机器之心报道。
昨天,The Information 的一篇文章让 AI 社区炸了锅。
这篇文章透露,OpenAI 下一代旗舰模型的质量提升幅度不及前两款旗舰模型之间的质量提升,因为高质量文本和其他数据的供应量正在减少,原本的 Scaling Law(用更多的数据训练更大的模型)可能无以为继。此外,OpenAI 研究者 Noam Brown 指出,更先进的模型可能在经济上也不具有可行性,因为花费数千亿甚至数万亿美元训练出的模型会很难盈利。
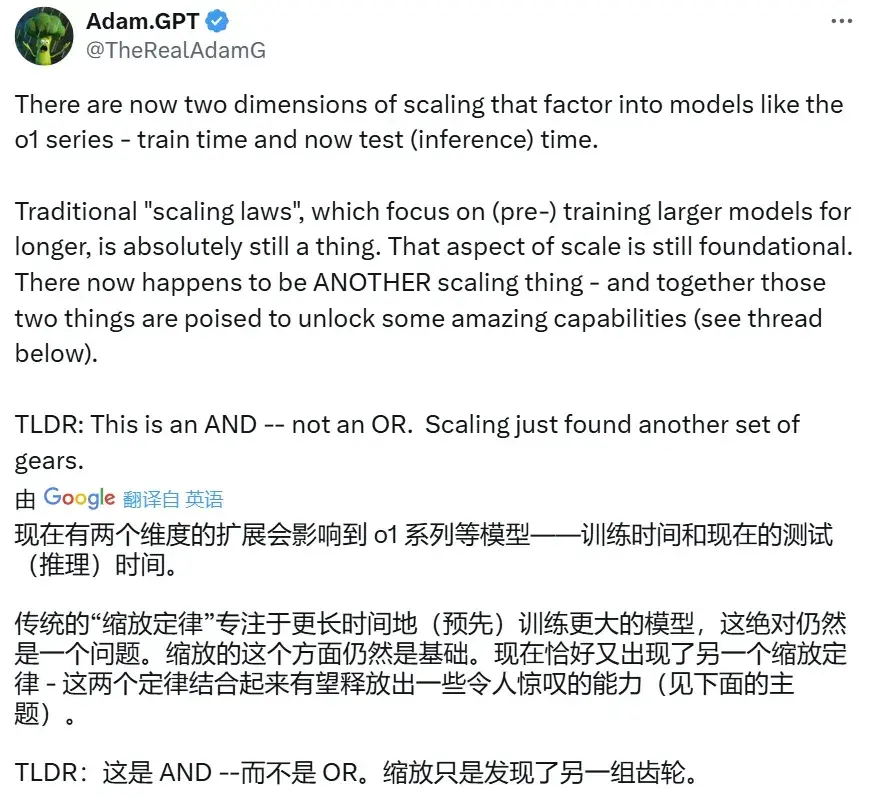
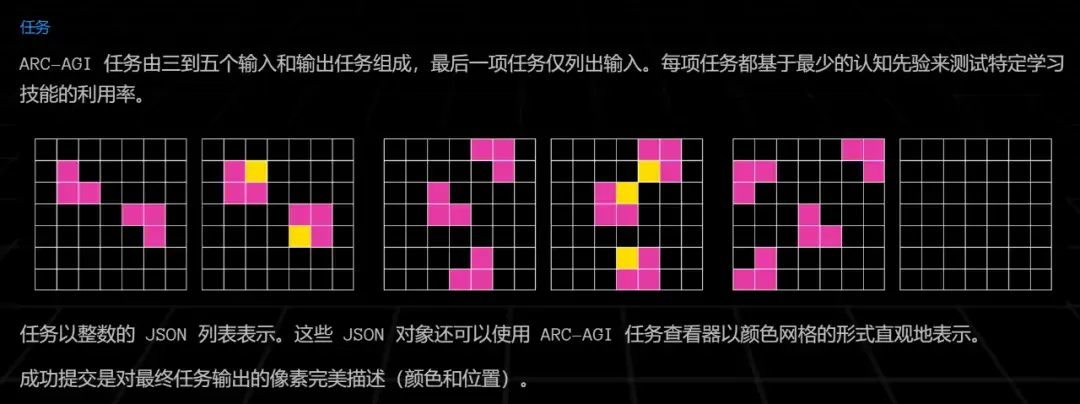
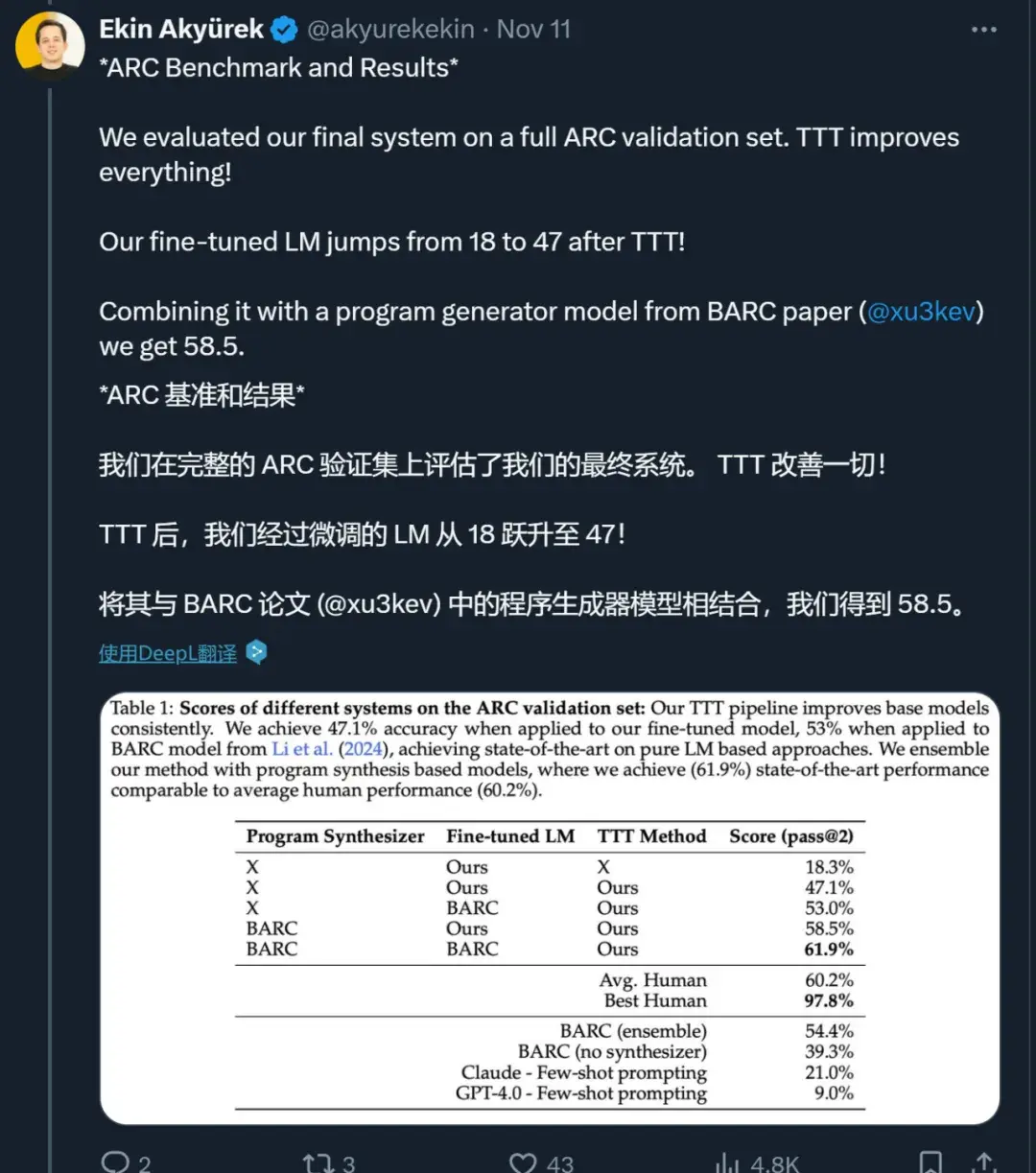
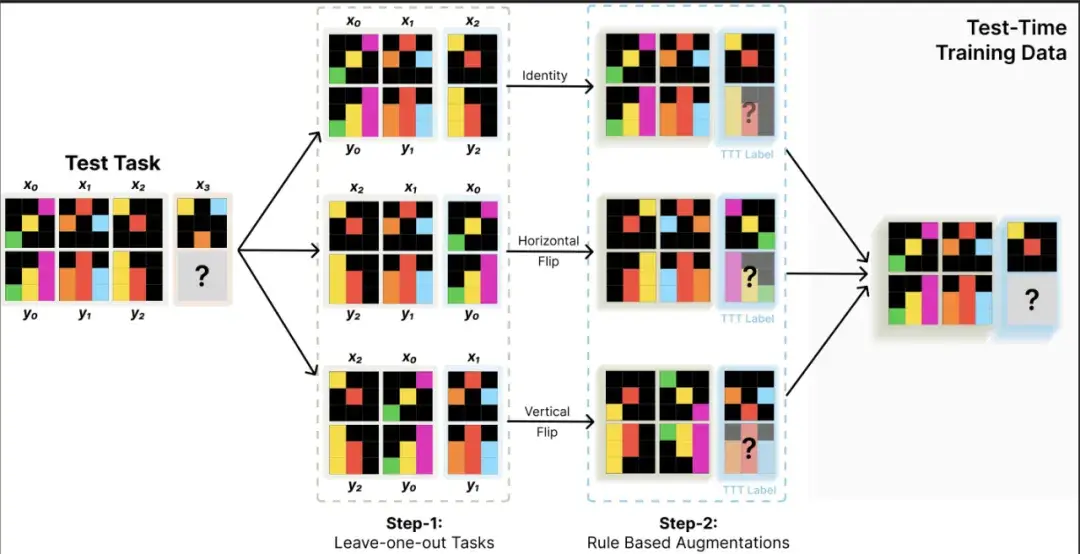
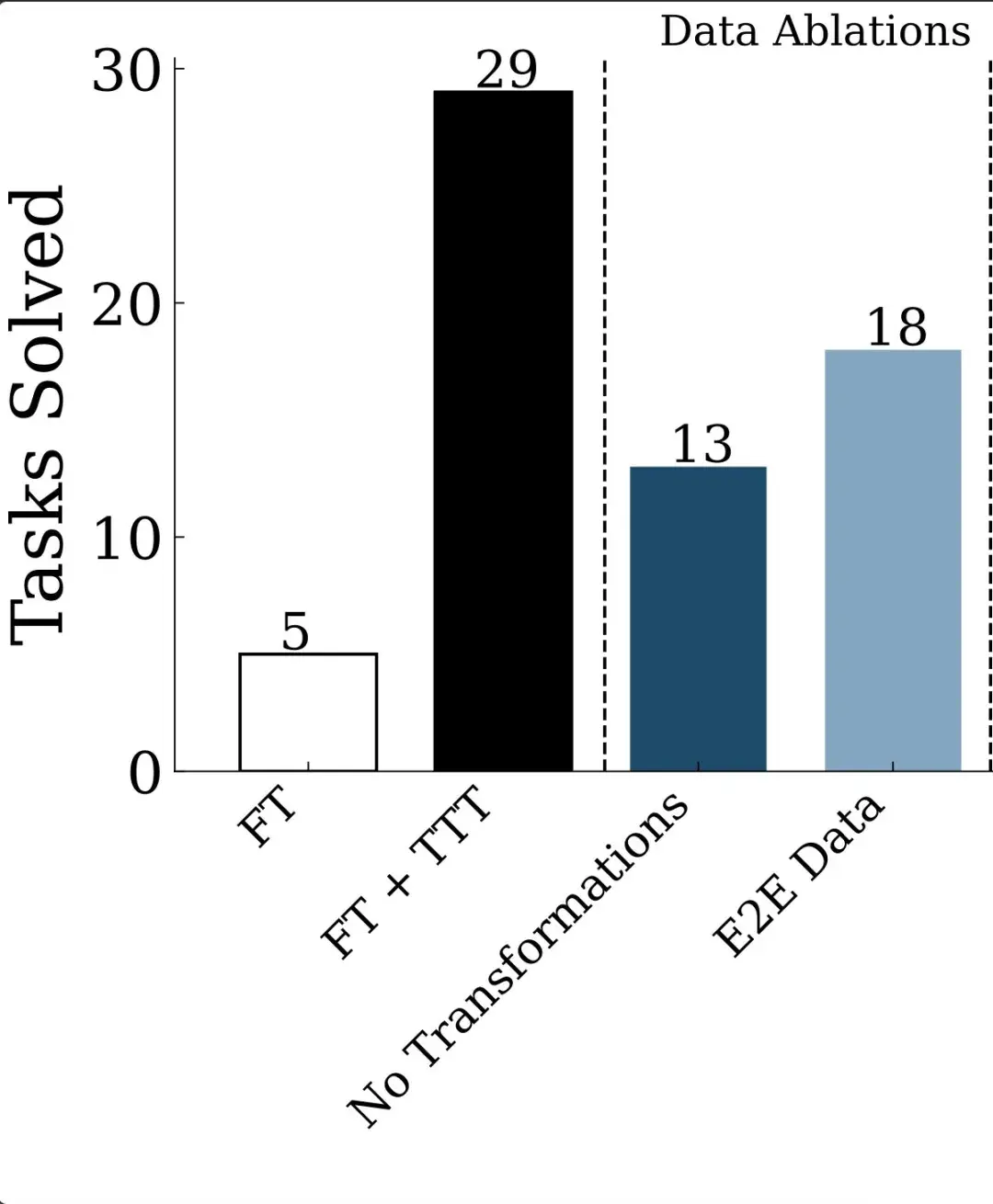
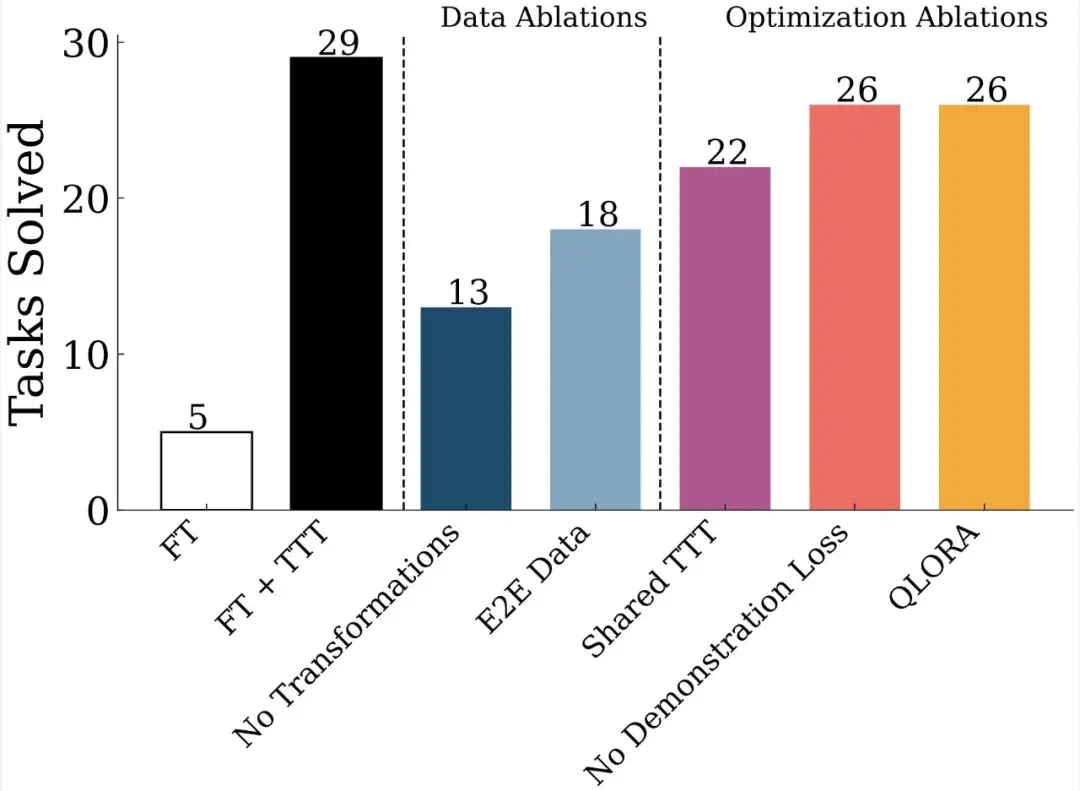
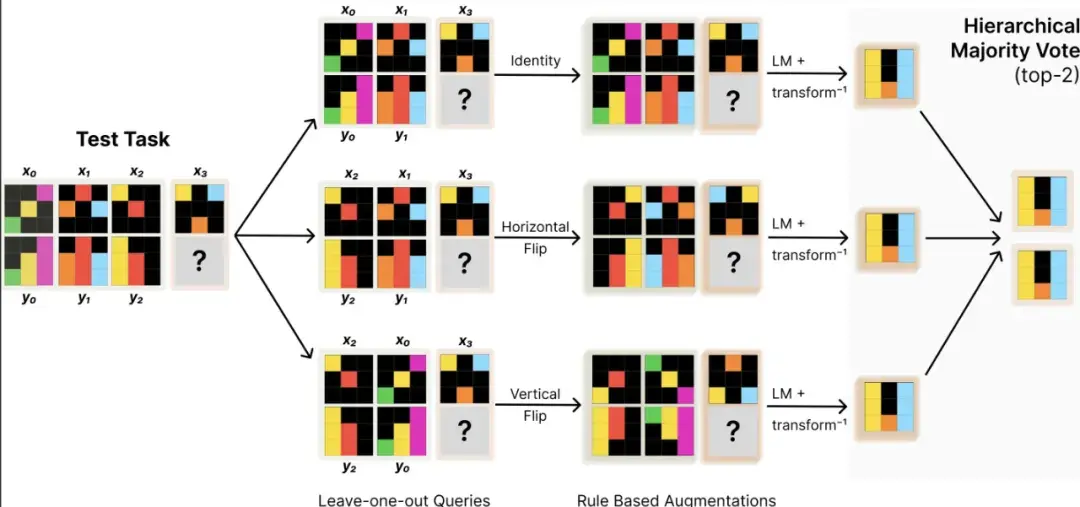
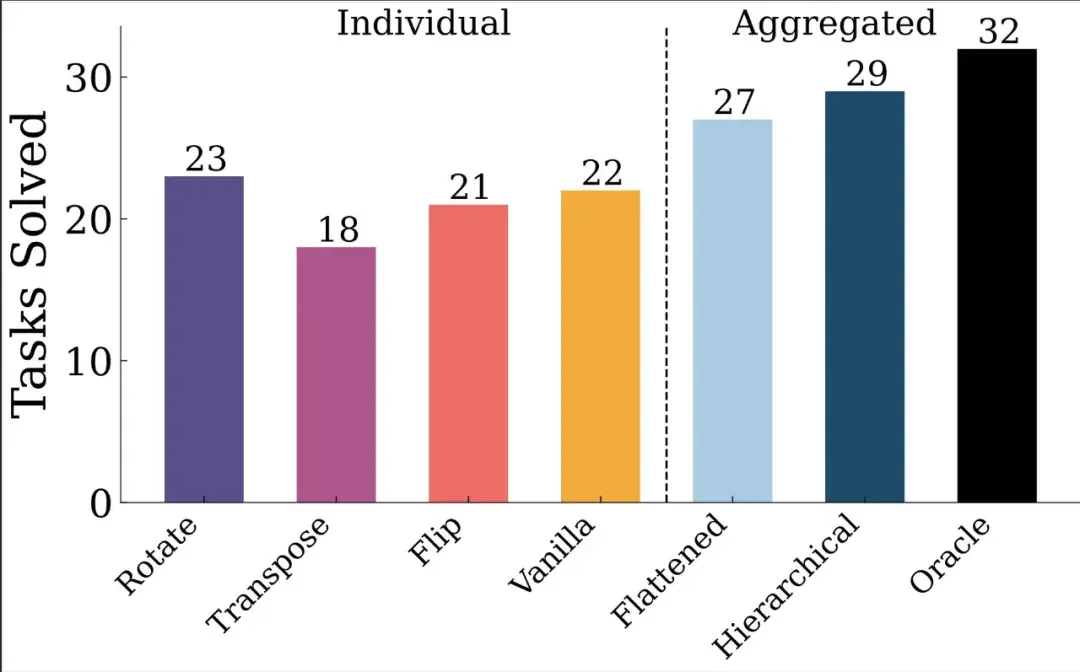
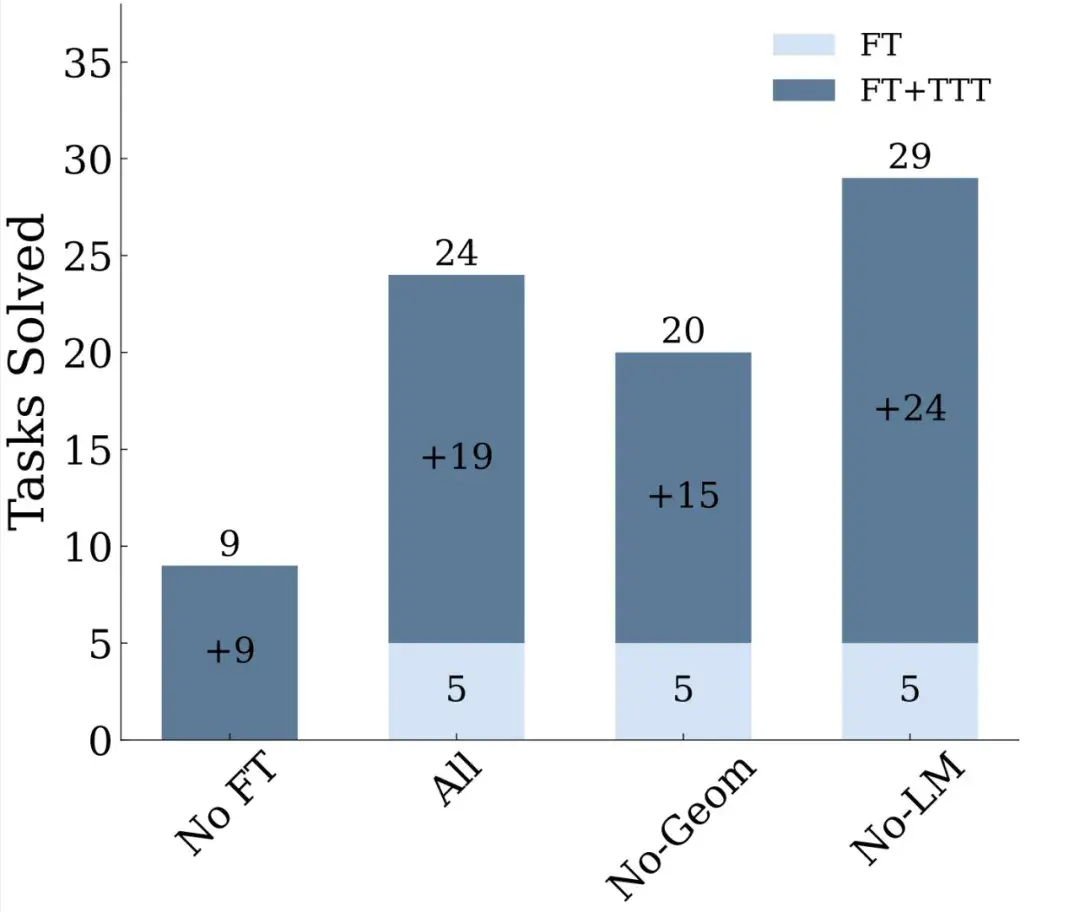
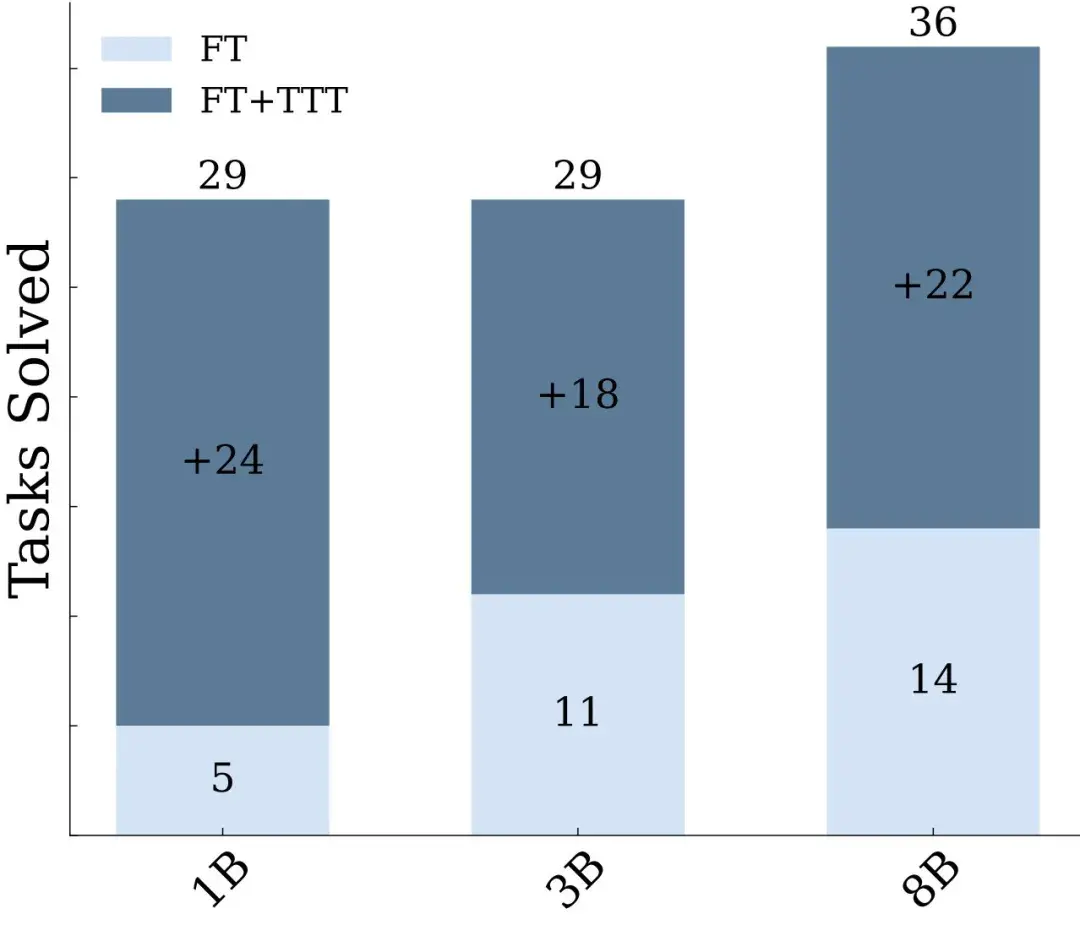
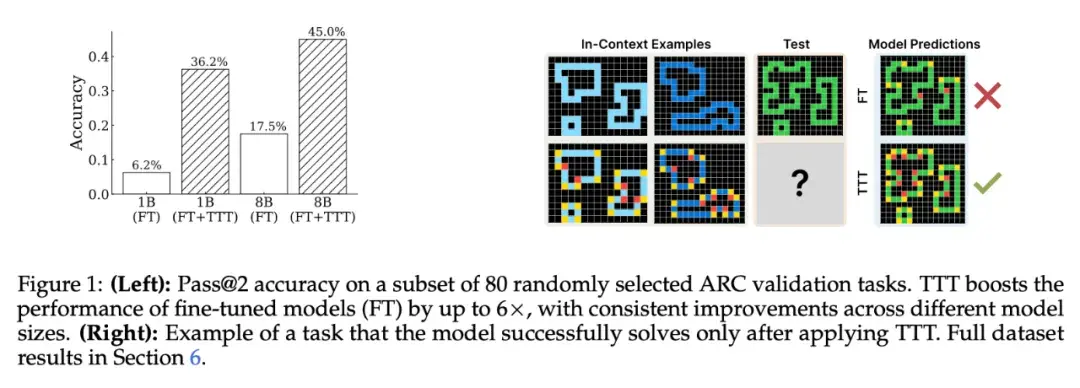
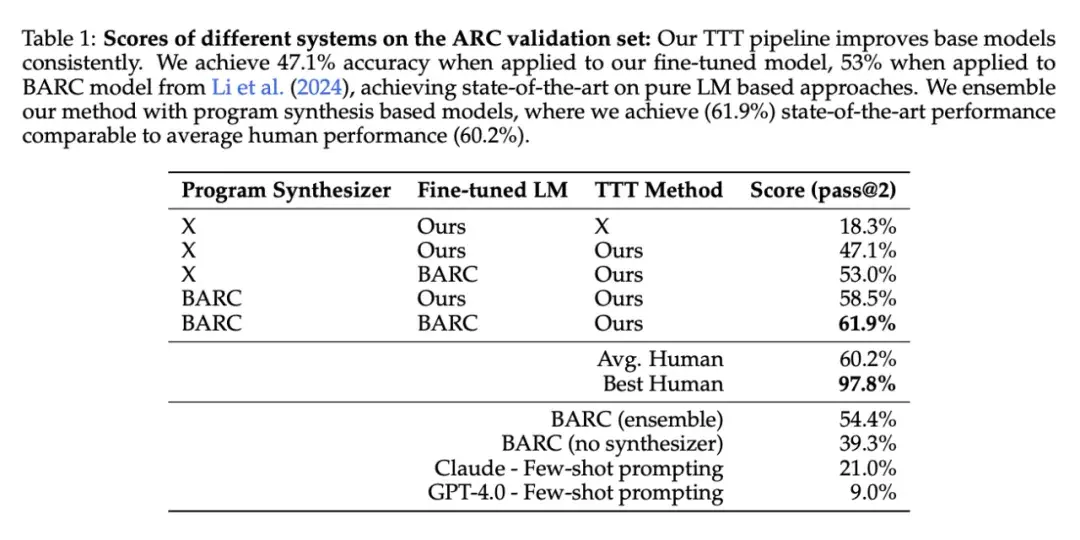
这篇文章引发了业界对于未来 AI 迭代方向的讨论 —— 虽然 Scaling Law 放缓这一说法令人担忧,但其中也不乏乐观的声音。有人认为,虽然从预训练来看,Scaling Law 可能会放缓;但有关推理的 Scaling Law 还未被充分挖掘,OpenAI o1 的发布就证明了这一点。它从后训练阶段入手,借助强化学习、原生的思维链和更长的推理时间,把大模型的能力又往前推了一步。这种范式被称为「测试时计算」,相关方法包括思维链提示、多数投票采样(self-consistency)、代码执行和搜索等。

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-12-25 14:45
发表于 2024-12-25 14:45