金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
Permutation Test 置换检验
显著性检验通常可以告诉我们一个观测值是否是有效的,例如检测两组样本均值差异的假设检验可以告诉我们这两组样本的均值是否相等(或者那个均值更大)。我们在实验中经常会因为各种问题(时间、经费、人力、物力)得到一些小样本结果,如果我们想知道这些小样本结果的总体是什么样子的,就需要用到置换检验。
Permutation test 置换检验是Fisher于20世纪30年代提出的一种基于大量计算(computationally intensive),利用样本数据的全(或随机)排列,进行统计推断的方法,因其对总体分布自由,应用较为广泛,特别适用于总体分布未知的小样本资料,以及某些难以用常规方法分析资料的假设检验问题。在具体使用上它和Bootstrap Methods类似,通过对样本进行顺序上的置换,重新计算统计检验量,构造经验分布,然后在此基础上求出P-value进行推断。
下面通过一个简单例子来介绍Permutation test的思想。
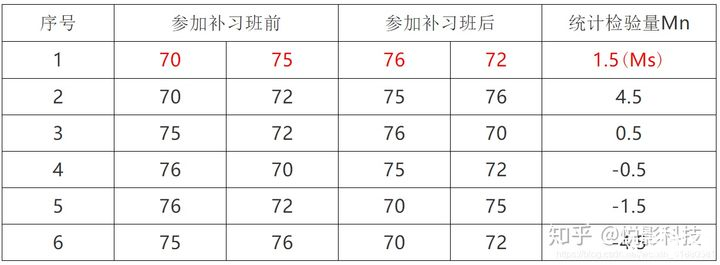
假设我们设计了一个实验来验证加入某种生长素后拟南芥的侧根数量会明显增加。A组是加入某种生长素后,拟南芥的侧根数量;B是不加生长素时,拟南芥的侧根数量(均为假定值)。
A组侧根数量(共12个数据):24 43 58 67 61 44 67 49 59 52 62 50
B组侧根数量(共16个数据):42 43 65 26 33 41 19 54 42 20 17 60 37 42 55 28
我们来用假设检验的方法来判断生长素是否起作用。我们的零假设为:加入的生长素不会促进拟南芥的根系发育。在这个检验中,若零假设成立,那么A组数据的分布和B组数据的分布是一样的,也就是服从同个分布。
接下来构造检验统计量——A组侧根数目的均值同B组侧根数目的均值之差。
statistic:= mean(Xa)-mean(Xb)
对于观测值有 Sobs:=mean(Xa)-mean(Xb)=(24+43+58+67+61+44+67+49+59+52+62+50)/12-(42+43+65+26+33+41+19+54+42+20+17+60+37+42+55+28)/16=14
我们可以通过Sobs在置换分布(permutation distribution)中的位置来得到它的P-value。
Permutation test的具体步骤是:
1.将A、B两组数据合并到一个集合中,从中挑选出12个作为A组的数据(X'a),剩下的作为B组的数据(X'b)。
Gourp:=24 43 58 67 61 44 67 49 59 52 62 50 42 43 65 26 33 41 19 54 42 20 17 60 37 42 55 28
挑选出 X'a:=43 17 44 62 60 26 28 61 50 43 33 19
X'b:=55 41 42 65 59 24 54 52 42 49 37 67 67 20 42 58
2.计算并记录第一步中A组同B组的均值之差。Sper:=mean(X'a)-mean(X'b)= -7.875
3.对前两步重复999次(重复次数越多,得到的背景分布越”稳定“)
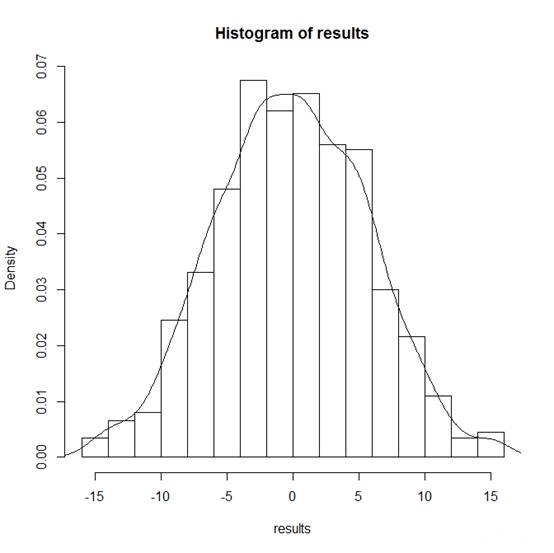
这样我们得到有999个置换排列求得的999个Sper结果,这999个Sper结果能代表拟南芥小样本实验的抽样总体情况。
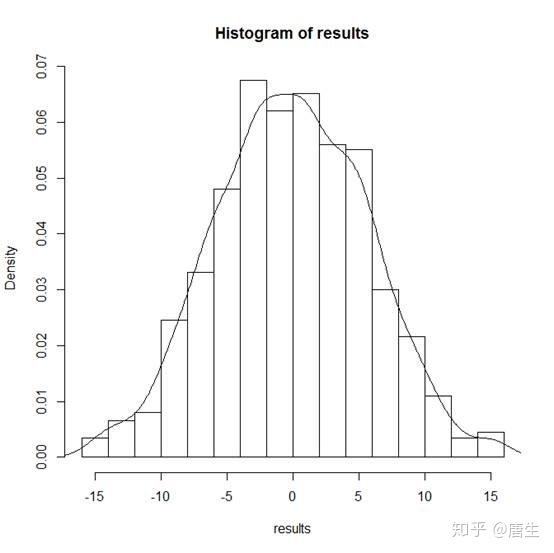
如上图所示,我们的观测值 Sobs=14 在抽样总体右尾附近,说明在零假设条件下这个数值是很少出现的。在permutation得到的抽样总体中大于14的数值有9个,所以估计的P-value是9/999=0.01
最后还可以进一步精确P-value结果(做一个抽样总体校正),在抽样总体中加入一个远大于观测值 Sobs=14的样本,最终的P-value=(9+1)/(999+1)=0.01。(为什么这样做是一个校正呢?自己思考:))结果表明我们的原假设不成立,加入生长素起到了促使拟南芥的根系发育的作用。
参考资料:
1. http://bcs.whfreeman.com/ips5e/content/cat_080/pdf/moore14.pdf
2. http://jpkc.njmu.edu.cn/course/tongjixue/file/jxzy/tjjz02.htm
3. http://www.r-bloggers.com/lang/chinese/541
附录:R语言求解上例的代码

a<-c(24,43,58,67,61,44,67,49,59,52,62,50,42,43,65,26,33,41,19,54,42,20,17,60,37,42,55,28)
group<-factor(c(rep(&#34;A&#34;,12),rep(&#34;B&#34;,16)))
data<-data.frame(group,a)
find.mean<-function(x){
mean(x[group==&#34;A&#34;,2])-mean(x[group==&#34;B&#34;,2])
}
results<-replicate(999,find.mean(data.frame(group,sample(data[,2]))))
p.value<-length(results[results>mean(data[group==&#34;A&#34;,2])-mean(data[group==&#34;B&#34;,2])])/1000
hist(results,breaks=20,prob=TRUE)
lines(density(results))
网上搬的,侵删:
Permutation Test 置换检验(转) - CSDN博客 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-1-3 12:10
发表于 2025-1-3 12:10


 发表于 2025-1-3 12:11
发表于 2025-1-3 12:11