金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
谢邀(捂脸///)生信直博在读,并没有找生信工作的经验。那就从学生信的角度说一点点我的理解吧~
1.编程
Linux:会用Editor(e.g. VIM) 和 Shell Script (e.g. bash);推荐《鸟哥的Linux私房菜-基础学习篇》
Python/Perl:《Python编程入门(第3版)》,Perl推荐小骆驼
R:《R语言实战(R in action)》
如果做数据库或者server,推荐再学PHP,MySQL,JavaScript
2.课程
Bioinformatics: 生物信息导论和方法(北大高歌老师的课程,讲解逻辑清晰,由浅入深),MOOC。
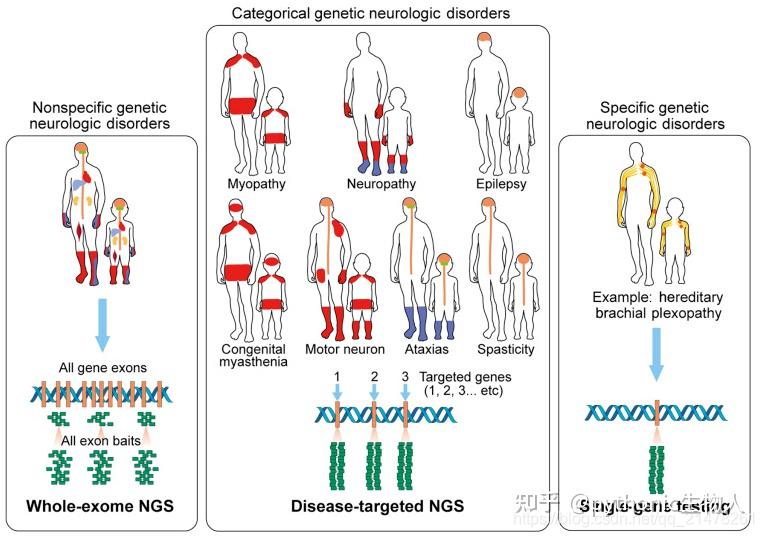
因为生信有好多分支,如对基因组、蛋白质组学数据分析并给出生物学解释;在研究算法方面,如利用机器学习的各种原理来解决生物学问题(对基因序列原件的注释,如对TSS,splicing sites,promoters,enhancers,positioned nucleosomes等功能区域的注释;通过对RNA-seq,microarray,ChIP-seq等数据的分析,区分不同的疾病类型或疾病的分子标志物(biomarkers);对基因功能的注释,如Gene Ontology term;以及基因间互作调控网络的分析);比如运用统计学知识改进已有的生信软件的算法,等等。可以根据将来要做什么继续补充知识,比如看一下斯坦福大学的Andrew Ng在coursera的机器课程呀 ,看一下统计学原理呀之类的。
3.文献和实战练习
如果是做基因组学的生信公司
3.1 RNA数据分析流程
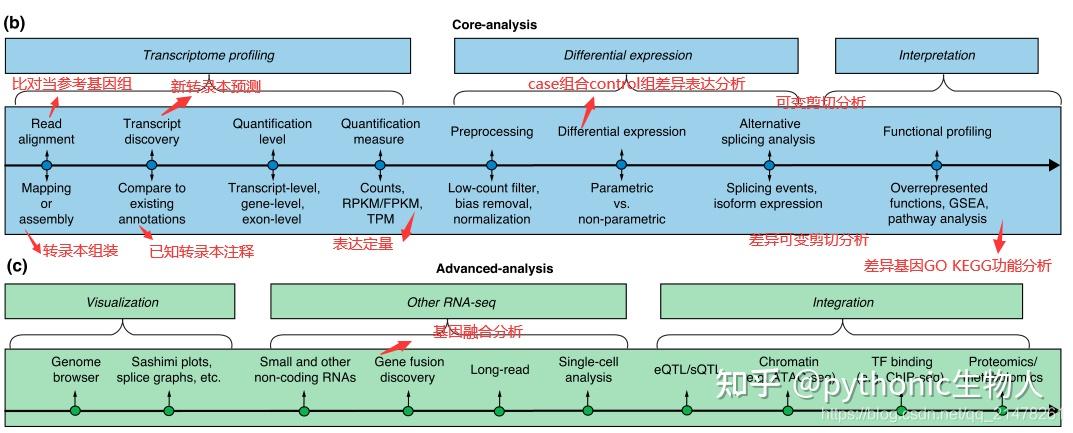
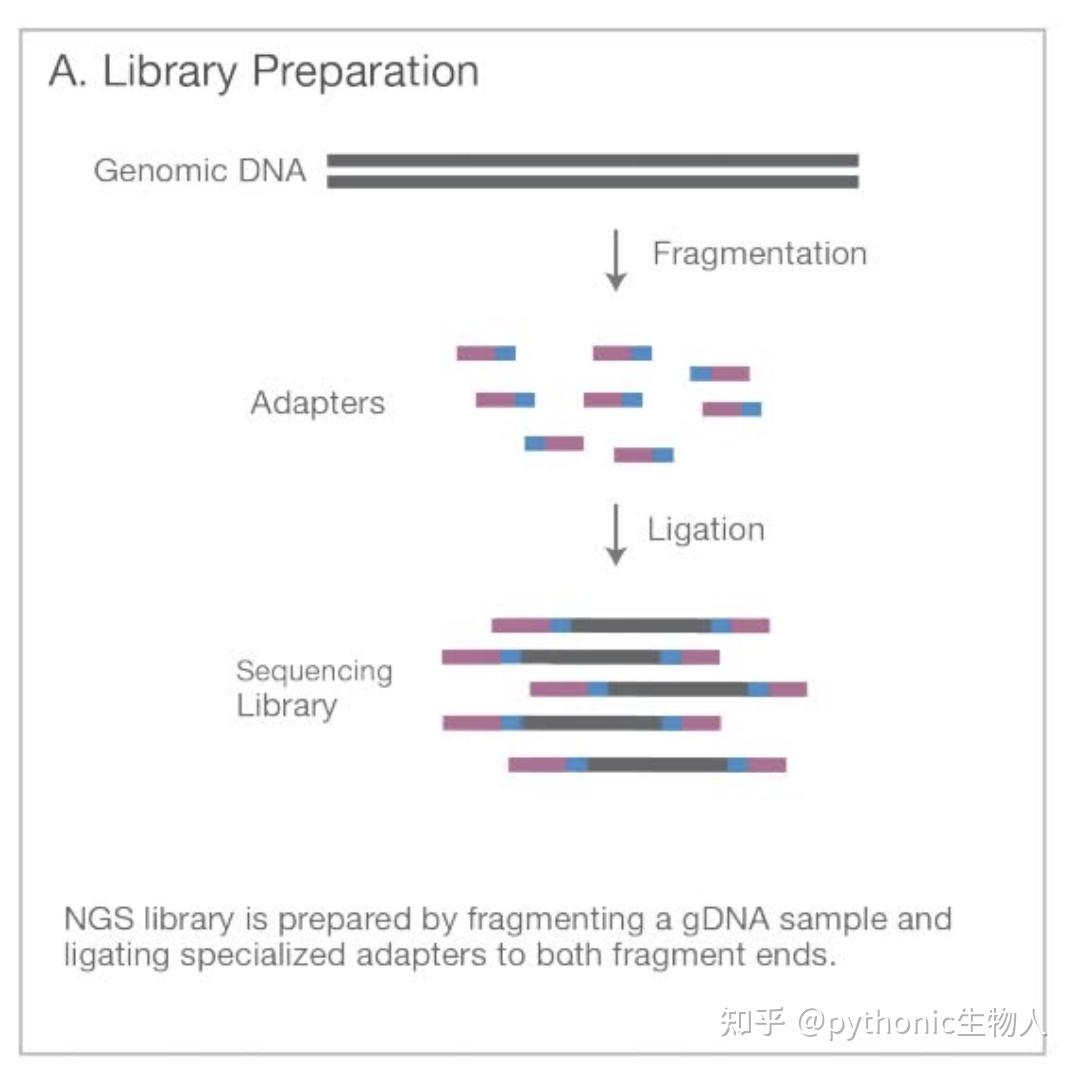
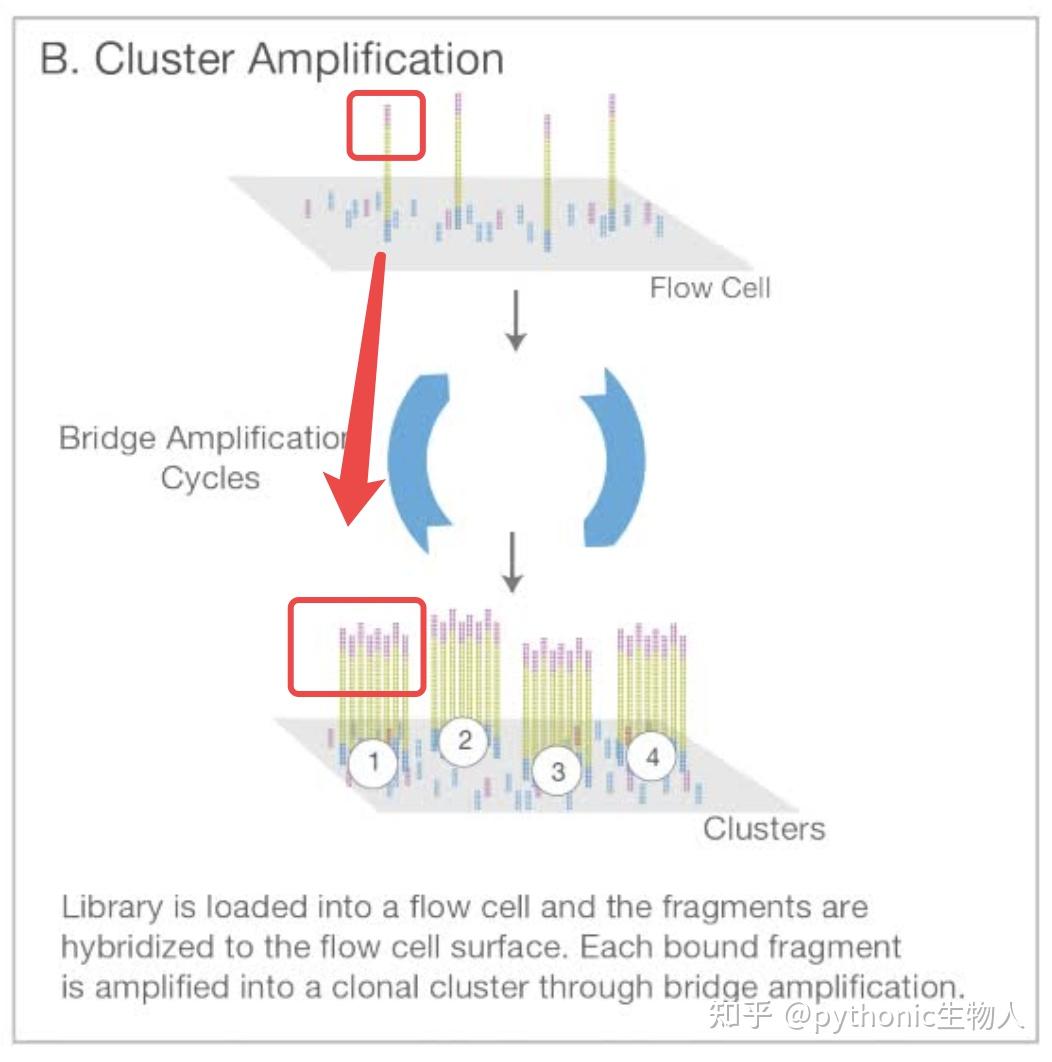
RNA-seq:可以重复一下文章中的分析Differential gene and transcript expression analysis of RNA-seq experiments with TopHat and Cufflinks[1]
当然入门之后可以更多了解相关软件啦,比如STAR,feature counts, Gfold, EdgeR, DESeq2,
DESeq等。
找lncRNA:Recurrently deregulated lncRNAs in hepatocellular carcinoma [2]. 这篇文章中有如何找新lncRNA的流程,可以根据文章提供的方法重复一下。
3.2 DNA数据分析流程
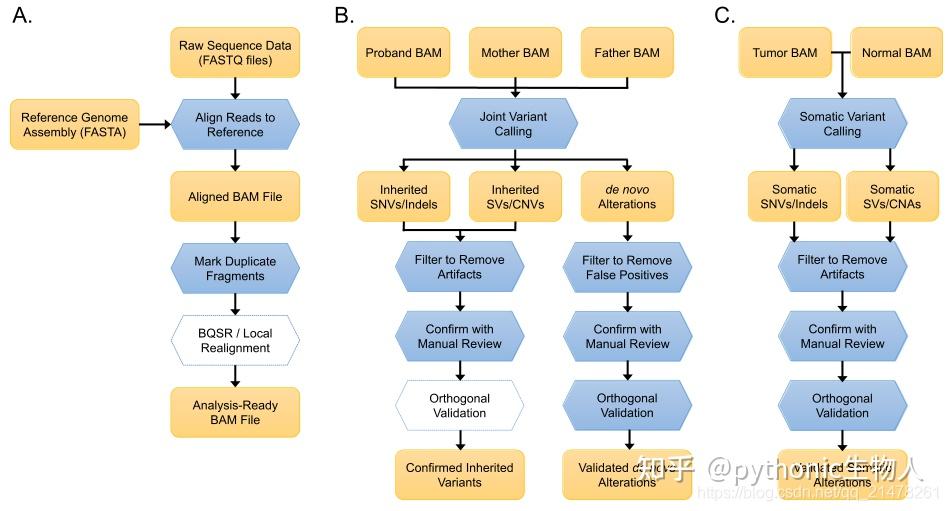
GATK那一套流程检测
同时variant与疾病、eQTL等关联分析的话,可以了解一下STATA
3.3
结合机器学习和基因组学的话,可以看一下以下文献:
DeepVariant:由谷歌Deep mind公司研发,利用卷积神经网络(convolutional neural network, CNN)检测基因组上单碱基突变(SNP)和小的插入缺失(Indel),比现有的GATK软件有更高的精确度 [3]。
DeepWAS:根据功能单元选择出一组SNP的集合,与现有的基因组关联分析(GWAS)检测基因组上一个SNP与疾病的关系相比,DeepWAS能够更综合地分析致病基因突变,在寻找调控区域的基因突变也更为直接[4]。
DeepSEA:预测人类基因组非编码区有功能的变异 [5]。
DeepBind:预测DNA,RNA结合蛋白的序列特征,并能识别有害的基因突变 [6]。
DeepCpG:在表观遗传学层面上,应用深度神经网络算法,研发了通过单细胞测序的DNA序列和不完整的甲基化修饰数据的,用来预测细胞细胞层面是否会发生甲基化,其效果优于现有软件[7]。
暂时就想起来这么多啦~
1. Trapnell, C., et al., Differential gene and transcript expression analysis of RNA-seq experiments with TopHat and Cufflinks. Nat Protoc, 2012. 7(3): p. 562-78.
2. Yang, Y., et al., Recurrently deregulated lncRNAs in hepatocellular carcinoma. Nat Commun, 2017. 8: p. 14421.
3. Poplin, R., et al., Creating a universal SNP and small indel variant caller with deep neural networks. bioRxiv, 2016: p.092890.
4. Eraslan,G., et al., DeepWAS: Directly integrating regulatory information into GWAS using deep learning supports master regulator MEF2C as risk factor for major depressive disorder. bioRxiv, 2016: p.069096.
5. Zhou, J. and O.G. Troyanskaya, Predicting effects of noncoding variants with deep learning-based sequence model. Nature methods, 2015. 12(10): p.931-934.
6. Alipanahi, B., et al., Predicting the sequence specificities of DNA-and RNA-binding proteins by deep learning. Nature biotechnology, 2015. 33(8): p.831-838.
7. Angermueller, C., et al., Accurate prediction of single-cell DNA methylation states using deep learning. bioRxiv, 2016: p.055715. |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2024-11-11 22:03
发表于 2024-11-11 22:03


 提升卡
提升卡