金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
这篇文章着重点不在于科普,毕竟关于CAP理论的文章,网上很多。所以本文科普篇幅尽量小(只包含概念描述)
本文通过以下几个问题,从侧面描述。文中个人观点较多,看官理性对待。
- 为什么CAP三者不可兼得?
- 实践中,怎么应用CAP?
- 不考虑一致性的系统,有什么存在的意义呢?
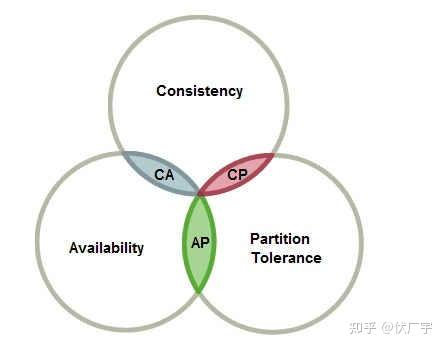
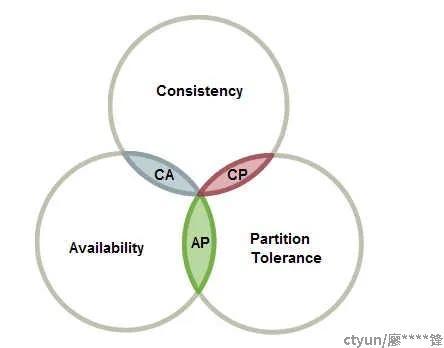
CAP定理科普
CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。这三个要素最多只能同时实现两点,不可能三者兼顾。
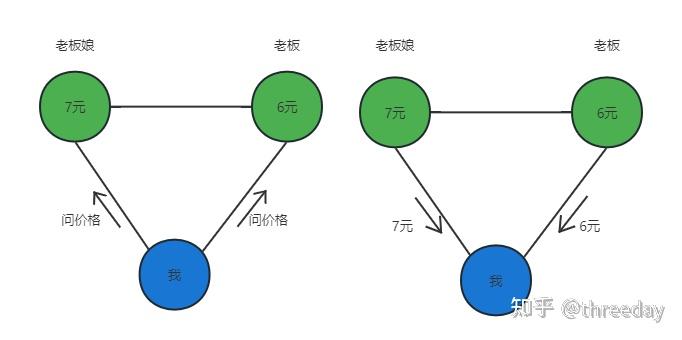
- 一致性(C):这里是指100%强一致性。在分布式系统中的所有数据备份,在同一时刻整个系统的副本都拥有的一致的数据。
- 可用性(A):这里是指100%可用性。客户端无论访问到哪个没有宕机的节点上,都能在有限的时间内返回结果,并不是指整个系统处于可用状态。
- 分区容错性(P):网络中允许丢失一个节点发给另一个节点的任意多的消息,即对网络分区的容忍。在发生网络分区时,能继续保持可用性或者一致性。如果一个系统要求在运行过程中不能发生网络分区,那么这个系统就不具备分区容错性。
为什么CAP三者不可兼得?
在分布式系统中,各个组建必然部署在不同的节点上,因此必然出现子网络,同时网络本身又是不可靠的,一定存在延迟和数据丢失,即网络分区是必然存在的。所以P(分区容错性)是分布式系统必须要面对和解决的问题(你无法要求在永远不发生网络分区的环境下运行分布式系统)。
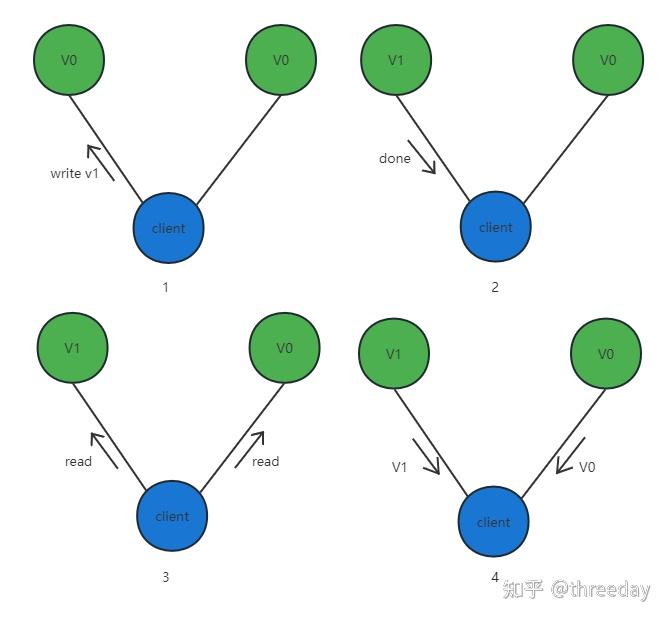
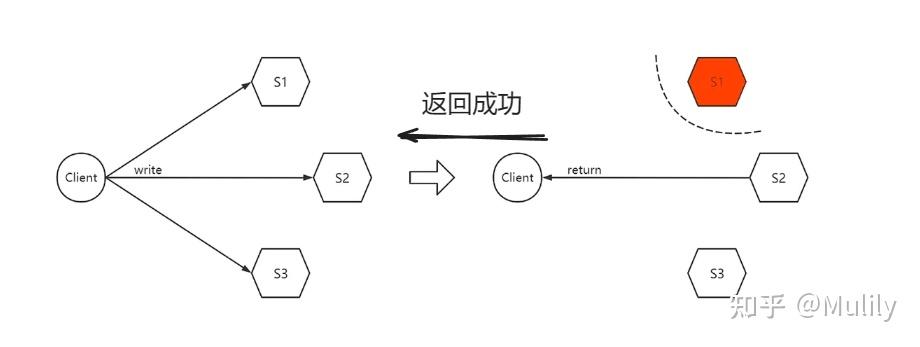
因此CAP三者不可兼得,变成如何在C(一致性)、A(可用性)二者进行抉择,可以举个例子来说明:在分布式环境中,为了确保系统可用性,通常会采用将数据复制到多个备份节点,而复制的过程需要通过网络交互。当发生网络分区时,你将面临两个选择:
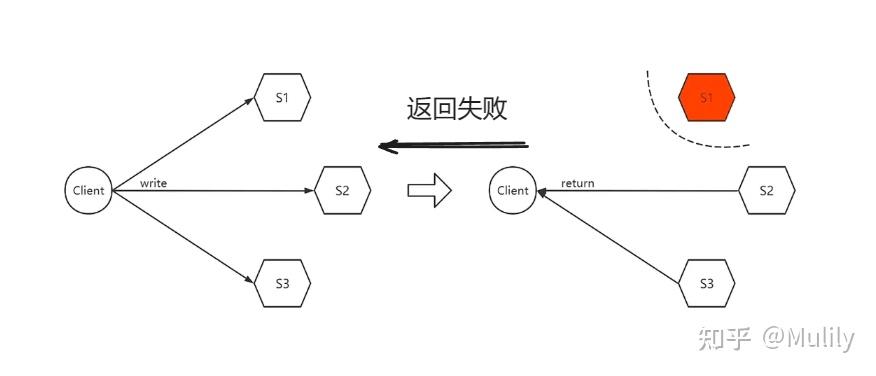
- 如果坚持保持各节点之间的数据一致性(选择C),你需要等待网络分区恢复后,将数据复制完成,才可以向外部提供服务。期间发生网络分区将不能对外提供服务,因为它保证不了数据一致性。
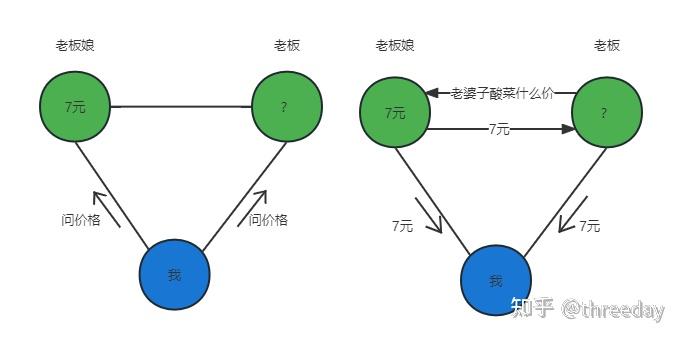
- 如果选择可用性(选择A),发生网络分区的节点,依然需要向外提供服务。但是由于网络分区,它同步不了最新的数据,所以它返回数据,可能不是最新的(与其他节点不一致的)数据。
这里需要强调一句,CAP三者不可兼得,仅仅是指在发生网络分区情况下,我们才需要在A和C之间进行抉择,选择保证数据一致还是服务可用。而集群正常运行时,A和C是都可以保证的。
- CP架构在当发生网络分区时,为了保证返回给客户端数据准确性,为了不破坏一致性,可能会因为无法响应最新数据,而拒绝响应。在网络分区恢复后,完成数据同步,才可处理客户端请求。
- AP架构在发生网络分区时,发生分区的节点不需要等待数据完成同步,便可处理客户端请求,将尽可能的给用户返回相对新的数据。在网络分区恢复后,完成数据同步。
实践中,怎么应用CAP?
CAP描述的一致性和可用性,都是100%的强度。在生产实践中,我们并不需要100%的一致性和可用性,因此我们需要对一致性和可用性之间进行权衡,选择CP架构或者AP架构。
例如,ZooKeeper,在少数成员宕机时,仍可以向客户端提供正确的服务,而当多数派成员宕机时,ZooKeeper则选择了一致性,为了保证给客户端响应正确的数据,ZooKeeper此时则不会继续提供服务。所以我们认为ZooKeeper在关键时刻选择一致性,但是它仍拥有很高的可用性。
2017 年,Google 公司的第一代 Spanner 系统已经诞生。Brewer 写了一篇文章讲述了 Google 公司的 Spanner 系统,并且近一步阐述了按照 CAP 定理 Spanner 是一个什么样特性的系统。在文中,Brewer 指出 Spanner 系统说是”实际上的 CA”(effectively CA)系统。从架构上来讲,Spanner 是一个 CP 系统,也就是说当出现网络分区时,Spanner 选择的是保证数据的一致性,放弃可用性的。但实际上,Spanner 是具有非常高可用性效果的一个系统,从架构上 Spanner 没有达到 CAP 定理要求的那种完全可用性,但是也达到非常高的可用性,由于采用多副本的设计,个别副本出现网络分区,并不影响用户能感知到的可用性。按 CAP 定理的定义,当这些个别副本出现网络分区时,这些节点是不可用的,也就是系统没有达到完全可用性。但是此时的用户请求是可以被其他副本服务的,此时服务是可用的,也就是说用户仍然感知到 Spanner 是可用的。所以说用户感知的可用性和 CAP 定理中的可用性不是一个概念。我们追求的应该是用户感知的可用性。
不考虑一致性的系统,有什么存在的意义呢?
这里以eureka为例,eureka各节点互相独立、平等的,各节点都提供查询和注册服务(读、写请求)。当发生网络分区,eureka各节点依旧可以接收和注册服务。并且当丢失过多客户端时,节点会进入自我保护(接收新服务注册、不删除过期服务)。在该种模式下,eureka集群剩下最后一个节点,也可以向外提供服务。尽管向外提供的数据可能是过期的数据。
考虑选择一致性还是可用性的情况,一定是在发生网络故障、且在关键时间,此时一致性和可用性才是互斥的。而网络故障、且非常关键时间,在一个健壮的系统中,这类情况是非常少的,我们大多数情况都能保证一致性和可用性。
eureka集群正常运行时,各节点之间可以正常通讯、保持心跳、复制数据,以此保持数据的一致性。但发生网络分区时,eureka确实选择了可用性,而放弃了一致性。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-11-4 20:20
发表于 2024-11-4 20:20



 发表于 2024-11-4 20:21
发表于 2024-11-4 20:21