金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
简单说一下我的见解,以公司和技术趋势而不是个人的角度做一些分析,并预测一些OpenAI下一步的进展。
目标和商业模式明确
对于OpenAI,目前的目标很明确:就是 all in AGI,一切研究围绕着探索通往AGI的路径。
而商业模式上也很简单:SaaS,直接给API,接口设计内部自己决定,付多少钱用多少,不想用就不用,这样省去了很多产品设计,marketing,BD的时间,伺候甲方的时间(有比较可靠的消息称即使Microsoft的Copilot等产品也是直接用的API,没有花功夫做太多的定制),整个公司可以集中精力开发AGI。
有人可能说:不是啊,OpenAI不是还有ChatGPT的用户界面,手机端语音聊天,以及GPTs吗?但是仔细想想,这几个部分OpenAI可以说是“非常不用心”了。比如ChatGPT Plus 是怎么自动融合搜索,图片生成,代码调用等工具的?单独做了一套深度优化?不,答案是OpenAI给了一个巨大的prompt,让模型自己去选。OpenAI是怎么和各种第三方插件结合的,是单独做了匹配和接口?不,答案是直接让这些plugins描述自己是什么,然后模型自己调用,至于调用得对不对那就是另外一件事情了。这里最典的是最近OpenAI怎么实现“记忆”的,给大家看看OpenAI的完整 prompt(博杰提供的,每个人可以诱导ChatGPT说出这些,OpenAI也不在乎):
You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture. Knowledge cutoff: 2023-04
Current date: 2024-02-15
Image input capabilities: Enabled
Personality: v2
# Tools
## bio
The `bio` tool allows you to persist information across conversations.
Address your message `to=bio` and write whatever information you want to remember.
The information will appear in the model set context below in future conversations.
## dalle
// Whenever a description of an image is given, create a prompt that dalle can use to generate the image and abide to the following policy:
// 此处省略 1000 词
## browser
You have the tool `browser`. Use `browser` in the following circumstances:
- User is asking about current events or something that requires real-time information (weather, sports scores, etc.)
- User is asking about some term you are totally unfamiliar with (it might be new)
- User explicitly asks you to browse or provide links to references
// 此处省略 1000 词
## python
When you send a message containing Python code to python, it will be executed in a
stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 60.0
seconds. The drive at '/mnt/data' can be used to save and persist user files. Internet access for this session is disabled. Do not make external web requests or API calls as they will fail.
## voice_mode
// Voice mode functions are not available in text conversations.
namespace voice_mode {
} // namespace voice_mode
## Model Set Context
1. [2024-02-14]. Obtained PhD from Microsoft Research Asia and USTC in 2019.
2. [2024-02-14]. Running an early-stage AI startup since July 2023.
3. [2024-02-14]. Loves writing blogs, traveling and documenting everything.
4. [2024-02-15]. Experience in writing Python.
5. [2024-02-15]. Interested in digital extension of humanity.
6. [2024-02-15]. First met ChatGPT on Dec. 1st, 2023.OpenAI 直接用 prompt 让GPT-4调用bio这个工具记录需要记忆的内容(“to=xxx”是调用内部工具的语法,比如"to=python"是 GPT 调用 code interpreter 的方式)。然后每次新的对话开始时,在prompt的最后直接加上所有之前的记录的内容(## Model Set Context)。就是这么简单粗暴。
GPTs 怎么做的?其实很大程度就是OpenAI 的 Assistant API加个简单得有点简陋的前端。(PS:现在有了OpenAI Assistant API后,你发现加个UI就可以很轻松的复刻OpenAI上线的大部分功能。)
那么语音对话呢?你会发现就是换了一个prompt,告诉GPT尽量生成短的内容,不要轻易生成列表和代码。语音合成用TTS API,识别用whisper API(可能有针对上下文的优化),结束。
这些选择看上去非常暴力,而且会给OpenAI增加开销(长的prompt会明显增大开销),但是OpenAI仍然选择这么做,因为这让OpenAI将大部分精力都花在模型本身的研发上,同时这也是OpenAI的方法论的极致体现,我们下面会提到。这种方法论让OpenAI追求一个大的通用的模型,避免一切定制和特化,就像最近Sam说的一样,希望GPT-5的出现能让模型微调失去意义;这样OpenAI就变成了完完全全的SaaS服务。
方法论明确
OpenAI的方法论是通往 AGI 的方法论。这个方法论有着非常清晰的逻辑结构,和非常明确的推论。我们甚至可以用公理化的方式来描述它,怎么说呢,感觉上有一种宿命感,。
方法论的公理
这套方法论的大厦构建于以下几个“公理”(打引号是因为它们不是真正的“公理”,更多是经验规律,但是在AGI方法论中,它们起到了公理的作用):
公理1: The bitter lesson。我认为所有做AI的人都应该熟读这篇文章。“The bitter lesson” 说的事情是,长期来看,AI领域所有的奇技淫巧都比不过强大的算力夹持的通用的AI算法(这里“强大的算力”隐含了大量的训练数据和大模型)。某种意义上,强大的算力夹持的通用的AI算法才是AGI路径的正道,才是AI技术真正进步的方向。从逻辑主义,到专家系统,到SVM等核方法,到深度神经网络,再到现在的大语音模型,莫不过此。
公理2: Scaling Law。这条公理说了,一旦选择了良好且通用的数据表示,良好且通用的数据标注,良好且通用的算法,那么你就能找到一套通用规律,保证数据越多,模型越大,效果越好。而且这套规律稳定到了可以在训练模型之前就能预知它的效果:
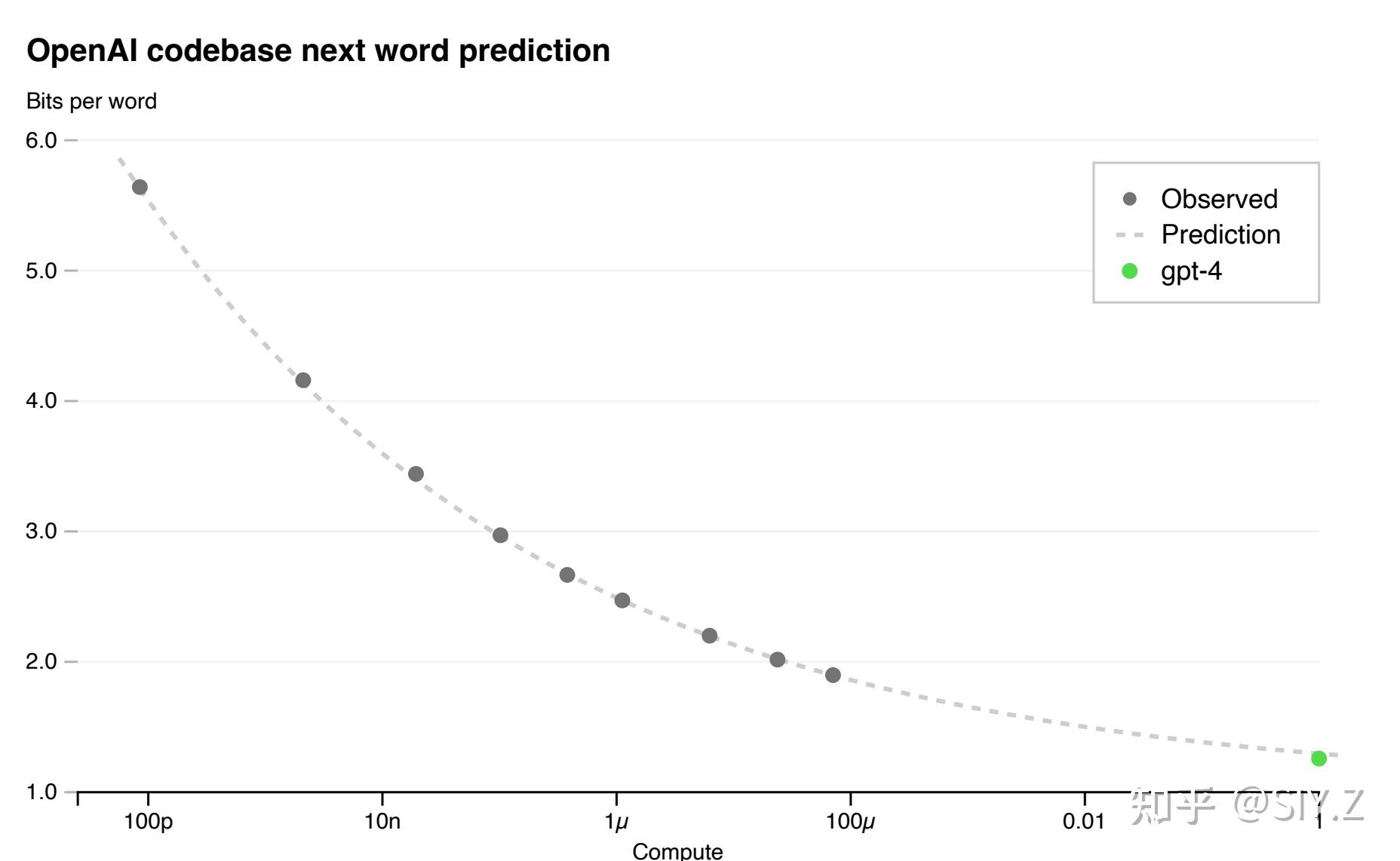
Scaling Law 甚至能够在训练前预知最后的性能,图片选自OpenAI GPT-4 Technical Report
如果说 公理1 The bitter lesson 是AGI的必要条件——大模型,大算力,大数据,那么公理2 Scaling Law 就是AGI充分条件,即我们能找到一套算法,稳定的保证大模型,大算力,大数据导致更好的结果,甚至能预测未来。
而具体来谈,就是我们之前说的“良好且通用的数据表示,良好且通用的数据标注,良好且通用的算法”,在GPT和Sora中都有相应的内容:
- 在GPT中,良好且通用的数据表示,是tokenizer带来的embedding。良好且通用的数据标注是文本清理和去重的一套方法(因为自然语言训练是unsupervised training,数据本身就是标注)。良好且通用的算法就是大家熟知的transformers + autoregressive loss。
- 在Sora中,良好且通用的数据表示,是video compress network带来的visual patch。良好且通用的数据标注是OpenAI自己的标注器给视频详细的描述(很可能是GPT-vision)。良好且通用的算法也是大家熟知的transformers + diffusion
“良好且通用的数据表示,良好且通用的数据标注,良好且通用的算法”同时也为检测scaling law做好了准备,因为你总是可以现在更小规模的模型和数据上检测算法的效果,而不用大幅更改算法。比如GPT1,2,3这几代的迭代路径,以及Sora中OpenAI明确提到visual patch使得他们用完全一样的算法在更小规模的数据上测试。
公理3: Emerging properties。这条公理其实是一条检验公理:我怎么知道scaling law带来“质变”,而不仅仅是“量变”?答案是:你会发现,随着scaling law的进行,你的模型突然就能稳定掌握之前不能掌握的能力,而且这是所有人能够直观体验到的。比如GPT-4相比于GPT-3.5,可以完成明显更复杂的任务,比如写一个26行诗来证明素数是无限的,每行开头必须是从A到Z。比如Sora相对于之前的模型,它的时空一致性,以及对现实中物理规律的初步掌握。没有 Emerging properties,我们很难直观感觉到突破性的变化,很难感知“我们真的向AGI前进了一步”,或者是“我们跑通了一个技术栈”。
方法论的必然推论
从上面的公理中,我们就可以理解OpenAI的各种决策了,并且可以预见OpenAI未来的行为。
推论1: 世界模型。大量数据从哪里来?什么东西能够产生最多的数据?AGI需要什么样的数据才能通用地处理世界上的一切事情?答案就是:世界本身。世界本身产生最多的数据(或者极端一点,世界就是数据),而世界产生的数据,也是AGI需要的数据的最小集合,因为我们也只需要或者只能让AGI处理这个世界的事情。可以预见,OpenAI未来还会执着于持续获得或者构造数据。
推论2: 世界生成模型。要最有效的利用数据,我们需要最困难的,需要最多数据,且能利用所有数据的任务。这样的任务可能只有一个:模拟和生成整个世界(人类所有的智能只是一小块)。因此OpenAI需要做生成模型,并且是能够模拟和生成物理世界的模型,通过生成这个世界,实现对世界的理解。最近火爆的Sora便是其中之一。这个想法也和费曼的名言对应:“我不能创造的,我也不能真正理解”。可以预见,OpenAI未来还会在更多的模态和数据上去做生成模型。
推论3:通用模型。通用模型还是专用模型能用到更多数据?显然是通用模型。而通用模型也减少了OpenAI的技术栈,因为一个模型能解决更多问题。这也导致之前提到的OpenAI解决各种问题时更倾向于用同一种模型,而不是做非常多不同的定制。可以预见,OpenAI未来可能会继续走通用模型的道路,降低finetuning等特化的需求,继续增加模型的context length。
推论4:用一个模型为另一个模型提供标注。由于当前技术限制,OpenAI仍然无法用一个模型完成所有的任务,这样一个的模型收到数据就变少了。然而,我们可以用一个模型给另一个模型提供标注的形式,来间接实现数据供给。OpenAI的Dall E和Sora都用到了大量可能来自于GPT vision的数据标注。这样OpenAI的各个技术栈都可以连通起来。可以预见,OpenAI未来可能会继续加强各个模型的连接,比如将来用Sora反向给GPT vision给数据都是可能的;用一个已有模型去构造更多数据也会是一个重要的方向(比如backtranslation,data distillation等等)。
推论5:Transformer架构。我们需要一种能够并行处理大量数据吞吐,且满足scaling law的架构。transformer架构充分证实它在各个模态和技术栈的优势,特别在复杂任务中,因而被OpenAI广泛使用。使用同样一个架构的好处在于可以复用模型的参数(比如tokenizer,embeddings,以及部分权重)来bootstrap不同技术栈的训练,以及可以用一套infra框架训练不同的模型。可以预见,将来新的模型如果要取代传统的transformer架构,还需要通过scaling law的检验。
推论6:稀疏模型。模型越大,性能越好,但是推理的成本也越高,这看上去是个死结。但是我们可以使用稀疏激活的方式,在推理时降低实际的参数量,从而在训练中使用更多参数的同时,降低推理的成本。Mixture-of-Experts就是常用的方法之一,被OpenAI采用,从而继续scale模型的大小。未来稀疏化仍会是一个重要的课题,目前即使Mixture-of-Experts的稀疏也会造成推理性能的损失,尚不清楚稀疏化的极限在何处。
推论7:算力是瓶颈。最终卡OpenAI脖子的是算力。大算力系统的构建也是OpenAI打通各个技术栈的底气。有人可能认为,高质量文本是有限的,因此实际上模型大小有个极限。但是以世界模型的角度来考虑,OpenAI现在用的数据仍然是冰山一角,更不用说Q*等方法或许可以以间接方式创造数据。比如最近OpenAI GPT-4-Turbo,作为一个distillation模型,在很多评测上都超过原来的模型,就是一个例证。直到目前,作为局外人仍然看不到scaling law的尽头。而且即使不开发任何新的模型,OpenAI离“用GPT-4服务所有人”的目标仍然很远。所以算力在可见的未来都是一个巨大的瓶颈。这也可以理解Sam为何有“7万亿重构芯片产业”的想法了。可以预见,OpenAI可能在未来在芯片以及整个AI Infra方面尝试更多的自研和垂直集成。
总结
总结来看,OpenAI采取的商业模式以及其对于AGI的信奉、系统性的方法论以及积极的尝试,都在推动他们朝着实现通用人工智能的目标前进,实现了一种可以跑通所有AGI技术栈的模式,而这一点,是OpenAI能在众多研究机构和公司中脱颖而出的重要因素。未来,OpenAI可能继续朝着商业化的道路前进,并在世界模型、模型标注、通用模型、模型架构、稀疏模型数据扩充等方面进行更深入的探索和实践。同时,OpenAI也会持续关注和应对算力带来的挑战,寻找突破算力瓶颈的解决之道。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-1-3 20:05
发表于 2025-1-3 20:05