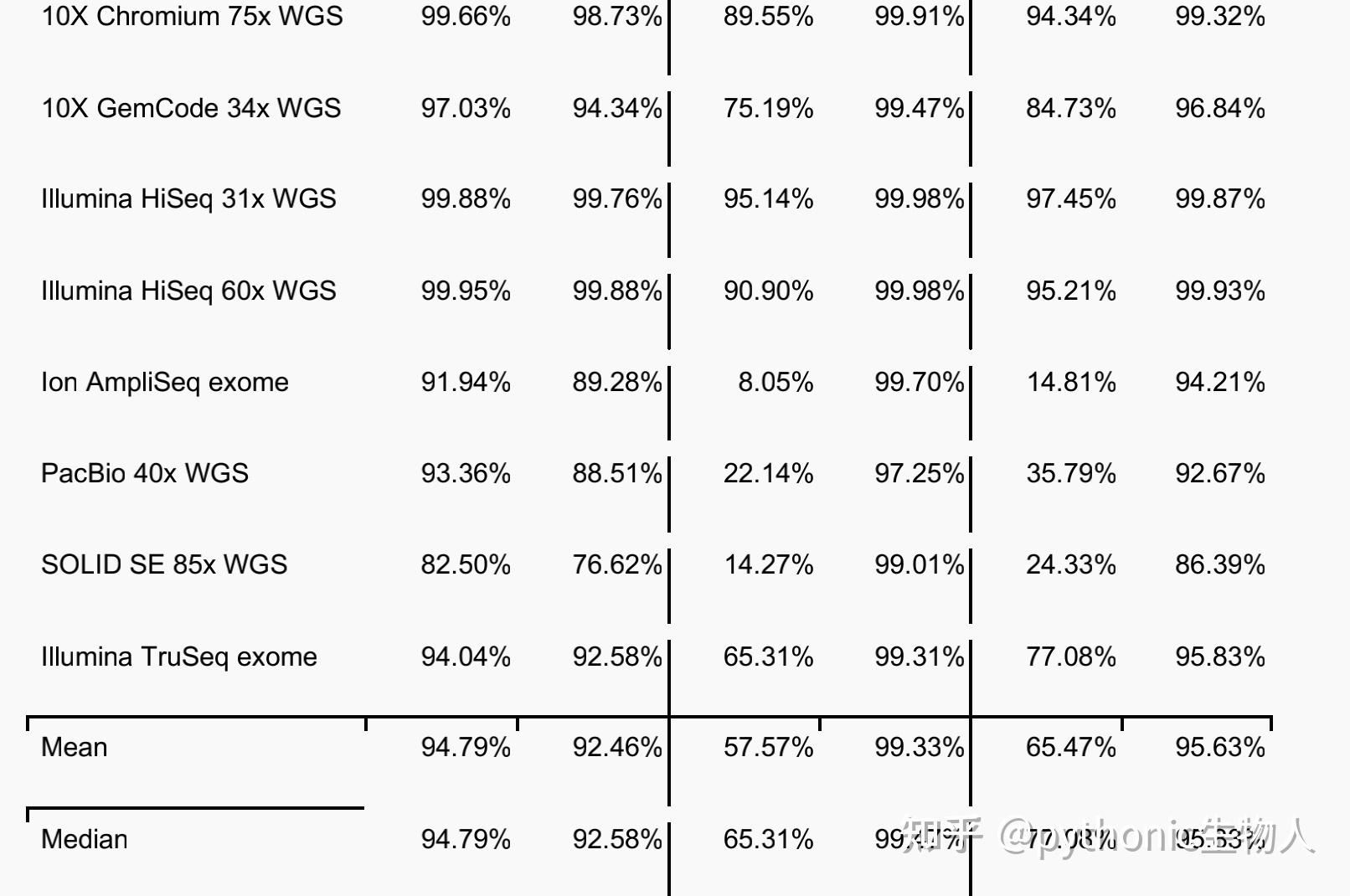
底下有评论说,挺好发文章。的确是,挺好发文章毕业做博后拿教职。不过和计算机那些会议的成果比起来,到底有多少创新,对行业有多大推动,你自己心里的判断是什么?人类基因组计划二十年以来,生物信息领域有哪些大的突破可以和AlphaGo或者ChatGPT相提并论呢?AlphaFold出来以后,整个结构生物学有了多大变化?最好是先想好这些问题的答案再决定要不要消耗几年时间进入这个领域。AlphaFold和ChatGPT采用的技术,在AI领域甚至并不是最前沿的技术。
再补充一点:这个回答是在2023年初所写,所针对的也是计算机特别是机器学习背景、打算进入bioinformatic领域的人所说的观点,对其他各种背景转入生物信息或者AI的人可能并不正确。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-3-9 21:20
发表于 2025-3-9 21:20


 发表于 2025-3-9 21:20
发表于 2025-3-9 21:20
 发表于 2025-3-9 21:21
发表于 2025-3-9 21:21