金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
推文首发于公众号:南博吉吉,欢迎关注。
一、写在前面
在对样本进行分组回归后,直接比较系数的大小会产生偏差,因此需要对组间系数差异进行显著性检验。常用的方法有三种:邹检验(Chow 检验)、似无相关检验 (suest)、费舍尔组合检验(Fisher’s Permutation test)。下面来学习一下三种系数差异检验方法的stata代码、判断标准与结果汇报。
本推文不涉及原理,原理部分可以阅读连玉君和廖俊平(2017)发表的《如何检验分组回归后的组间系数差异?》。
二、三种组间系数差异检验方法
假设分组变量为M,是0—1虚拟变量;控制变量为X1 X2 X3。
我们先把控制变量打包一下,后面就可以用$control 来表示控制变量X1 X2 X3。
global control "X1 X2 X3"(一)邹检验(Chow 检验)
1.代码
global control1 "c.X1 c.X2 c.X3"
reg Y i.M##(c.X $control1 i.industry i.year) ,cluster(id)
- Y表示因变量,X表示自变量,$control表示控制变量,i.year表示年份虚拟变量,i.industry表示行业虚拟变量。
- cluster(id)表示企业层面的聚类稳健标准误,这个可以根据自己的研究需要做更改。
- 离散变量前要加 i. 前缀,否则将被视为连续变量;取值为0—1的虚拟变量,可以省略前缀 i.;连续变量则需加 c. 前缀。help fvvarlist对这类因子变量的用法有更详细的解释。
- ##表示在回归中分别加入前后的变量以及它们的交互项(一个#号表示两个变量交互)。
2.回归结果、判断标准与结果汇报
以下图的回归结果为例,判断组间系数差异显著的标准是分组变量与核心解释变量的交互项是否显著。
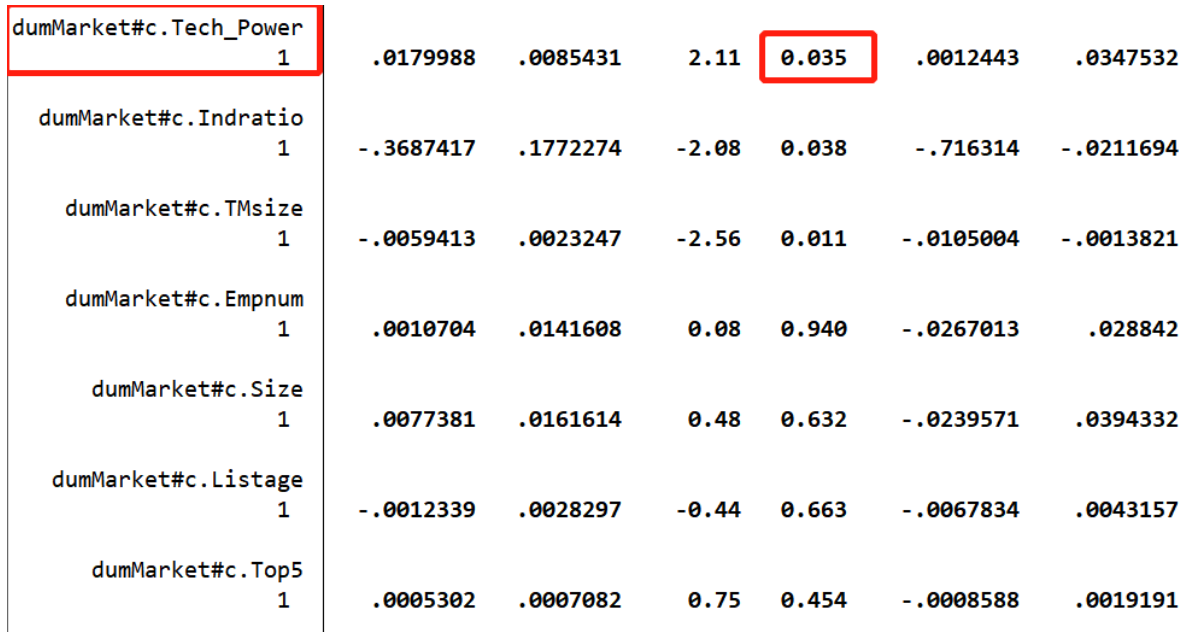
图中的分组变量M与核心解释变量X的交互项dumMarket#c.Tech_Power的p值为0.035,在5%的水平上显著,故可以得到组间系数差异显著的结论。
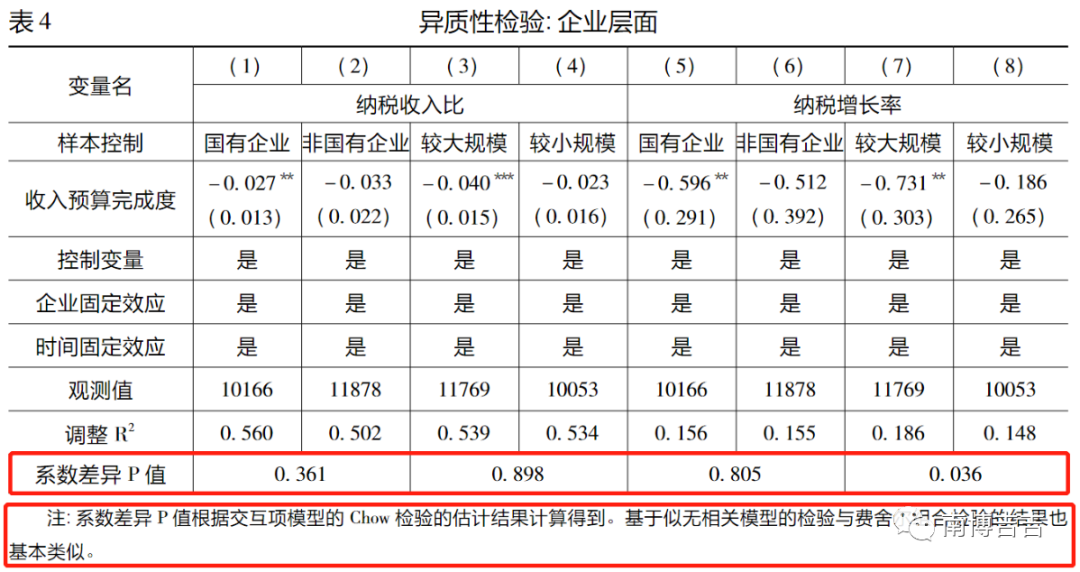
结果汇报可以参考吕冰洋等(2022)的做法,在分组回归表中报告系数差异P值,并在注释中或者正文说明系数差异P值的实现方法。
3.注意事项
- 如果存在异方差,需要用robust或cluster聚类稳健标准误来解决。不过,使用聚类稳健标准误基本是回归的标配了。
- Chow 检验支持xtreg。
(二)似无相关检验 (suest)
1.代码
*Step1:分别对两个样本组进行估计
reg Y X $control i.industry i.year if M==1
est store m1
reg Y X $control i.industry i.year if M==0
est store m2
*Step2:使用suest命令进行SUR估计
suest m1 m2
*Step3:使用test命令检验组间系数差异
test [m1_mean]X = [m2_mean]X
- Y表示因变量,X表示自变量,$control表示控制变量。i.year表示年份虚拟变量,i.industry表示行业虚拟变量。
- est store m1与est store m2表示将估计结果分别存储m1与m2两个临时性文件中。m1与m2也可以自己命名其他符号,例如写成a与b。
- [m1_mean]X 表示m1组方程中 X 变量的系数,而 [m2_mean]X 则表示m2组中 X 变量的系数。
我们也可以使用bdiff命令,用一行代码完成上述的似无相关检验。
bdiff, group(M) model (reg Y X $control ) surtest2.回归结果、判断标准与结果汇报
以下图的回归结果为例,判断组间系数差异显著的标准是下方的P值是否显著,图中的p值为0.0487,在5%的水平上显著,故可以得到组间系数差异显著的结论。
结果汇报的方式同吕冰洋等(2022)。

3.注意事项
- suest 不支持 xtreg 命令,如果直接使用xtreg命令,Stata会报错,如下图所示。因此,需要使用center 或 xtdata 命令除面板数据中的个体效应,然后当作截面数据,使用reg命令进行OLS回归。

从上图展示的吕冰洋等(2022)的分组回归可以看出,文中的模型控制了企业固定效应与时间固定效应,需要使用xtreg命令进行回归,但是作者采用三种方法进行组间系数差异检验,其中就包括不支持 xtreg 命令的似无相关检验。所以,可以推断作者的做法可能有两种,一种是直接用上面的代码做的似无相关检验,另一种是先去除了个体效应再使用的似无相关检验(代码如下所示)。
ssc install center, replace //安装center命令
*Step0:组内中心化
bysort id : center Y X $control //中心化会生成新变量,在原变量名称前加上了前缀c_,所以后面的回归要用带有前缀c_的变量。
*Step1:分别对两个样本组进行估计
reg c_Y c_X c_X1 c_X2 c_X3 `dumyear' `dumindustry' if M==1
est store m1
reg c_Y c_X c_X1 c_X2 c_X3 `dumyear' `dumindustry' if M==0
est store m2
*Step2:使用suest命令进行SUR估计
suest m1 m2
*Step3:使用test命令检验组间系数差异
test [m1_mean]c_X = [m2_mean]c_X如果用i.year和i.industry,系统可能会报错,如下所示(我在操作的时候就报错了)。于是,我手动生成了年份虚拟变量`dumyear',上述代码顺利运行。

- suest 可以进行logit,tobit等估计。
- suest 不能用聚类稳健标准误进行异方差修正。
- bdiff 命令要求两个样本组中的解释变量个数相同,如果控制行业虚拟变量,分组后两个样本组所包含的行业数量可能不一样,导致结果报错,如下图所示。suest 命令允许两个样本组的解释变量个数不同。

(三)费舍尔组合检验(Fisher’s Permutation test)
1.代码
bdiff, group(M) model (reg Y X $control) bs reps(1000) detail
- reps(1000)表示抽样次数,范围一般为1000—5000。连玉君等(2010)抽样1000次;曾嶒和唐松(2023)抽样2000次。
- bs是指bootstrap,表示随机抽样为可重复抽样。
- detail表示呈现两组的实际估计系数。
上述代码没有加入虚拟变量(行业虚拟变量、时间虚拟变量),如果在$control后面直接写i.industry或i.dumyear,Stata会报错。因此,我们需要手动生成行业虚拟变量或时间虚拟变量(多少个虚拟变量取决于你的研究样本,这里以我的研究样本为例),然后再放到$control后面。
tab industry, gen(d) //手动生成行业虚拟变量
local dumindustry "d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11 d12 d13 d14 d15 d16 d17 d18 d19 d20" //20个行业虚拟变量,多少个虚拟变量取决于你的研究样本,这里以我的研究样本为例
tab year, gen(y) //手动生成年份虚拟变量
local dumyear "y1 y2 y3 y4 y5 y6 y7 y8 y9 y10 y11 y12" //12个年份虚拟变量
bdiff, group(分组变量) model (reg Y X $control `dumindustry' `dumyear') bs reps(1000) 2.回归结果、判断标准与结果汇报
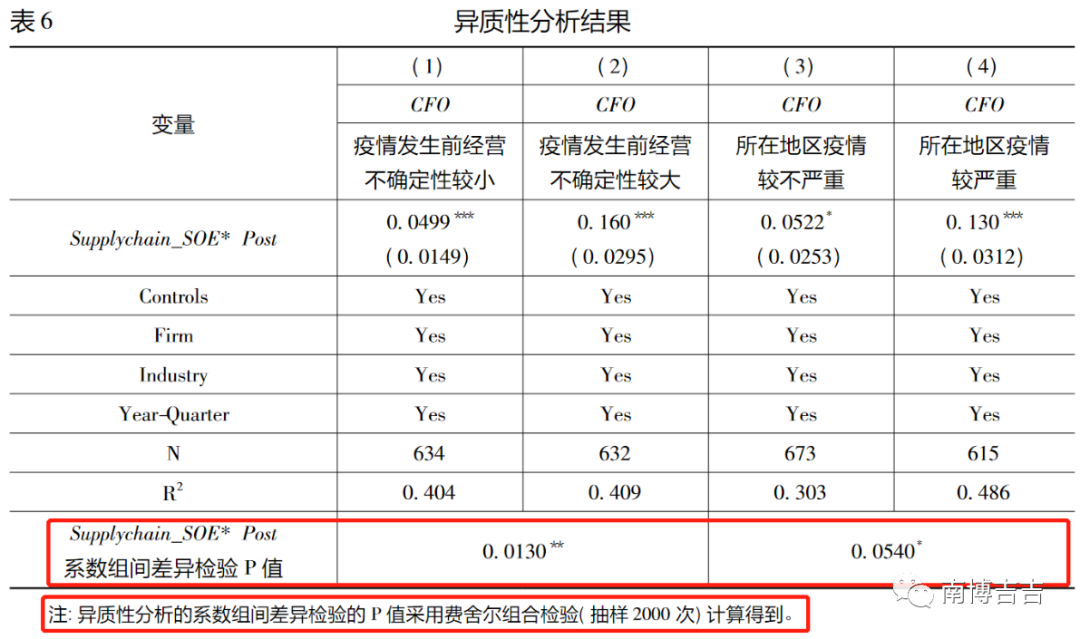
以下图的回归结果为例,判断组间系数差异显著的标准是核心解释变量对应的P值是否显著。
图中的核心解释变量Tech_Power的p值为0.001,在1%的水平上显著,故可以得到组间系数差异显著的结论。
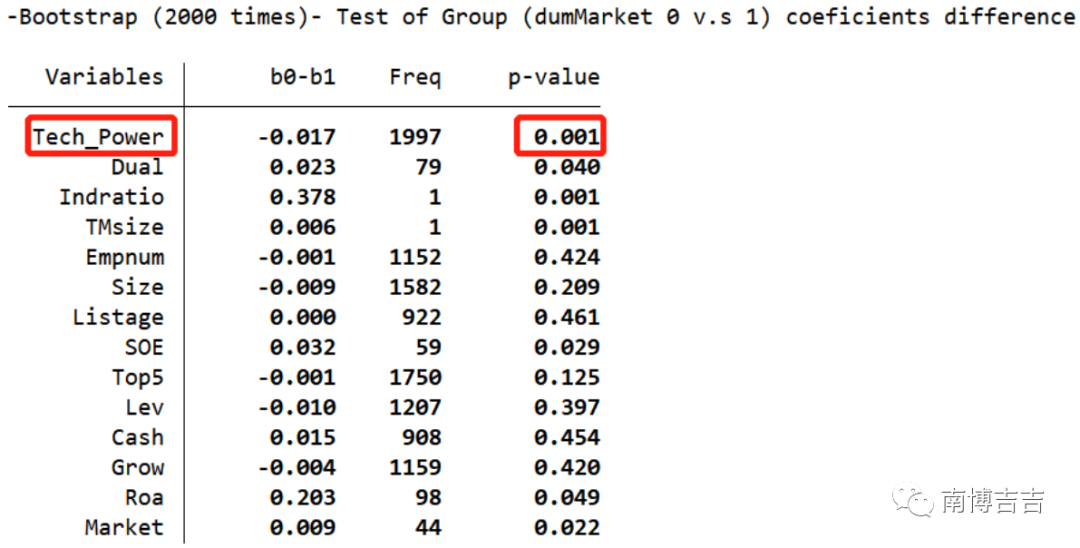
结果汇报可以参考连玉君等(2010)的做法,在分组回归表中报告经验P值,并在注释中或者正文说明经验P值的作用、实现方法以及抽样次数。
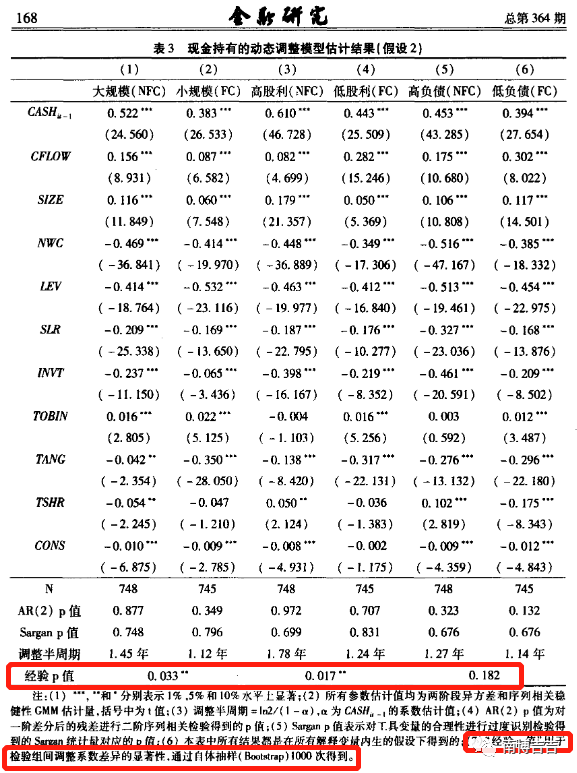
类似地,也可以参考曾嶒和唐松(2023)的做法。
3.注意事项
- 使用费舍尔组合检验需要提前安装dbiff命令,stata 命令窗口中输入 ssc install bdiff,replace 可以下载最新版命令包。
- 该方法不仅适用于普通的线性回归模型(regress 命令) ,还可以应用于xtreg,xtabond,logit,ivregress等模型。
参考文献:
连玉君,廖俊平.如何检验分组回归后的组间系数差异?[J].郑州航空工业管理学院学报,2017,35(06):97-109.
连玉君, 彭方平, 苏治. 融资约束与流动性管理行为[J]. 金融研究, 2010(10): 158–171.
曾嶒, 唐松. 新冠疫情下国有企业的经济稳定器作用——基于供应链扶持的视角[J]. 经济研究, 2023, 58(3): 78–96.
吕冰洋, 陈怡心, 詹静楠. 政府预算管理、征税行为与企业经营效率[J]. 经济研究, 2022, 57(8): 58–77.
原文地址:https://zhuanlan.zhihu.com/p/629123531 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-2-16 20:03
发表于 2025-2-16 20:03



