金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
最近看了一个时间序列的教程,感觉写的很清晰,搬过来在这里记录一下,英文原版链接如下:
【如需引用,请直接引用原始英文版】
【如需引用,请直接引用原始英文版】
<hr/>时间序列的定义
一个时间序列过程(time series process)定义为一个随机过程 \left\{ X_t | \ t \in T \right\} ,这是一个按时间排序的随机变量的集合,也就是将每一个时刻 t 位置的点作为一个随机变量。 T 是索引集合(index set), T 决定定义时序过程以及产生观测值的一个时间集合 。其中假定
- 随机变量 X_t 的取值是连续的。
- 时间索引集合 T 是离散且等距的。
在整个过程中,都采用以下符号
- 随机变量(Random variables)用大写字母表示,即 X_t ,同时随机变量的值是从一个分布中采样给出。而且可以为无限多个时间点 t \in T 定义随机变量。
- 观测(Observations)用小写字母表示,即 x_t ,观测可以认为是随机变量的实现。但通常在实际中,我们的观测点是有限的,因此定义 n 个观测是 \left\{ x_1,...,x_n \right\} 。
时间序列分析的目标
给定一组时间序列数据,通常会要求回答一个或多个有关它的问题。时间序列数据出现的主要问题类型取决于数据的上下文以及收集数据的原因,下面给出一些常见的目标:
- 描述:描述时间序列的主要特征,例如:序列是递增还是递减;是否有季节性模式(例如,夏季较高,冬季较低);第二个解释变量如何影响时间序列的值?
- 监控:检测时间序列行为何时发生变化,例如销售额突然下降,或者突然出现峰值。
- 预测:从当前值预测时间序列的未来值,并量化这些预测中的不确定性,比如根据今天的气温预测未来几天的温度。
- 回归:给定多个时间序列以及与这些序列对应的一个额外的值,找到其中的关系。
- 分类:给定多个时间序列,将它们按照相似性进行分类。
- ......
时间序列的建模
时间序列数据通常被分解为以下三个组成部分。
- 趋势(Trend)- 趋势体现的是时间序列数据均值随时间的长期变化。如果趋势存在,它的形状通常会引起人们的兴趣,尽管它可能不是线性的。
- 季节性影响(Seasonal effect)- 季节性影响是时间序列中以固定间隔重复的趋势。严格来说,季节性效应只是每年都会重复的效应,但在更一般的情况下,可以更广泛地使用该术语来表示任何定期重复的模式。
- 无法解释的变化(Unexplained variation)- 无法解释的变化是在任何趋势和季节性变化被去除后时间序列中其余的变化。这种无法解释的变化可能是独立的,也可能表现出短期相关性。
因此,时间序列数据的简单模型可以用两种方式表示,分别为
加法模型(Additive): X_t = m_t+s_t+e_t
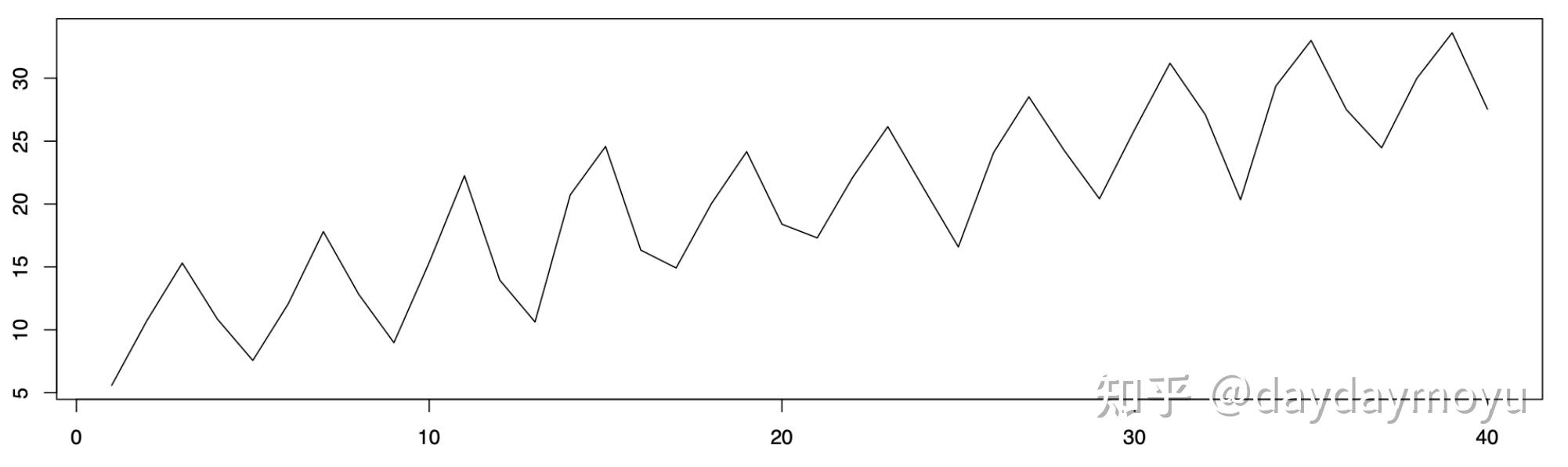
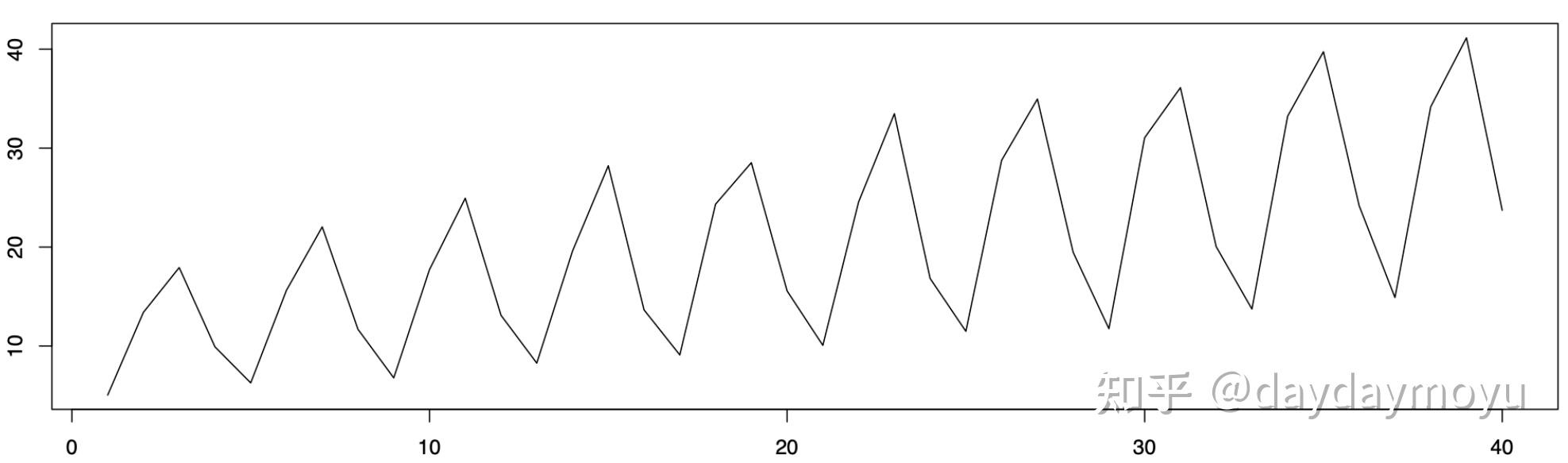
乘法模型(Multiplicative): X_t=m_ts_te_t 其中 m_t 表示趋势, s_t 表示季节, e_t 表示无法解释的变化。在此教程中,给出了两个例子。即当趋势和季节性变化独立作用时,加法模型是合适的,而如果季节性效应的大小取决于趋势的大小,则需要乘法模型。当趋势和季节性变化独立作用时,加法模型是合适的,而如果季节性效应的大小取决于趋势的大小,则需要乘法模型,简单的示意图如下:
- Example of additive model
- Example of multiplicative model
时间序列的特性(均值、方差、自协方差函数、自相关函数)
给定一个时间序列过程 \left\{ X_t | \ t \in T \right\} 和观测 x_1,...,x_n ,通常我们会使用以下属性描述其特征。
对所有的 t \in T ,时间序列过程的均值函数(mean function)定义为
\mu_t=\mathbb{E}[X_t] 对于真实的数据,通常我们假定均值为一个常数,因此可以估计均值为
\hat{\mu}=\frac{1}{n}\sum_{t=1}^{n}{x_t} 如果数据的平均值不是恒定的,例如由于趋势或季节性变化的存在,则应该用其他方法进行估计,这部分内容后面再讲。
对所有的 t \in T ,时间序列过程的方差函数(variance function)定义为
\sigma_t^2=\text{Var}[X_t]=\mathbb{E}[X_t^2]-\mathbb{E}[X_t]^2 标准差函数定义为 \sigma_t=\sqrt{\sigma_t^2} 。
对于真实的数据,通常我们假定方差也为一个常数,因此可以估计方差为
\hat{\sigma}^2=\frac{1}{n-1}\sum_{t=1}^{n}{(x_t-\hat{\mu})}^2
- 自协方差和自相关函数(Autocovariance and autocorrelation functions)
回忆对任意的随机变量 X 和 Y ,协方差以及相关性测量通过以下定义给出
协方差: \text{Cov}[X,Y]=\mathbb{E}[(X-\mathbb{E}[X])(Y-\mathbb{E}[Y])]=\mathbb{E}[XY]-\mathbb{E}[X]\mathbb{E}[Y]
相关性: \text{Corr}[X,Y]=\text{Cov}[X,Y]/\sqrt{\text{Var}[X]\text{Var}[Y]} 相关性是介于 -1 和 1 之间的协方差的缩放表现,其中 1 表示强正相关,0 表示独立性,-1 表示强负相关,但通常相关性指的是线性的相关性。
对于一个时间序列过程,定义随机变量 (X_t, X_s) 是在不同时间点的测量。它们之间的依赖关系由自协方差和自相关函数描述,添加“auto”前缀以表示两个随机变量测量具有相同的数量。
对于所有的 s,t \in T ,自协方差函数(autocovariance function (ACVF))定义为:
\gamma_{s,t}=\text{Cov}[X_s,X_t]=\mathbb{E}[X_sX_t]-\mathbb{E}[X_t]\mathbb{E}[X_s] 其中
\gamma_{t,t}=\text{Cov}[X_t,X_t]=\text{Var}[X_t]=\sigma_t^2 。 对于所有的 s,t \in T ,自相关函数(autocorrelation function (ACF))定义为:
\rho_{s,t}=\text{Corr}[X_s,X_t]=\frac{\text{Cov}[X_s,X_t]}{\sqrt{\text{Var}[X_s]\text{Var}[X_t]}}=\frac{\gamma_{s,t}}{\sigma_s\sigma_t} 其中
\rho_{t,t}=\text{Corr}[X_t,X_t]=1 。 以上定义都是理想的情况,也就是在时刻 s 和时刻 t 均有若干个采样数据,这样才能计算 \mathbb{E}[X_s] 或者 \mathbb{E}[X_t] ,而真实的场景下这一条件却很难实现,因为通常在某一个时间点,只能获得1个采样点的数据。
为了计算真实数据的自协方差和自相关函数,通常假设数据中的依赖结构不随时间变化。 也就是说我们假设
\gamma_{s,t}=\text{Cov}[X_s,X_t]=\text{Cov}[X_{s+r},X_{t+r}]=\gamma_{s+r,t+r} 也就是说在这个假设下,影响协方差的唯一因素是两个时间序列中随机变量的距离 \tau=\left| s-t \right| ,这个距离通常称为滞后(lag)。
因此,唯一需要计算的是自协方差集合:
\gamma_t=\text{Cov}[X_t,X_{t+\tau}] \ \ \ \tau=0,1,2,... 在这种情况下,自相关函数变为
\rho_t=\text{Corr}[X_t,X_{t+\tau}]=\frac{\text{Cov}[X_t,X_{t+\tau}]}{\sqrt{\text{Var}[X_t]\text{Var}[X_{t+r}]}}=\frac{\gamma_{\tau}}{\gamma_0} 以上计算方式的前提是假设数据中的依赖结构不随时间变化,协方差不依赖于具体的位置 t ,只依赖于滞后 \tau 。
Estimating the autocorrelation function
对于时间序列数据,自协方差和自相关函数测量的是单个时间序列 x_1,...,x_n 与其滞后lag之间的协方差/相关性。这里给出 \text{lag}=0 ,\text{lag}=1以及 \text{lag}=\tau 时自协方差及自相关函数的计算过程。
【lag=0】
在滞后 0 (lag=0)处样本的自协方差函数定义为 \hat{\gamma}_0,它是 (x_1,...,x_n) 与 (x_1,...,x_n) 之间的协方差。根据上面的公式,计算方式为
\hat{\gamma}_0=\frac{1}{n-1}\sum_{t=1}^{n}{(x_t-\bar{x})(x_t-\bar{x})}=\frac{1}{n-1}\sum_{t=1}^{n}{(x_t-\bar{x})}^2=\hat{\sigma}^2 因此,滞后 0 处的样本自协方差函数是样本方差。类似地,滞后0处的自相关性为
\hat{\rho}_0=\frac{\sum_{t-1}^{n}(x_t-\bar{x})(x_t-\bar{x})}{\sqrt{\sum_{t-1}^{n}{(x_t-\bar{x})^2\sum_{t=1}^{n}{(x_t-\bar{x})^2}}}}=1 【lag=1】
在滞后 1(lag=1)处的样本自协方差函数是时间序列 \left( x_1,...,x_{n-1} \right) 和 \left( x_2,...,x_n \right) 协方差。它是序列与自身移动一个时间点序列的协方差,根据以上公式,协方差和自相关系数计算方式为
\hat{\gamma}_1=\frac{1}{n-2}\sum_{t=1}^{n-1}{(x_t-\bar{x}_1)(x_{t+1}-\bar{x}_2)} 及
\hat{\rho}_1=\frac{\sum_{t=1}^{n-1}{(x_t-\bar{x}_1)(x_{t+1}-\bar{x}_2)}}{\sqrt{\sum_{t=1}^{n-1}{(x_t-\bar{x}_1)^2\sum_{t=1}^{n-1}{(x_{t+1}-\bar{x}_2)}}}} 其中
\bar{x}_1=\sum_{t-1}^{n-1}{x_t/\left( n-1 \right)} 是前 n-1 个观测值;
\bar{x}_2=\sum_{t-2}^{n}{x_t/\left( n-1 \right)} 是后 n-1 个观测值; 在实际应用中,通常假设前 n-1 个观测值的均值和方差等于最后 n-1 个观测值的均值和方差,这样可以简化上述表达式。此外,对于协方差公式,使用除数 n 而不是无偏 n-2。显然,当 n 很大时,改变除数对计算几乎没有实际影响。
【lag= \tau 】
时间序列的样本自协方差函数 (ACVF)定义为:
\hat{\gamma}_{\tau}=\frac{1}{n}\sum_{t=1}^{n-\tau}{(x_t-\bar{x})(x_{t+\tau}-\bar{x})} \ \ \ \ \tau=0,1,... 样本自相关函数 (ACF) 定义为
\hat{\rho}_{\tau}=\frac{\sum_{t=1}^{n-\tau}{(x_t-\bar{x})(x_{t+\tau}-\bar{x})}}{\sum_{t=1}^{n}{(x_t-\bar{x})^2}}=\frac{\hat{\gamma}_{\tau}}{\hat{\gamma}_0} \ \ \ \ \tau=0,1,... 以下链接中找到有助于理解自协方差和自相关函数的交互式示例。
Correlogram图的解释
Correlogram讲自相关函数的计算结果作为纵轴,将滞后 \tau 作为横轴的一种图。可以很直观的看出时间序列不同lag之间的相关性。Correlogram会告诉时间序列分析师很多关于时间序列的信息,包括趋势的存在、季节性变化和短期相关性。这里用一些例子来说明。
【Example - purely random data】
考虑由纯随机过程 X_t\sim N(0,1) 生成的时间序列,它没有趋势、季节性或短期相关性。原始数据和自相关图如下所示:
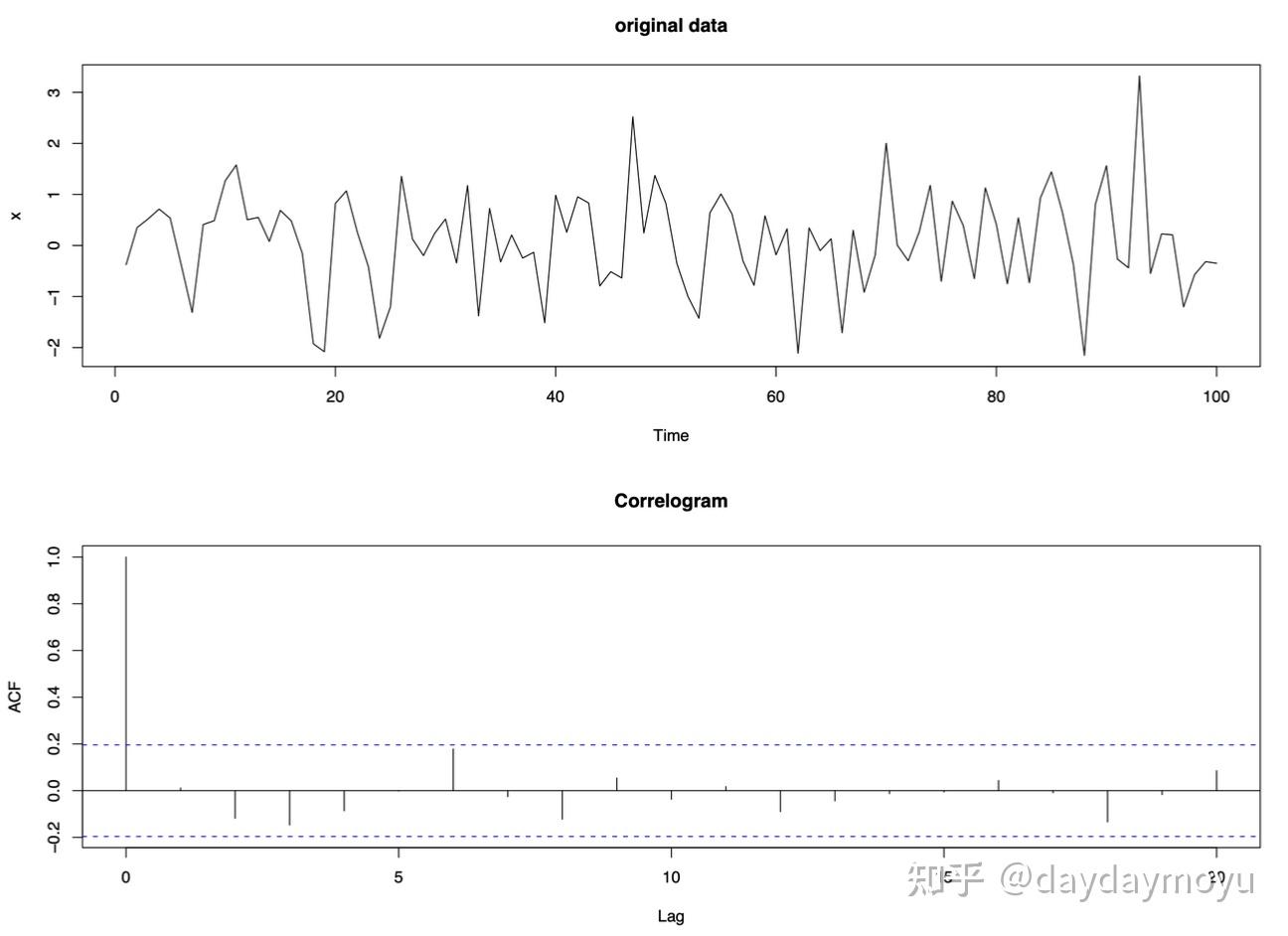
Time series simulated from a purely random process and its corresponding correlogram
- 当 \text{lag}=0 时, \text{ACF}=1 ,因为它是序列与其自身的相关性,通常忽略该值。
- 对于没有相关性的纯随机序列,通常在滞后 0 处等于 1,但在其他滞后处没有明显的相关性证据。
【Example - short-term correlation】
没有趋势或季节性但具有短期相关性的时间序列数据如下图所示,并且在前几个滞后时具有显着正的自相关,随后在较大滞后时值接近零。
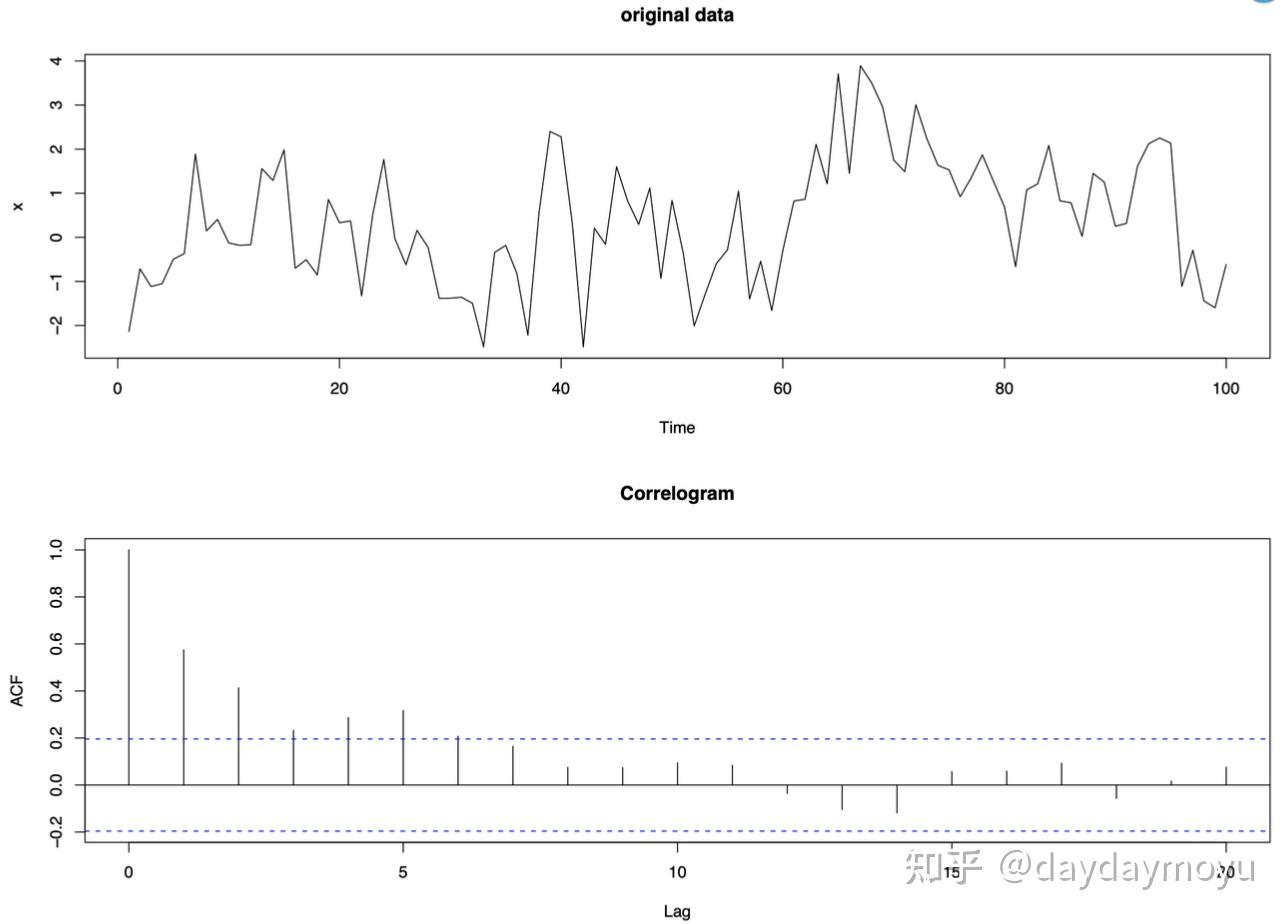
Time series with short-term correlation and its corresponding correlogram
【Example - alternating data】
没有趋势或季节性但在大值和小值之间交替的时间序列数据显示下图中,并且在奇数滞后时具有负自相关,在偶数滞后时具有正自相关。 随着滞后的增加,自相关越来越接近于零。
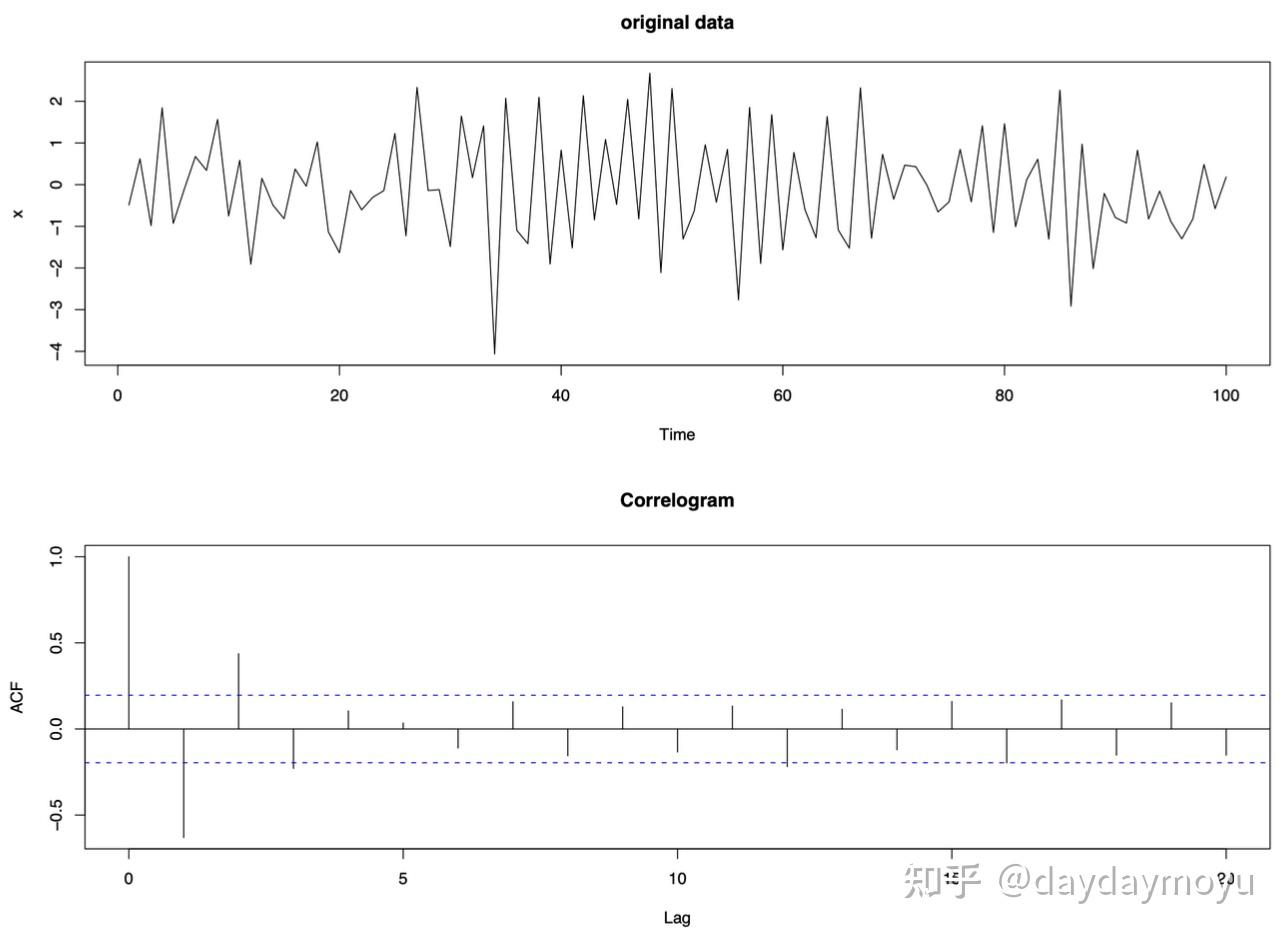
Time series which alternates between large and small values and its corresponding correlogram.
【Example - data with a trend】
具有趋势的时间序列数据如下图所示,并且在滞后偏大时仍然具有正自相关。 如果趋势随时间下降,则会观察到相同的相关图。
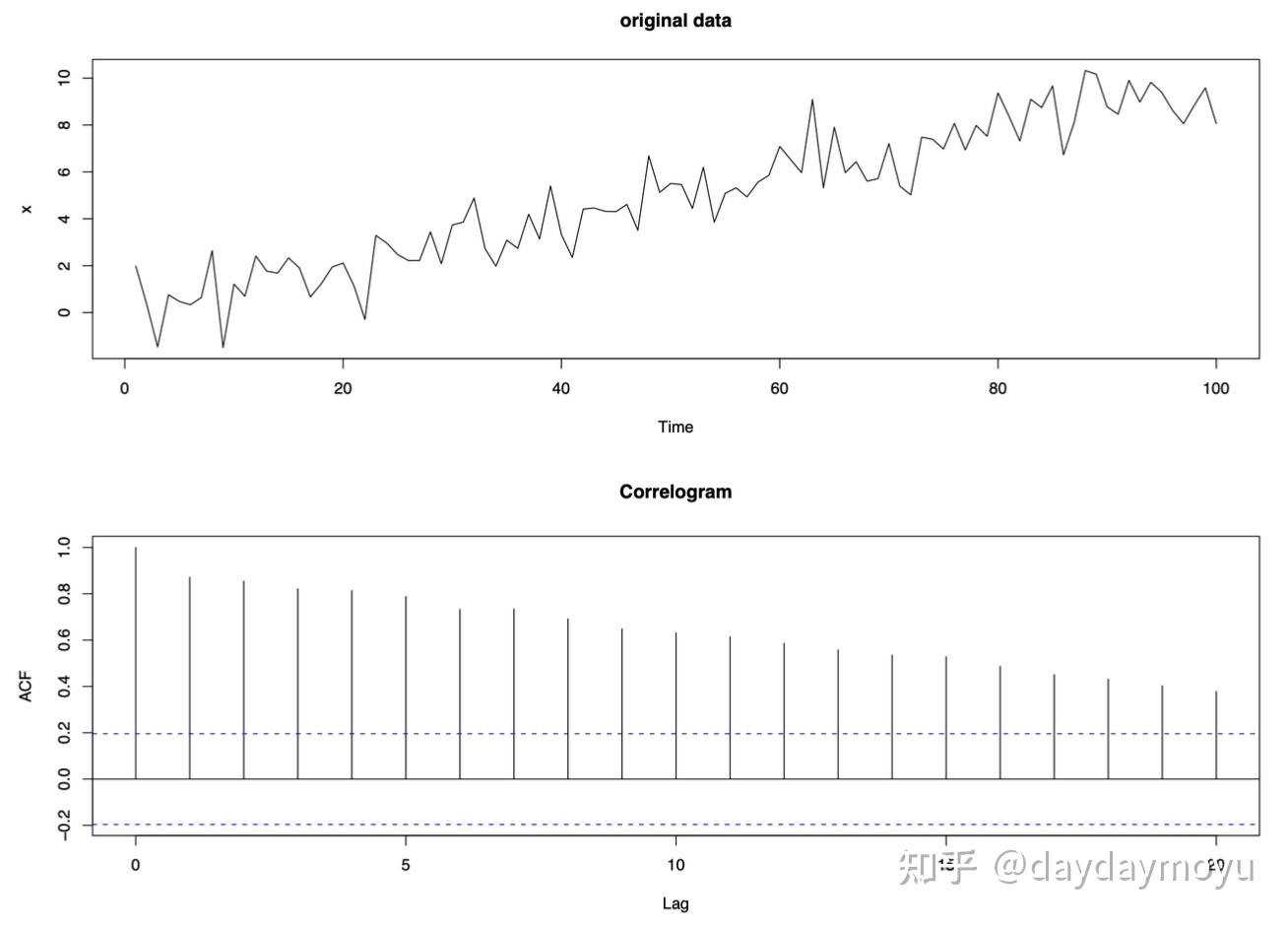
Time series data with a trend and its corresponding correlogram
【Example - data with a seasonal effect】
具有季节性影响的时间序列数据如下图所示,并且在相关图中具有规则的季节性模式。
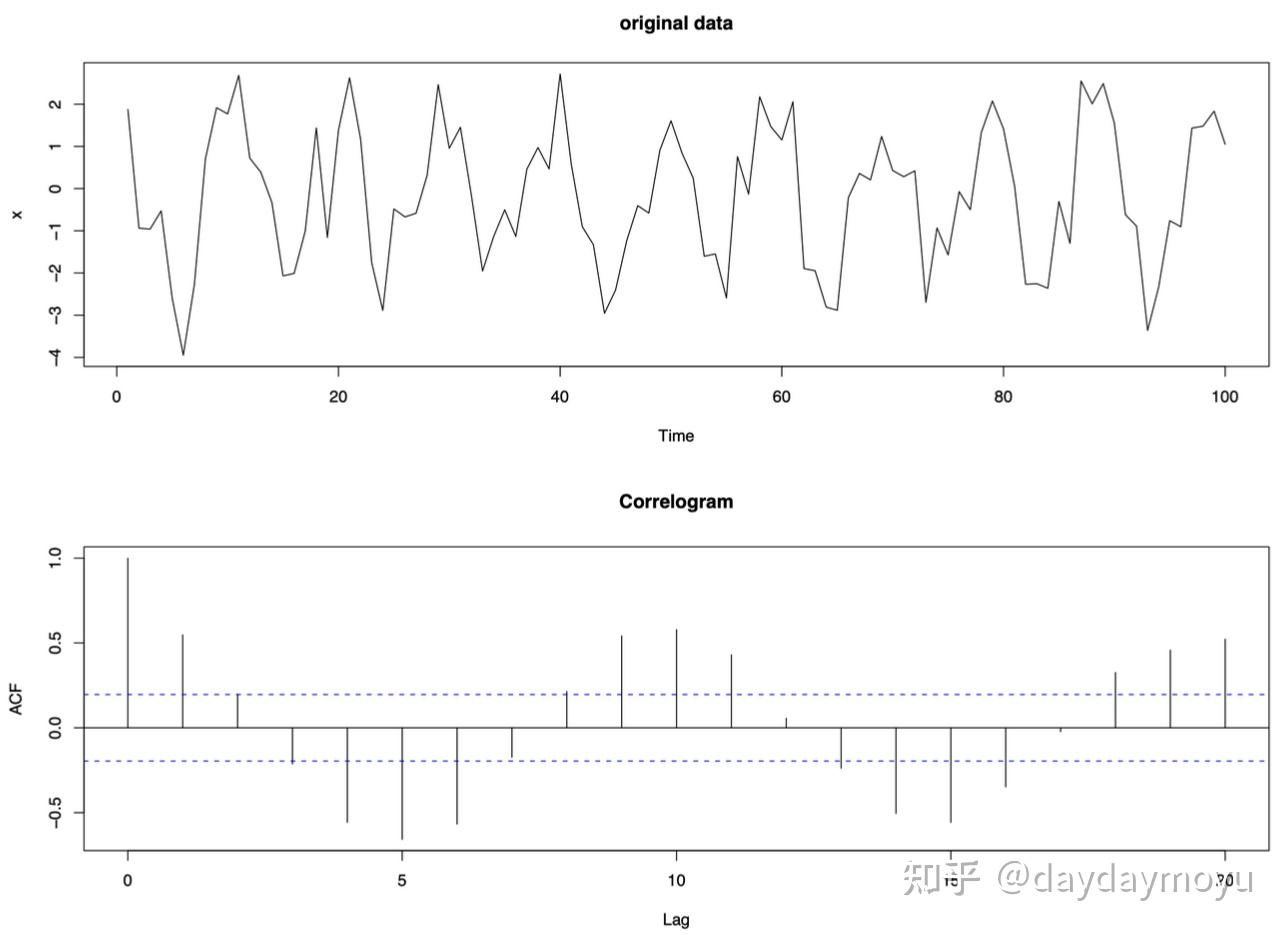
Time series data with a seasonal effect and its corresponding correlogram.
【Example - data with a trend and a seasonal effect】
具有趋势和季节性影响的时间序列数据显示在下图中,并且在相关图中具有规则的季节性模式,由于趋势的存在,相关图通常具有正值。
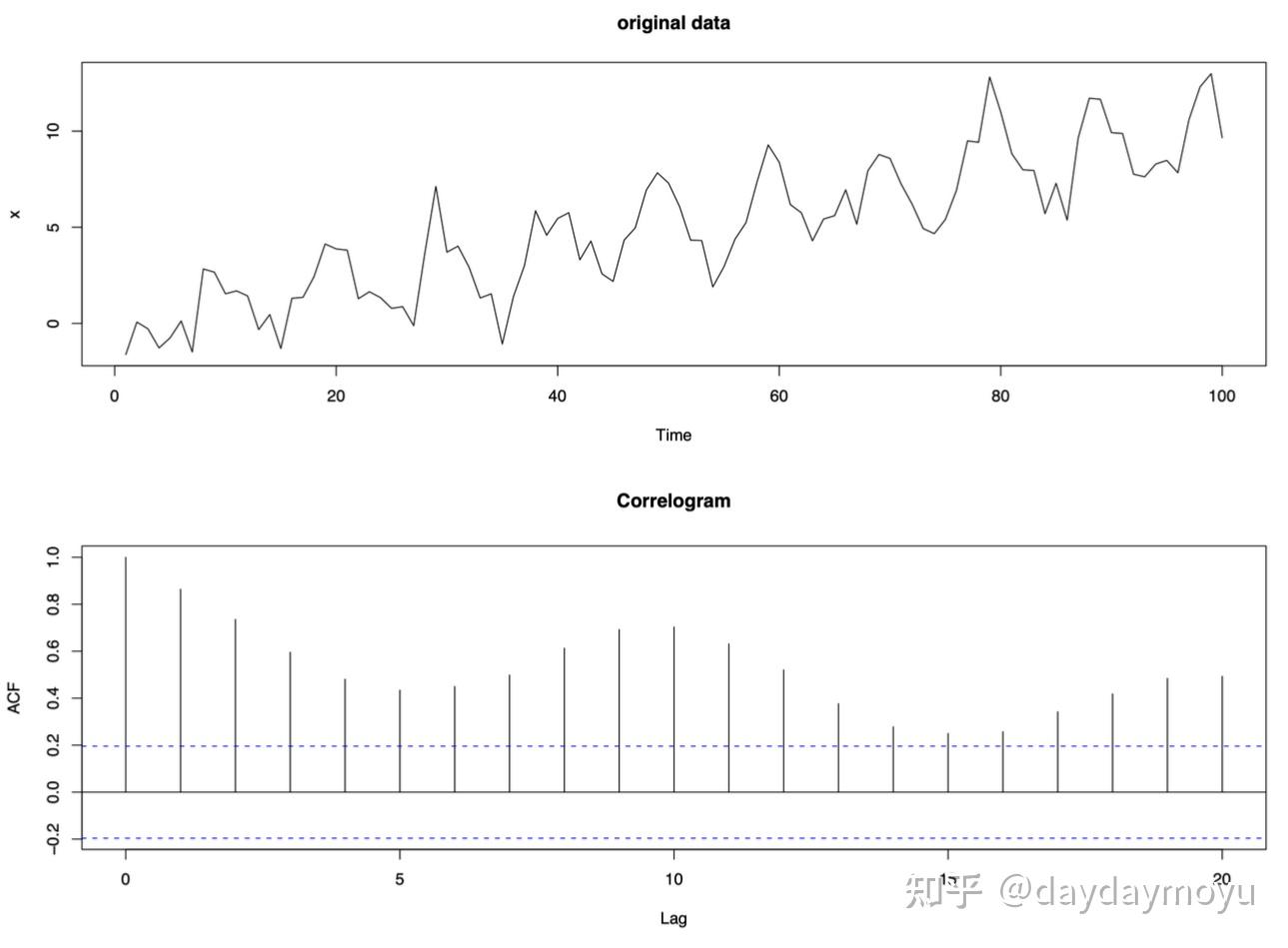
Time series data with a trend and seasonal effect and its corresponding correlogram
平稳性分析
- 严格平稳(strictly stationary or strongly stationary)
严格平稳是一种非常苛刻的条件,给定时序过程 \left\{ {X_t \ |\ t \in T} \right\} ,对于所有的 t_1,...,t_k 以及值 r ,如果联合分布 f(X_{t_{1}},...,X_{t_k}) 与f(X_{t_{1}+r},...,X_{t_k+r})相同,则该序列是严格平稳的。换句话说,换句话说,将序列的时间原点移动 r 对其联合分布没有影响。
当 k=1 ,严格平稳意味着对于所有的 r ,都有 f(X_t)=f(X_{t+r}) 。这也说明时间序列的均值和方差为常数,即 \mu_t=\mathbb{E}[X_t]=\mu 和 \sigma_t^2=\text{Var}[X_t]=\sigma^2 。
当 k=2 ,严格平稳意味着对于所有的 r ,都有f(X_{t_1},X_{t_2})=f(X_{t_1+r},X_{t_2+r})。联合分布只取决于滞后 \tau=\left| t_2 -t_1 \right| 。这反过来意味着理论协方差和相关函数只取决于滞后而不是原始位置。
严格平稳是非常严格的,而真实过程很少符合。一般只有纯粹的随机过程严格平稳,因此使用的更多的是弱平稳。
给定时序过程 \left\{ {X_t \ |\ t \in T} \right\} ,如果该时间序列过程是弱平稳的的,那么它需要满足以下条件:
- 均值是常数和有限的,即 \mu_t=\mathbb{E}[X_t]=\mu < \infty
- 方差是常数和有限的,即 \sigma_t^2=\text{Var}[X_t]=\sigma^2 < \infty
- 自协方差和自相关函数仅取决于滞后 \tau ,即 \gamma_{t,t+\tau}=\text{Cov}[X_t,X_{t+\tau}]=\gamma_\tau 以及 \rho_{t,t+\tau}=\text{Corr}[X_t,X_{t+\tau}]=\rho_\tau
严格平稳性和弱平稳性之间的区别在于,后者仅假设前两个矩(均值和方差)随时间是恒定的,而前者假设较高的矩也是恒定的。
【Example】
定义一个随机游走过程 \left\{ {X_t \ |\ t \in T} \right\} , X_0=0 ,且
X_t=X_{t-1}+Z_t
其中 Z_t 是均为为 0 且方差为 \sigma^2 的随机过程。那么 X_t 是非平稳的。因为
\text{Var}[X_t]=\text{Var}[X_{t-1}+Z_t] =\text{Var}[X_{t-1}]+\sigma^2=t\cdot\sigma^2
这说明方差是随时间 t 变化的。
<hr/>以上就是时间序列的一些基本概念和介绍,推荐大家去看原文,再次给出链接
END
原文地址:https://zhuanlan.zhihu.com/p/424609116 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2024-10-26 07:40
发表于 2024-10-26 07:40
 提升卡
提升卡


