金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
FISH-SPEECH: LEVERAGING LARGE LANGUAGE MODELS FOR ADVANCED MULTILINGUAL TEXT-TO-SPEECH SYNTHESIS
keywords: 语音大模型,语音合成,语音克隆
出版单位:Fish Audio
Demo page:Demo
快速阅读:FishSPeech的技术报告,三大创新点——快慢自回归,改进的GAN,改进的量化
摘要
语音合成(TTS)系统在处理复杂语言特征、处理多音表达以及生成自然流畅的多语言语音方面面临着持续的挑战,而这些能力对未来的人工智能应用至关重要。在本文中,我们介绍了Fish-Speech,这是一种新颖的框架,它采用了一种串行快慢双自回归(双AR)架构,以提高分组有限标量矢量量化(GFSQ)在序列生成任务中的稳定性。这种架构在保持高保真输出的同时提高了码本处理效率,使其在人工智能交互和语音克隆方面尤为有效。 Fish-Speech利用大型语言模型(LLMs)进行语言特征提取,无需传统的字素到音素(G2P)转换,从而简化了合成流程并增强了对多语言的支持。此外,我们通过分组有限标量矢量量化(GFSQ)开发了快速前馈生成对抗网络(FF-GAN),以实现出色的压缩率和接近100%的码本利用率。 我们的方法解决了当前语音合成(TTS)系统的关键局限性,同时为更复杂、能感知上下文的语音合成奠定了基础。实验结果表明,在处理复杂语言场景和语音克隆任务方面,Fish-Speech明显优于基线模型,这证明了它在人工智能应用中推动语音合成技术发展的潜力。该实现的代码已在https://github.com/fishaudio/fish-speech开源。
Introduction
过去十年间,语音合成(TTS)系统取得了显著进展,其应用范围已从虚拟助手拓展到教育工具等领域。当前的TTS架构,比如VALL-E(王等人,2023年)、VITS(金等人,2021年)、FastSpeech(任等人,2020年)等,通常在合成之前依靠字素到音素(G2P)转换(克拉特,1987年)将文本转化为语音表示形式。虽然这种方法行之有效,但由于语音规则复杂,在处理依赖于上下文的多音词以及跨语言泛化方面存在困难。 近期在零样本语音转换方面的进展,如YourTTS(卡萨诺瓦等人,2022年)以及统一语音生成模型UniAudio(杨等人,2023年),已经展示了神经网络架构在处理各类语音任务方面的潜力。此外,像CosyVoice(杜等人,2024年)、MatchaTTS(梅塔等人,2024年)等基于流的模型在自然语音合成方面也取得了颇具前景的成果。然而,大多数解决方案为了提高稳定性,将语义特征和声学特征解耦,作为一种权衡取舍,这也降低了语音克隆/背景理解的能力。
随着对多语言语音合成(TTS)系统需求的增长,基于字素到音素(G2P)转换方法的局限性愈发明显。对特定语言语音规则和词典的需求阻碍了可扩展性,并使系统维护变得复杂。近期研究已经探索了利用大型语言模型(LLMs)进行直接的语言特征提取,从而无需进行明确的字素到音素(G2P)转换。(贝特克,2023年)
我们推出了Fish-Speech,这是一种新颖的语音合成(TTS)框架,其特色在于采用了一种串行快慢双自回归(双AR)架构。这种设计在保持高质量输出的同时,提高了分组有限标量矢量量化(GFSQ)在序列生成过程中的稳定性。通过将大型语言模型(LLMs)融入语音合成流程,Fish-Speech简化了合成过程,并且能更好地处理多音字符和多语言文本。该模型基于72万小时的多语言音频数据进行训练,使其能够学习到多样的语言模式和发音变化。
为了提高合成质量,我们开发了萤火虫生成对抗网络(FFGAN),这是一种基于分组有限标量矢量量化(GFSQ)的新型声码器架构。FFGAN将有限标量量化(FSQ)(门策尔等人,2023年)与分组矢量量化(GVQ)相结合,以优化压缩率和码本使用率。我们的评估结果显示码本利用率达到了100%,代表了该领域的前沿性能。
这项工作的主要贡献如下: - 我们推出了Fish-Speech,这是一种新颖的语音合成(TTS)框架,它利用大型语言模型(LLMs)和双自回归(Dual-AR)架构来取代传统的字素到音素(G2P)转换,从而提供稳健且可扩展的多语言语音合成功能。 - 我们提出了萤火虫生成对抗网络(FFGAN),这是一种先进的声码器,它集成了多种矢量量化技术,能够在优化压缩率和码本利用率的情况下实现高保真语音合成。 - 我们开发了鱼类技术加速方法,该系统在消费级NVIDIA RTX 4060移动平台上实现了约1:5的实时系数,在高性能NVIDIA RTX 4090配置上实现了1:15的实时系数。并且其延迟为150毫秒,远低于其他采用离散积分变换(DiT)和流结构的语音合成(TTS)系统。
我们鼓励读者聆听我们在fish speech 1.4版本示例中的音频样本。我们还强烈建议您访问我们的在线合成网站fish.audio,尝试体验由社区合成的不同发音人的音频。
相关工作
2.1 TTS
语音合成(TTS)系统已经发生了巨大的演变,从基于基本音素的模型发展到能够直接将文本转换为语音的复杂的端到端神经学方法(谭等人,2021年)。这种转变是由深度学习的进步以及计算能力的提升所推动的,它使得语音的自然度、韵律控制以及跨语言能力都得到了重大改善(任等人,2019年)。现代语音合成系统如今服务于各种各样的应用,从智能助手到辅助功能工具以及人机界面(卡佩斯等人,2017年)。
2.2 神经声码器
神经声码器在提高语音合成质量方面发挥了关键作用。WaveNet(范登奥尔德等人,2016年)首次将自回归模型引入音频生成领域,随后出现了更高效的架构,如WaveRNN(卡尔克布伦纳等人,2018年)和WaveGrad(陈等人,2020年)。HiFi-GAN(孔等人,2020年)后来引入了对抗训练,在音频质量和计算效率方面树立了新的标准。EVA-GAN是英伟达公司(廖等人,2024年)研发的一种全新的生成对抗网络(GAN)结构声码器,它使用了一个上下文感知模块(CAM),以在极小的计算开销下提升性能。EVA-GAN在客观和主观指标上都展现出优于现有最先进声码器的性能,尤其在频谱连续性和高频重建方面表现突出。
2.3 语音合成中的矢量量化
矢量量化(VQ)在现代语音合成中已变得至关重要。矢量量化变分自编码器(VQ-VAE)(范登奥尔德等人,2017年)展示了离散潜在表示在音频生成方面的有效性,而SoundStream(泽吉杜尔等人,2021年)和EnCodec(德福塞等人,2022年)进一步改进了这些用于高质量音频压缩和合成的技术。
2.4 语音处理中的大型语言模型
大型语言模型(LLMs)在语音处理中变得越来越重要。如今,有越来越多的模型将BERT、HuBERT用作语音合成(TTS)的中间结构,比如Parler TTS(拉孔布等人,2024年)、MeloTTS(赵等人,2023年)、E3 - 语音合成(E3 - TTS)(高等人,2023年)、扩展 - 语音合成(XTTS)(卡萨诺瓦等人,2024年)等等。它们都取得了更好的合成效果。
2.5 多语言语音合成
多语言语音合成在保持各语言间质量一致方面面临着独特的挑战。近期的解决方案包括统一多语言模型(刘和麦,2019年)、跨语言迁移学习(内克温达和杜谢克,2020年)以及与语言无关的表征(李等人,2019年)。
Method
Fish-Speech是一种新颖的语音合成(TTS)框架,它解决了当前非字素到音素(非G2P)语音合成系统的关键局限性。该框架专门用于处理多情感和多语言的语音合成,重点在于满足先进人工智能对话代理的需求。
基于矢量量化和条件表示方面的近期进展(库马尔等人,2024年;陈等人,2023年;王等人,2019年),我们引入了一种分组有限标量矢量量化(GFSQ)技术。这种方法能有效地对潜在条件进行编码,从而能够更好地捕捉和重现细微的语音变化。我们的方法实现了100%的码本利用率,最大限度地发挥了量化空间的效能。
我们还开发了一种双自回归(dual-AR)架构,该架构解决了当前语音合成(TTS)系统中的两大主要挑战。首先,它提高了代码生成的稳定性,这是现有框架中普遍存在的一个问题。其次,与扩散变换器(DiT)相比,它能提供更高的生成效率,使其非常适合实时应用场景。最后,但也是最重要的一点是,它已为语音助手做好了准备,我们将在不久的将来发布这款语音助手。
3.1 Fish-Speech中的双自回归架构
本节将介绍Fish-Speech的双自回归(Dual-AR)架构(见图2),Fish-Speech是一个旨在处理复杂语言特征、多音词以及生成自然流畅的多语言语音合成的语音合成(TTS)系统。双自回归架构提高了在序列生成过程中码本处理的稳定性和计算效率,尤其是在使用分组有限标量矢量量化(GFSQ)时更是如此。
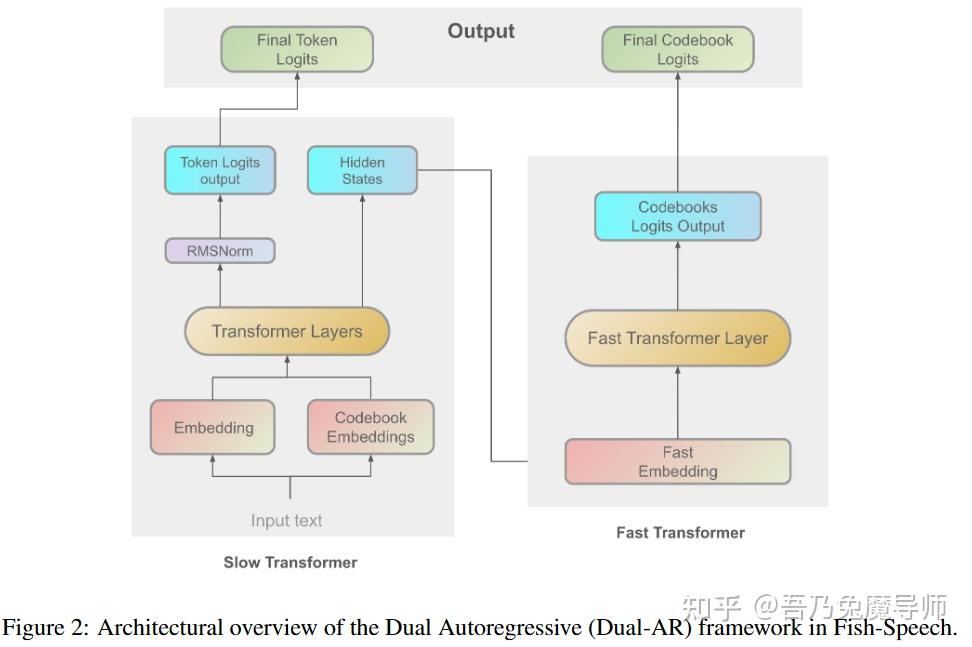
3.1.1 双自回归架构概述
双自回归架构由两个顺序的自回归变换器([瓦斯瓦尼,2017年;苏巴坎等人,2021年]所提及)模块组成:一个慢速变换器和一个快速变换器([杨等人,2023年]所提及)。这种设计能高效地处理语音合成的高层次和细节方面的内容。
Slow Transformer 慢速变换器处理输入的文本嵌入,以捕捉全局语言结构和语义内容。它生成中间隐藏状态并预测语义标记。
慢速变换器在较高的抽象层面发挥作用,它处理输入的文本嵌入,对全局语言结构和语义内容进行编码。该模块负责生成中间隐藏状态,并高精度地预测语义标记。
给定一个标记的输入序列 x = [x_1, x_2, \ldots, x_T] ,慢速变换器通过以下变换生成隐藏状态 h \in \mathbb{R}^{T×D} 以及标记对数几率z:
h=SlowTransformer\times (x) \qquad(1)$
z=W_{tok} \cdot Norm(h) \qquad(2)
其中$Norm(\cdot)$表示层归一化,$W_{tok}$表示标记预测层的可学习参数。
Fast Transformer 快速变换器通过码本嵌入处理来细化慢速变换器的输出,捕捉自然语音所需的详细声学特征。它处理残差信息并优化码本的使用。
快速变换器根据以下方式将隐藏状态h和码本嵌入c的拼接序列作为输入:
\tilde{h} = [h; c], (h^{fast}) \qquad(3)
h^{fast} = FastTransformer(\tilde{h}, (h^{fast})) \qquad(4)
y = W_{cbk} \cdot Norm(h^{fast}) \qquad(5)
其中[h; c]表示h和c的拼接操作, W_{cbk} 构成码本预测层的可学习参数,y表示生成的码本对数几率。
3.1.2双自回归架构的优势
Fish-Speech中的双自回归架构展现出了几个显著的优势: 1. 增强的序列生成稳定性:对全局和局部信息的分层处理极大地提高了分组有限标量矢量量化(GFSQ)在序列生成任务中的稳定性。 2. 优化的码本处理:快速变换器实现了一种高效的码本嵌入处理机制,该机制在不产生显著计算开销的情况下提升了性能,尤其对于70亿参数或更大规模的模型而言。 3. 卓越的语音合成质量:慢速变换器和快速变换器之间的协同交互能够实现高保真语音合成,可处理复杂的语言现象。 4. 先进的多语言处理:与大型语言模型(LLMs)集成以生成语言特征,消除了对传统字素到音素转换的依赖,从而简化了语音合成流程并增强了多语言处理能力。通过混合文本数据,理解能力将得到进一步提升。
3.2 萤火虫生成对抗网络(Firefly-GAN)
萤火虫生成对抗网络(Firefly-GAN,简称FF-GAN)是EVA-GAN架构的增强版本,在结构上有显著改进。它用一种更高效的设计取代了HiFi-GAN([孔等人,2020年])中的传统卷积组件,采用了并行模块(ParallelBlock)而非多感受野(Multi-Receptive Field,简称MRF)模块。通过引入分组有限标量矢量量化(Grouped Finite Scalar Vector Quantization,简称GFSQ)技术,FF-GAN实现了更好的序列生成稳定性,并能更出色地处理语言变化,这使得它在人工智能应用的多语言合成方面尤为有效。
萤火虫生成对抗网络(Firefly-GAN,简称FF-GAN)是EVA-GAN架构的增强版,在结构上有重大改进。该模型采用了一种优化结构,取代了HiFi-GAN([孔等人,2020年])中常见的卷积和转置卷积组件。我们使用并行模块(ParallelBlock)来替代多感受野(Multi-Receptive Field,简称MRF)模块,后者是专门为错码本声码器应用而设计的。通过整合分组有限标量矢量量化(Grouped Finite Scalar Vector Quantization,简称GFSQ)方法,FF-GAN展现出更强的序列生成稳定性,能有效处理复杂的语言变化并促进自然的多语言合成。这种架构创新使得FF-GAN有别于传统声码器,尤其在人工智能代理框架内的语音合成和语音克隆应用方面表现突出。
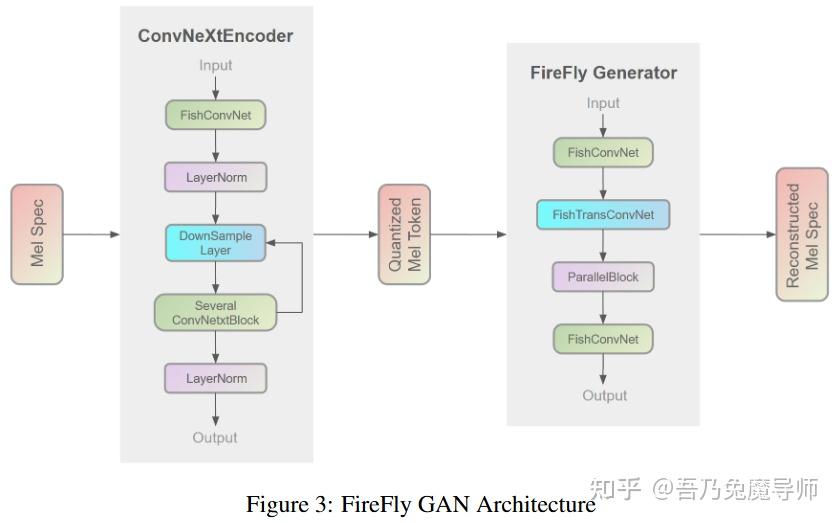
3.2.1 Firefly Generator
萤火虫生成对抗网络(FF-GAN)采用了增强的卷积结构,包括深度可分离卷积(霍华德,2017年提及)和扩张卷积(于,2015年提及),以此取代了传统的一维卷积层。这种架构上的优化提升了该模型捕捉和合成复杂音频特征的能力。
在我们的架构中,传统的多感受野(MRF)模块被并行模块(ParallelBlock)所取代,从而优化了错码本输入处理效率。并行模块(ParallelBlock)实现了可配置的卷积核大小和扩张率(于,2015年提及),它利用堆叠与平均机制来处理三个残差块(ResBlocks)的输出,而非直接进行相加操作。并行模块(廖等人,2024年提及)提供了更强的感受野覆盖范围、更出色的特征提取能力以及更好的可配置性,有助于实现更高质量的音频合成。
3.2.2 量化技术
为了适应错码本任务,我们在系统中使用分组有限标量矢量量化(GFSQ)作为矢量量化码本。下面的内容将详细阐述我们是如何开发GFSQ的。
给定一个输入张量 z \in \mathbb{R}^{B×C×L} 。整个过程包括以下步骤:
下采样 使用下采样函数 f_{down} 对输入张量z进行下采样,得到一个下采样后的张量 z_{d} \in \mathbb{R}^{B×C_{d}×L_{d}} :
z_{d}=f_{down}(z) \qquad (6)
分组有限标量矢量量化(GFSQ)流程
- 特征分组:输入特征矩阵z被划分为G个组:
Z = [Z^{(1)}, Z^{(2)}, \ldots, Z^{(G)}] \qquad (7)
- 标量量化:对于每个标量 z_{b, c, l}^{(g)}
\hat{z}{b, c, l}^{(g)} = Q(z{b, c, l}^{(g)})\ \qquad(8)
- 索引生成:每个标量映射到索引 k_{b, c, l}^{(g)}
- 解码:
\hat{z}_{b, c, l}^{(g)} = Codebook^{(g)}[k_{b, c, l}^{(g)}]\ \qquad(9)
重建量化后的下采样张量 沿通道维度将所有组的量化向量拼接起来,以获得量化后的下采样张量 z_{q_{d}} \in \mathbb{R}^{B×C_{d}×L_{d}} :
z_{q_{d}}(b, :, l)=\left[z_{q_{d}}^{(1)}(b, :, l) ; z_{q_{d}}^{(2)}(b, :, l) ; \ldots ; z_{q_{d}}^{(G)}(b, :, l)\right] \qquad(10)
上采样 使用上采样函数 f_{up} 将量化后的下采样张量恢复到其原始大小,从而得到最终的量化张量 z_{q} \in \mathbb{R}^{B×C×L_{q}} ,即
z_{q}=f_{up}(z_{q_{d}})\ \qquad(11)
目标是让 z_{q} 尽可能紧密地逼近原始输入z:
z_{q} \approx z \qquad(12)
3.2.3 结论
我们对分组有限标量矢量量化(GFSQ)技术的应用实现了近乎100%的码本利用率,并且在我们内部的消融实验中,相较于其他量化技术(如相对有限标量矢量量化(RFSQ)、残差矢量量化(RVQ)和分组相对有限标量矢量量化(GRFSQ))获得了更好的客观和主观评分。萤火虫生成对抗网络(FF-GAN)显著增强了错码本操作的稳定性,并确保在多情感和多语言任务中全面保留中间变量信息。
萤火虫生成对抗网络(FF-GAN)在错码本稳定性方面的创新方法已经应用于各类歌曲和音乐生成应用中。该框架的性能和架构使其有望成为未来人工智能代理开发的参考模型。
训练和推理
4.1 训练
Fish Speech采用了一种三阶段的训练方法:首先使用大量标准数据进行初始预训练,接着使用小批量高质量数据进行监督微调(SFT),最后使用人工标注的正负样本对进行直接偏好优化(DPO)训练。
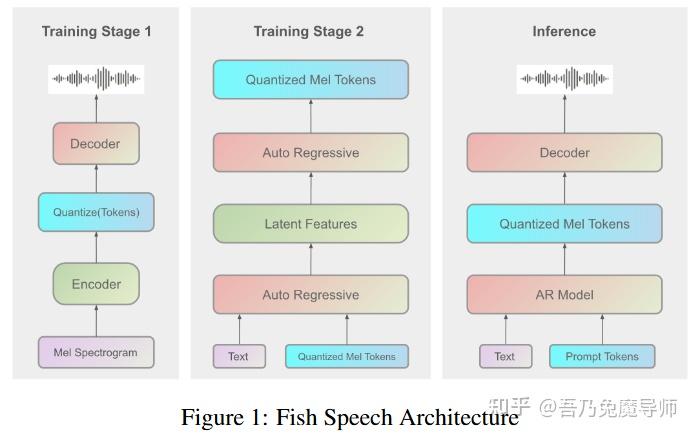
训练基础设施分为两个部分(见图1):自动回归(AR)训练使用8块H100 80G显存的GPU进行了一周,而声码器训练则使用8块4090 GPU又进行了一周。需要注意的是,这些时间安排不包括直接偏好优化(DPO)阶段。
4.2 推理
我们的推理策略遵循图1所示的架构。通过运用包括键值缓存(KV-cache,波普等人,2023年提及)、Torch编译以及其他加速方法在内的鱼技术(fish-tech),该系统在消费级的英伟达RTX 4060移动平台上实现了约1:5的实时系数,在高性能的英伟达RTX 4090配置下实现了1:15的实时系数。这些架构上的优化显著降低了推理延迟,实现了首包延迟为150毫秒。此外,该系统能够流式处理信息,使其易于与现代人工智能工具配合使用,并能应用于不同场景。
数据集
我们的训练数据包含大量来自公开来源以及我们自己的数据收集流程的语音样本。该数据集涵盖了不同语言的约72万小时语音,其中英语和汉语普通话各占30万小时,是主要组成部分。我们还分别纳入了其他语系各2万小时的语音,这些语系包括日耳曼语系(德语)、罗曼语系(法语、意大利语)、东亚语系(日语、韩语)以及闪米特语系(阿拉伯语)。
我们仔细地对不同语言的数据进行了平衡处理,以帮助模型同时学习多种语言。这种方法有助于模型在生成混合语言内容时表现出色。我们数据集的规模庞大且种类多样,这极大地提高了模型自然处理多种语言的能力。
实验评估
我们针对说话人克隆任务进行了一项评估,以了解相较于基线模型,我们的架构所产生的效果。评估方法包括客观和主观指标:用于可懂度评估的词错误率(WER)、用于语音克隆保真度评估的说话人嵌入相似度度量,以及用于感知质量量化的平均意见得分(MOS)。这一评估框架旨在评估模型在保持高保真语音合成的同时保留说话人身份特征的能力。
6.1 词错误率分析
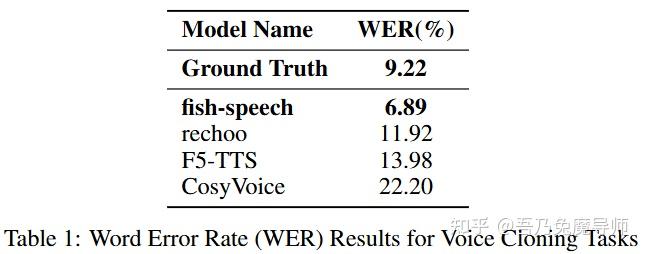
对表1的分析表明,我们的模型在语音克隆任务中实现了6.89%的词错误率,这不仅远低于基线模型,甚至还优于真实录音(9.22%)。这一表现有力地证明了我们的模型在语音克隆场景中的能力。我们的模型与其他竞争模型之间的差距(从11.92%到22.20%不等)凸显了我们的方法在合成稳定性和内容保真度方面的提升。
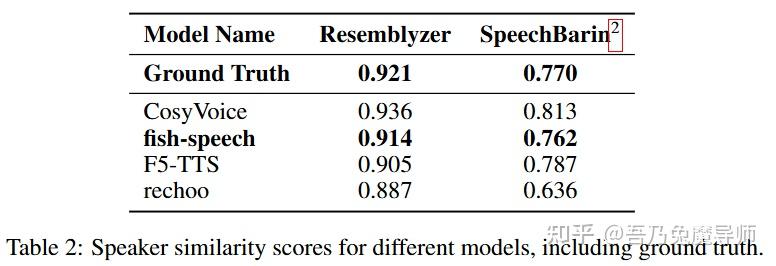
6.2 说话人相似度分析
表2展示了我们的错码本策略对说话人相似度指标的影响。我们的鱼语音(fish-speech)模型在Resemblyzer和SpeechBrain上分别取得了0.914和0.762的相似度得分,这与真实表现(分别为0.921和0.770)极为接近。在Resemblyzer评估中与真实情况仅相差0.76%,在SpeechBrain评估中相差1.04%,这表明我们的模型在捕捉自然语音特征方面具有卓越的能力。这些结果有力地表明,我们的错码本架构能够更全面地捕捉声学状态,从而提高合成语音的音色保真度。我们的方法明显优于诸如F5 - TTS(0.905和0.787)以及rechoo(0.887和0.636)等基线模型。在这两种评估框架下的一致表现证明了我们的方法在保留说话人特征方面的有效性,这对于高质量的文本到语音合成以及智能体任务至关重要。
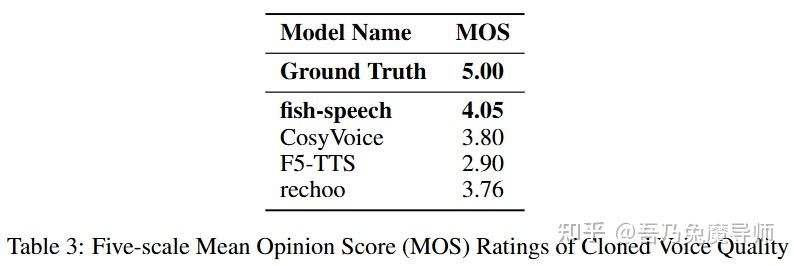
6.3 感知质量评估
为了评估合成音频的感知质量,我们针对那些此前没有音频处理经验的普通听众开展了一项全面的平均意见得分(MOS)听力测试。评估采用双盲、随机的方法以确保评估的公正性。结果显示,与其他基线模型相比,鱼语音(fish-speech)获得了显著更高的主观评分(p < 0.05),这表明它在语音自然度和说话人相似度方面表现卓越。这种在人类感知指标方面的评估有力地表明,鱼语音能够更好地捕捉并重现人类语音的自然特征,尤其在语音克隆任务的情境下更是如此。
总结
我们的研究通过引入一种新颖的多语言、多情感稳定化解决方案,在文本到语音(TTS)领域取得了重大进展。核心创新在于我们开发了一种与双自动回归(双-AR)生成架构相结合的错码本声码器。这种架构组合在合成过程中展现出了稳定性,同时保留了生成语音中的声学特征。此外,我们的工作还利用了一种非字素到音素(非G2P)结构,这种方法有效地解决了传统基于音素的系统所固有的局限性,为跨语言和情感多样的文本到语音(TTS)应用提供了坚实的基础,尤其在人工智能智能体交互的情境下更是如此。
未来工作
在这些基础之上,我们为未来的研究提出了几个方向。我们计划通过整合强化学习技术来提升我们模型的性能,重点关注提高跨语言泛化能力和情感稳定性。我们还在开发“鱼智能体”应用程序,这是一个基于我们的“鱼语音”框架的端到端语言模型。该系统的初步演示目前可在fish.audio/demo/live上获取。我们始终致力于开源社区,并将继续维护和扩展我们的代码库,以便为研究人员和开发者提供更广泛地获取这些技术的途径。
原文地址:https://zhuanlan.zhihu.com/p/5499575409 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-11-10 22:50
发表于 2024-11-10 22:50



