金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
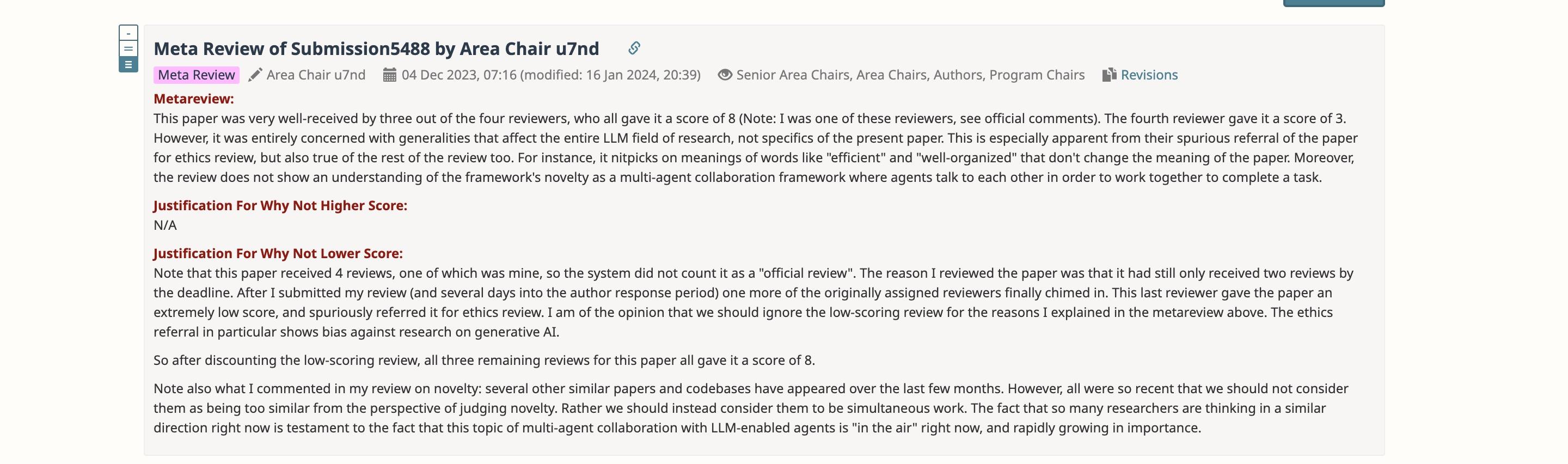
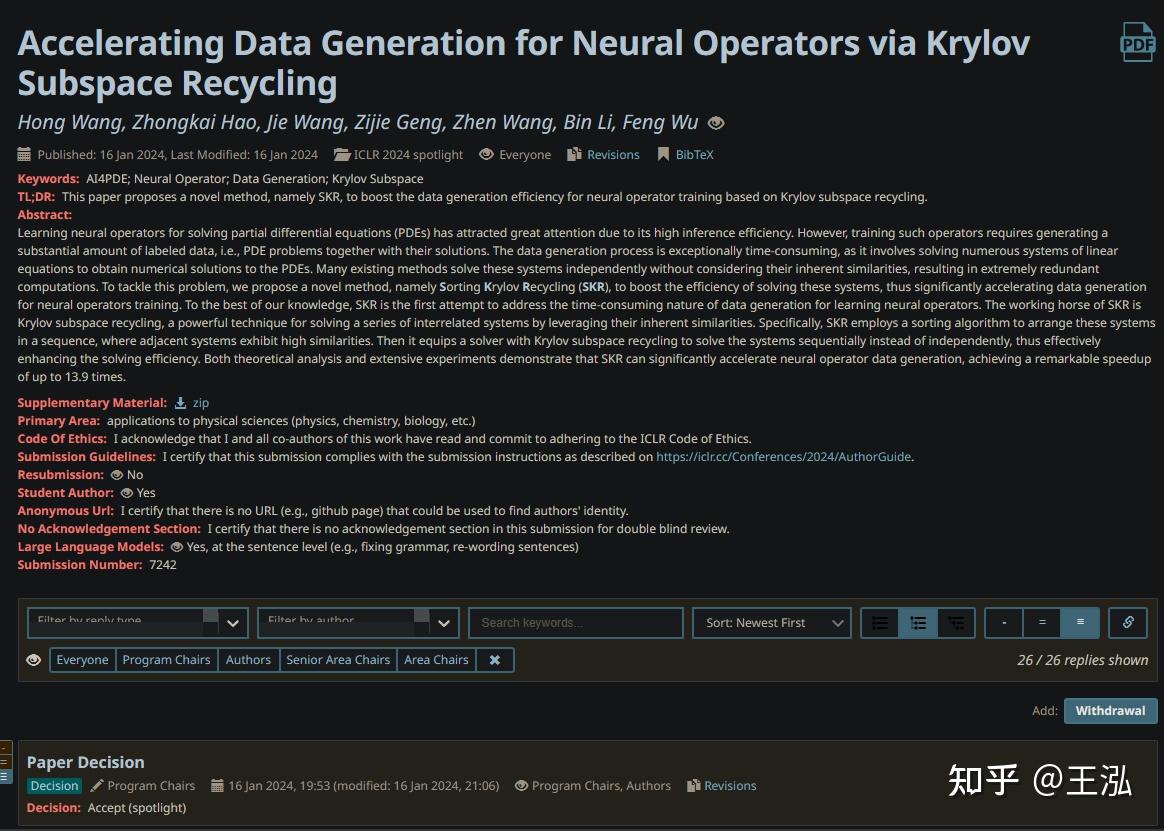
ICLR24得分888居然被拒?Area Chair的Meta review完全事实性错误?
TL;DR: AC把我们方法的超参数N=1理解为了攻击次数为1,于是认为我们评测不充分,并引用了autoattack这一大家认为充分的攻击。然而,我们全文(除了特殊的adaptive attack外),全部是使用的AC所引用的autoattack。这样的meta review是不是一种笑话?
文章链接:Robust Classification via a Single Diffusion Model
文章的blog链接:虚无:扩散模型即为鲁棒分类器: Robust Classification via a Single Diffusion Model
<hr/>
888据我所知似乎是iclr历史上被拒稿的最高分了。
我先简单介绍一下这篇论文:我们提出了一种新的分类算法,直接使用diffusion这种生成模型(无需CNN ViT等分类模型)来做鲁棒分类。在对抗攻防的领域下,新的防御算法一旦提出,需要进行各种adaptive attack来进行充分评测,从而确保鲁棒性并不是因为评测不充分造成的。因此,我们也进行了大量的adaptive attacks。同时,攻击步数越多,攻击通常来说就越强。我们使用了大家默认的评测方式AutoAttack(最少100步攻击)进行评测。我们得到了3个审稿人的一致好评,得分888.

AC的意见
Area Chair的核心论点是:one-step attack不足以充分评测防御。只有AutoPGD这种multi-step attack才能充分评测防御。
然而,我们全文从未使用过one-step attack。我们全文(除了攻击diffpure的adaptive attack外),全部使用的是Area Chair引用的&#34;AutoPGD&#34;。
这样完全的事实性错误也太搞笑了。我们用的方法就是AC所cite的方法。AC却认为我们用的是one-step attack。AC为什么会这么认为呢?我猜是因为AC把我们方法中的超参数N的 (N=1)直接误认为了是攻击次数为1。把N=5误认为了攻击次数是5次。

AC很可能根本就没有仔细阅读论文,就随意的把“N=1”理解为攻击次数为1。one-step attack显然不是充分的评测。但是给出Meta review之前,是否可以多花一点时间想一想,在整篇文章做了这么多adaptive attack的情况下,难道作者所有攻击要么5步要么1步么?作者有意识做adaptive attack,难道还不知道“one-step attack不充分”么.....三个审稿人给分888,如果真是“作者的攻击次数是1”,难道他们三个看不出来么。。。
<hr/>下面我来回答一下Meta review的两个comments。
Comments 1: 理论分析部分和实际claim没有联系。并且不知道optimal diffusion classifier是怎么评测的。
我们在本篇文章中提出一个新的理论分析工具,即Diffusion Model和Diffusion Classifier的最优解。因此,我们只需要检验optimal下是否还有类似的问题。如果有,那我们应该改进模型;如果没有,那我们应该去查看empirical solution和optimal solution的区别,从而更好的改进我们的算法。我们发现对于对抗样本,主要区别在于empirical solution的diffusion loss相比optimal solution更小。这有且仅有2个原因。1) empirical情况下likelihood更小 2) ELBO和log likelihood差距大,从而导致diffusion classifier (theorem 1)近似误差过大。 为了解决这两个问题,我们提出likelihood maximization,去maximize elbo,同时增大likelihood,减小elbo和likelihood的误差。
至于optimal diffusion classifier的评测,我们在实验部分写的很清楚,除特殊声明和LM这种不可导的外,都是以&#34;AutoAttack&#34;进行评测的,即Area Chair引用的那个评测。我们使用AutoAttack,梯度又是准确的,同时几乎没有随机性,我们有理由相信评测是充分的。
Comments 2: 方法的高时间复杂度让作者无法用SOTA的白盒攻击来评测。作者只进行了one-step gradient attack,而这显然是不充分的。
经过其中一个审稿人的建议,我们已经测了real time cost。对于每张图片,之前的防御DiffPure需要0.60秒(linf)或0.72秒(l2)。而我们最终的方法需要1.43秒。时间复杂度高是我们的limitations,但不影响我们的评测。
最重要的是,&#34;one-step gradient attack&#34;当然是不充分的。但我们也当然知道这是不充分的,我们从头到尾就没用过one-step gradient attack。我们全用的是Area Chair所引用的&#34;AutoAttack&#34;。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-1-25 16:53
发表于 2025-1-25 16:53





 发表于 2025-1-25 16:55
发表于 2025-1-25 16:55