只需一步,快速开始
微信扫一扫,快速登录
您需要 登录 才可以下载或查看,没有账号?立即注册
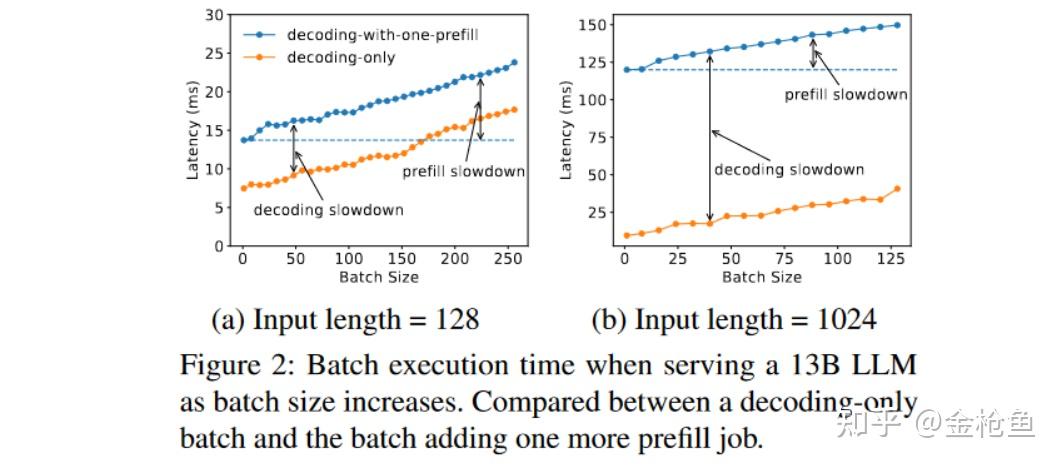
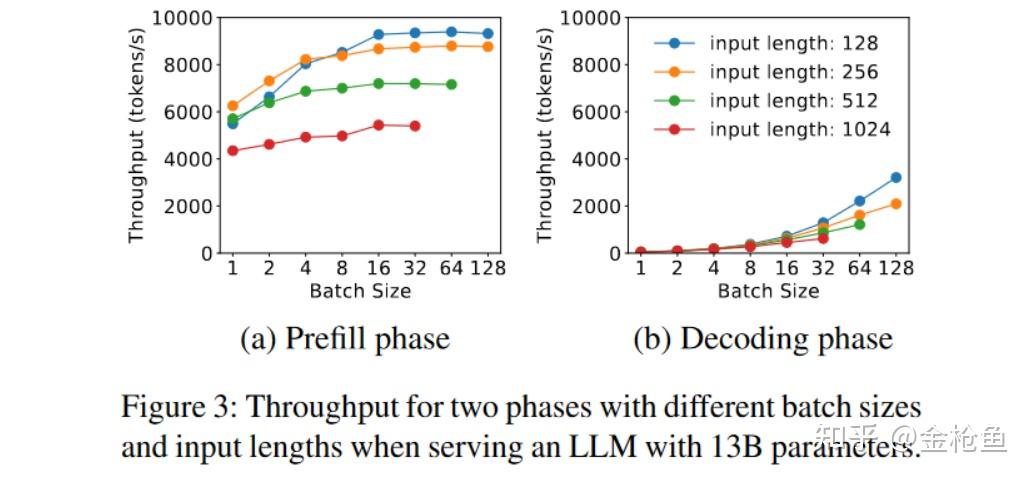
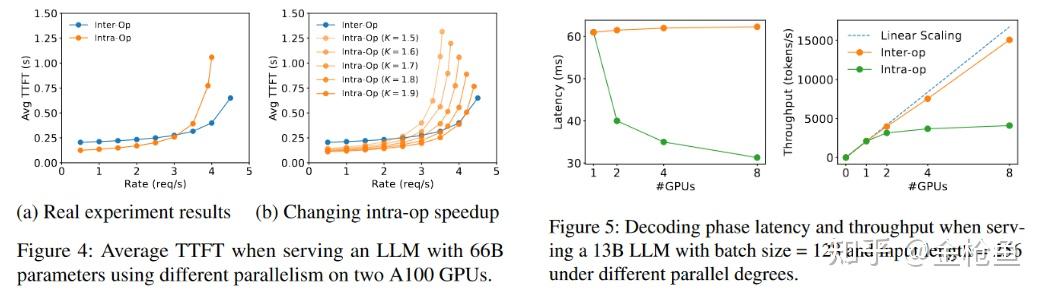
一个改进的连续批处理变体(Sarathi-Serve)尝试通过将长预填充分割成块并将解码任务附加到这些块上来平衡TTFT和TPOT,但本质上,这只是以TTFT换取TPOT,无法消除两者间的干扰。同时长文本的Prefill分割后的成本会逐渐趋近于类似Decode阶段的访存密集型成本。
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页
查看 »
微信扫一扫关注本站公众号

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-1-30 11:38
发表于 2025-1-30 11:38


 提升卡
提升卡


