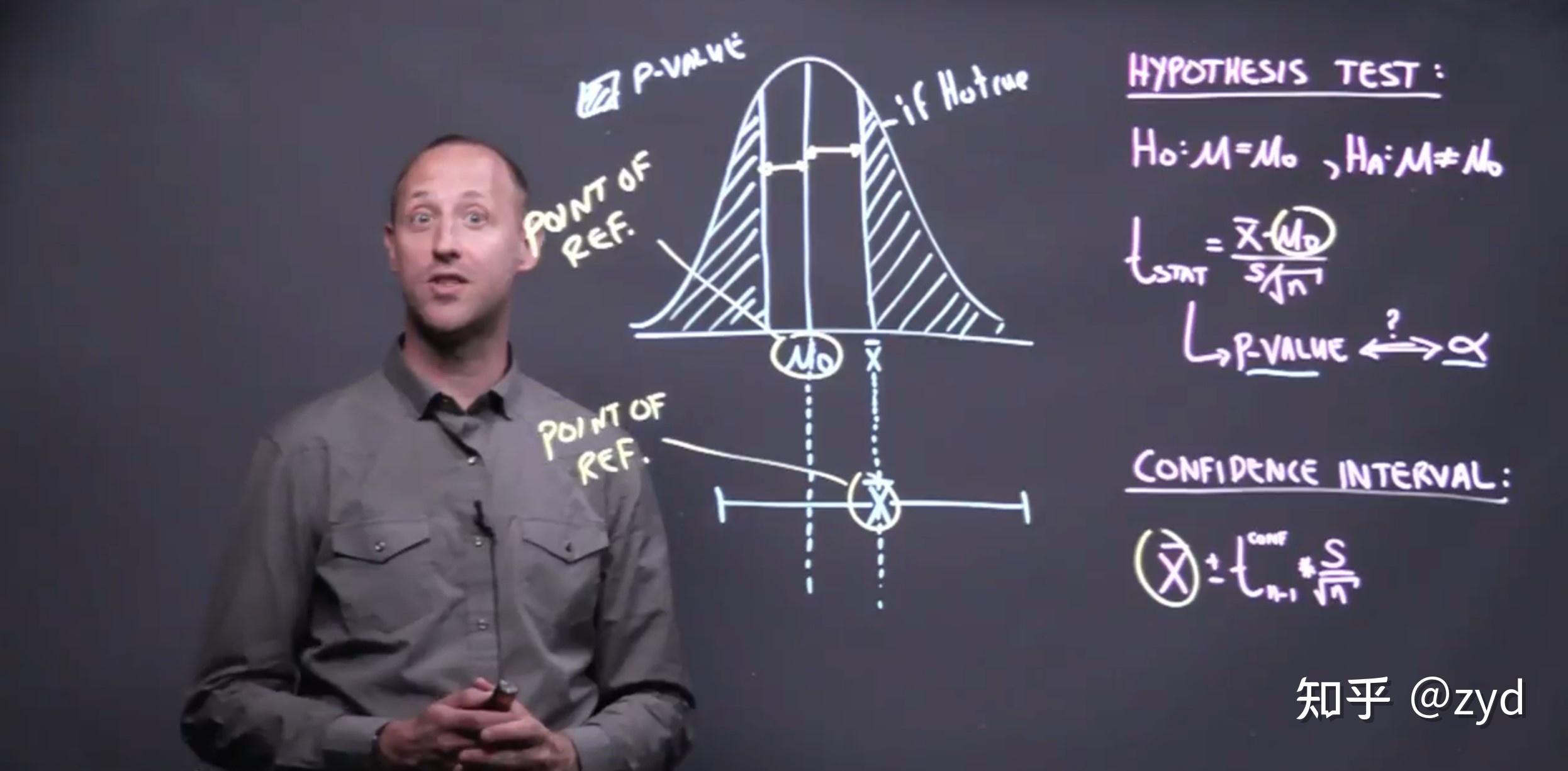
不想用太多符号以及概率来表达这两者关系,我想尝试一下用简便的方法来阐述一下这两者的关系,如果有错误欢迎指出。
首先假设检验中的不拒绝域和置信区间本质上是两个不一样的东西,但是它们之间有点异曲同工。前者的不拒绝域是以总体参数为主体来构建的,它可以理解为假设参数为真的条件下样本统计量落入这个不拒绝域的概率有(1-α),因此若你的样本统计量在α这么小的概率都落入了拒绝域,那么我就有充足的理由去说你这个原假设是假的,而这也正是假设检验的思想所在。至于置信区间它则是以样本统计量作为主体来构造的,它是以一个相对的思想来构造的,它的思想首先出发于估计量的无偏性,以正态分布为例由于估计量具有无偏性因此总体参数真值的正负3σ的区间内包含了99%的样本统计量,但是我们要估计的就是总体参数,因此总体参数是未知的,那我们就可以以相对的思想,既然你参数真值正负3σ的区间内包含了99%的样本统计量,则我也有99%的样本统计量±3σ区间也包含你参数真值,这就是置信区间。
总的来说,假设检验中的不拒绝域是以参数为主体来构造的,而区间估计中的置信区间则是以样本统计量为主体来构造的,它们构造的主体不同,但是构造的思想基本一致。
By the way其实个人觉得假设检验的原理完全可以用p值来定义

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2024-10-27 13:37
发表于 2024-10-27 13:37


 提升卡
提升卡