用户名
UID
Email
密码
记住
立即注册
找回密码
只需一步,快速开始
微信扫一扫,快速登录
开启辅助访问
收藏本站
快捷导航
门户
Portal
社区
BBS
资讯
会议
市场
产品
问答
数据
专题
帮助
签到
每日签到
企业联盟
人才基地
独立实验室
产业园区
投资机构
检验科
招标动态
供给发布
同行交流
悬赏任务
共享资源
VIP资源
百科词条
互动话题
导读
动态
广播
淘贴
法规政策
市场营销
创业投资
会议信息
企业新闻
新品介绍
体系交流
注册交流
临床交流
同行交流
技术杂谈
检验杂谈
今日桔说
共享资源
VIP专区
企业联盟
投资机构
产业园区
业务合作
投稿通道
升级会员
联系我们
搜索
搜索
本版
文章
帖子
用户
小桔灯网
»
社区
›
A、行业资讯区
›
同行交流
›
深度学习(炼丹)音乐人声分离入门相关小结 ...
图文播报
2026庆【网站十三周
2025庆【网站十二周
2024庆中秋、迎国庆
2024庆【网站十一周
2023庆【网站十周年
2022庆【网站九周年
返回列表
查看:
13642
|
回复:
0
[讨论]
深度学习(炼丹)音乐人声分离入门相关小结
[复制链接]
临床医师
临床医师
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
雷达卡
发表于 2024-10-10 16:58
|
显示全部楼层
|
阅读模式
登陆有奖并可浏览互动!
您需要
登录
才可以下载或查看,没有账号?
立即注册
×
一、背景
最近在研究音乐人声分离任务,但是实验室的显卡给我的只有一张4080,16G显存,我作为小白看大佬们(大公司们)的论文,动不动就弄好几张Nvidia V100 GPU去跑人声分离,动不动就好几十兆的网络模型,看得我目瞪口呆,真是难为我的显卡了,想训练都训不动,这不经过量化,我的显卡就真推不动了,于是根据我自己的经验仿写了一些小模型,跟大家聊聊人声分离这任务,其实我也一头雾水,这任务哪怕提升1db,参数量计算量简直是指数级增长,这要是部署到嵌入式设备上,想想都可怕,本文也希望能有大佬指点一二,不只是为了发paper,做工程项目,也是为了知乎众多研究牲,以至于头发也掉了好多。。。
二、数据集相关
多数数据集都是包含贝斯、鼓、其他乐器和人声,不过经过我从中大量听取,发现其他乐器多为管弦乐器,像吉他提琴钢琴什么的,还有一些我也说不上,感觉这个可以再做一个乐器分离的模型。
1.MUSDB18/MUSDB18-HQ
多数论文都使用这个数据集,包含两个文件夹,一个包含训练集的文件夹:“train”,由 100 首歌曲组成,另一个文件夹包含测试集:“test”,由 50 首歌曲组成。一部分训练集来自DSD100和MedlyDB,质量还挺高的,分有贝斯、鼓、其他乐器和人声。MUSDB18是16khz的MP3,MUSDB18-HQ是44.1khz的wav,不过我还是建议大家下载MUSDB18-HQ,根据需要用FFMEG采样获得不同精度和采样的音频数据。之前问了个AI,说有个MUSDB20是18的更新,不过我没找到。
2.DSD100
一共一百首歌,44.1khz,50首为训练集,50首测试集,包含贝斯、鼓、其他乐器和人声,训练时数据集不够可以和MUSDB18-HQ混合训练,只不过人声都是英文,大家可以下载一些中文数据集,训练时讲中文混进去,这样得到的模型也是可以将中文分离的。
3.MedlyDB
疑似需要科学上网,反正我被屏蔽掉了,122首歌,数据集也是费了好大劲才弄到。版本也分为1.0和2.0
4.ccMixter
只有乐器和人声,音乐都混在一起了,如果你只做音乐+人声分离,对乐器不感兴趣,那么可以将ccMixter和上面的数据集混用。采样44.1khz,50首歌。
5.MoisesDB
240首歌,44.1khz,这个数据集比较厉害,不仅包含贝斯、鼓、人声,而且还包含弓弦乐器、吉他、其他击键类乐器、其他弹拨乐器、打击乐器、钢琴、管乐器等,只不过每一首歌包含的乐器不一样,但一定包含贝斯、鼓、吉他和人声,如果你做乐器分离,可以至少做4个stem,如果将mixture减去这4个stem得到其他乐器,那就是5个stem,如果再挑出一些piano,那就可以做6个,HT-Demucs我就见它做了6个。这个数据集比较raw,比方说它就是把drums也细分了好几个小类drums,只不过我都不认识这些乐器到底是啥,wav的basename都是一堆哈希字符串,所以这个数据集神就神在你对它做的处理比较自由,可以将每首歌的每一类乐器全部相加,然后给这些乐器分大类,训练的时候只需要随机混合乐器和人声就可以了,这样,你想做多少个stem就做多少个。MoisesDB是我觉得除了MUSDB18-HQ外最好的数据集了。数据量有点大,80+个G,解压后高达149个G,是本文使用的数据集中最大的。
6.其他
MIR-1K这个也顺便提一下吧,110首歌,解压后大小1.12G,我试听了一下,有点难听,就没用这个数据集了
2. Slakh2100,下载需要104.3G空间,太大了,我就没下载,有2100首歌,145小时,足够大家训练鲁棒性更强的模型了
3. Opencpop,网易出品的歌声合成数据集,没有音乐,全是邓紫棋的清唱,可以作为中文语料加入到音乐人声分离任务当中,更好适配国人的歌曲分离模型。
4. Common Voice,降噪常用的数据集,可以充当多语言语料用于人声分离当中
5. 其他人评论区补充
三、音源分离网站/开源软件
网站:
vocalremover这个我试了很多歌,感觉是音源分离网站中做得比较好的一个,我也经常下了很多歌来让它生成音乐和人声,然后充当我的数据集,权当教师模型来看。不仅能够分离音乐和人声,而且还能将bass、drums、other分离出来,还有变调的功能。但是这网站不免费,一天只能免费处理一首歌,要想处理更多歌曲,要开会员。
2. vocali,最大20M,10分钟音频,但最重要的是可以无限上传歌曲,但是效果只比vocalremover略差一点
3. Notta,上传数量有限,分离效果还可以,最多1个文件20分钟,处理速度很慢
4. Tunebat,无限上传,免费分离人声,分离乐器要会员,导出速度还算可以,但是导出格式为MP3,音质略差
5. 其他国内的音乐人声分离网站,要注册登录啥的,导出要么限制时长要么充值会员什么的,我嫌麻烦没弄太多。就让读者在评论区补充吧
开源软件:
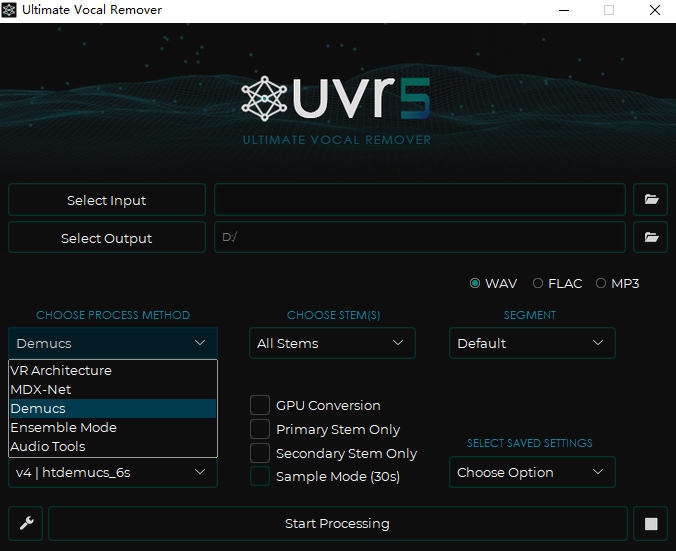
只有一个UVR5,不需要会员,基于神经网络的音乐人声分离软件,非常强大,支持多种算法和CUDA加速。如果读者不是搞深度学习却想免费弄一个音乐人声分离软件玩玩的,建议下载UVR5,只有下载模型权重的时候才需要联网,一切分离操作均在本地运行,非常良心。网络模型用的是MDX和Demucs等,MDX可以分离2个stem,Demucs可以分离4或6个stem,非常强大的sota。具体操作可以看CSDN一些博客有介绍如何使用UVR5。spleeter感觉太老了,现在都是Demucs之流霸榜benchmark
其他:spleeter
MVSEP-MDX
如果有其他开源软件,不妨在评论区补充
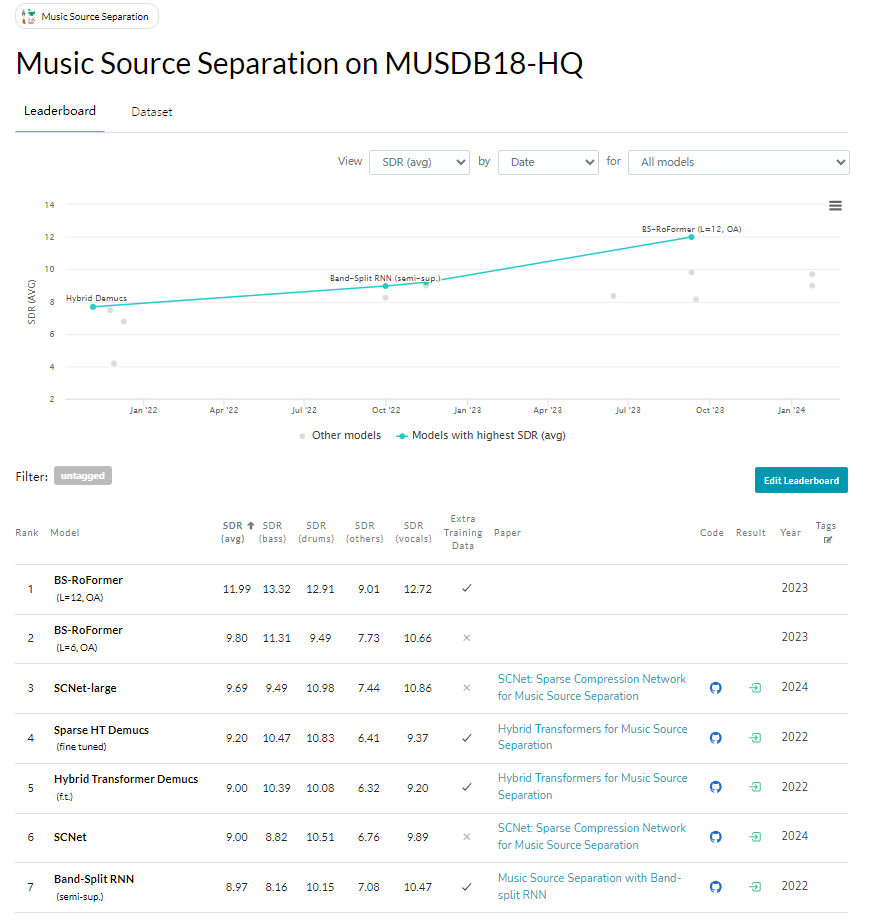
四、Benchmark/模型Ranking
数据来源papers with code, 来自MUSDB18(-HQ)的benchmark,含有各个模型的性能排名,意思是仅用MUSDB18(-HQ)就能达到什么效果,分离程度到达多少db(musdb18-hq的含金量还在上升)。如果差一点超过其他模型,那么就可以使用额外的数据(Extra training data)来实现更高的db。
这里说一下MUSDB18-HQ的排名
引流rank1:BS-RoFormer
paper:
code:
Demucs系列的我就不讲了,反正网上很多解读的。另外看了一下SCNet和BSRNN的源码,好像有异曲同工之妙,BSRNN是将44.1khz的频带分割为大小不等的数个频带,然后再将不等长的频带映射到同样等长的频带,并且在Channel维度进行拼接,然后就是经过一系列LSTM,再之后split channel反映射回去解码。而SCNet则是将44.1khz的频带按照[0.175, 0.392, 0.433]的比例分割为low、mid、high三个频带,然后用不同卷积核和步长进行压缩,并且在Frequency维度进行拼接,然后还是一系列LSTM,之后根据先前的三个频带的长度split反卷积解码。(不过我个人感觉BSRNN的计算有很多冗余,计算过于稀疏,但我没证据)
很显然,音源分离任务的核心就是分频带,因为低频信息密集、高频信息稀疏,如果不将Frequency split的话,全局的Convolution参数抑或是Linear参数将会被低中高频信息平均拉扯,以至于kernel的参数难以到达最佳。换句话说,每个频带都应该“因材施教”,否则只增大模型的参数和计算量,只会是一种暴力解法。
那么inspired by dual-path RNN, 我想,未来的工作,应该是将频带F分割,并在channel维度上拼接,LSTM完后再换为Frequency维度上拼接,再LSTM。这种RNN我将其称之为:band-split-dual-path RNN。无论是并行还是串行,都能尽可能地利用每个bin的信息,即local又global。不过我感觉已经有人在做了,可以发一篇论文,可惜我的显存太小,跑不下这个模型。
五、我的训练心得
1.loss不要设置得太复杂,简单复合个SNR和谱距离即可;
2.shortcut少设置concatenate,密集计算这玩意很占显存,多用add和multiply,不怎么占显存的同时还能减少参数量计算量;
3.数据集,musdb18-hq+Moisesdb即可,乐器混合比值一般在-3~3db即可,音乐和人声比值-5~5db即可,另外可以用那些网站或者UVR5分离自己下载的歌,当作自己的数据集,成为教师模型的一部分,但是要确保分离出来音乐和人声足够干净,不然会引入其他噪声,分离中文歌就需要找一些中文数据,哪怕不是哼唱,你拿降噪常用的语音数据集也是可以的;
4.频带分频压缩是必然,建议大家思考如何分频压缩,SCNet和BSRNN的思路就很好,参考它俩的源码能获取一些灵感;
5.如果要使用transformer,注意力的使用对性能提升是显而易见的,只要你用了就比纯CNN+RNN的好,分频其实就是主动注意的一种,transformer(含改进)就是被动注意。
6.直接映射波形的话模型需要的参数量特别大,论文常用的还是复数谱映射,而且我试了很多方法,波形>复数谱>>幅度谱>梅尔滤波器组+幅度谱,感觉搞音源分离的,用幅度谱的效果都比较差,感觉是采样率高了,相位谱变得越来越重要了,乐器的位置影响了相位,所以为了普遍性效果,大家使用复数谱是最好的了;
7.双向RNN的时候,最好还是不要在时间维度搞双向,虽然纸面数据是很好看,但是增加的延迟还是很大的;卷积也是,3*3的卷积一般都需要索求一帧未来帧,很多个3*3卷积累计起来延迟甚至能达到几秒,现在网上很多都能做到离线音源分离的落地,这部分市场都瓜分地差不多了,就剩下实时音源分离的潜景比较好,能做到的就赚了;
8.帧长帧移的比值一般是4,如帧长4096帧移1024,比值为2的话比较少见,比值为6也见过,比值太小性能差,比值太大资源需求高,所以在4附近的值就是比较好了;
9.(个人感受)对于推动44.1khz的大模型训练,学习率不可变化得太快,如训练几个甚至十几个epoch就下降,那你的模型就废了,而且这训练这玩意还是很讲究耐心的,要是你模型结构设计得不好,初始训练几百个epoch,loss也没达到你预期那可以重新训练了。如果你确信模型结构非常高效,那就让学习率缓慢下降,它总能给你惊喜。当时我就用了一个CRN结构共4个LSTM,大约1M的参数,20G的mac,做音乐人声分离,分离出来的效果也非常可观,至少能将人声灭掉90%,部分歌曲能灭到99%,剩余的人声还是需要仔细听才能听到,但有些歌的表现也不好,裸耳也能听到少量人声,特别是中高频人声。
10.点赞的人都(将会)发顶会顶刊了。
原文地址:https://zhuanlan.zhihu.com/p/702027501
回复
使用道具
举报
提升卡
返回列表
发表回复
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
浏览过的版块
文献资源
关闭
官方推荐
/3
AI助手<小桔子>来了!
欢迎来交流,可以回答IVD行业各类问题!
查看 »
IVD业界薪资调查(月薪/税前)
长期活动,投票后可见结果!看看咱们这个行业个人的前景如何。请热爱行业的桔友们积极参与!
查看 »
小桔灯网视频号开通了!
扫描二维码,关注视频号!
查看 »
返回顶部
快速回复
返回列表
客服中心
搜索
洽谈合作
关注微信
微信扫一扫关注本站公众号
个人中心
个人中心
登录或注册
业务合作
-
投稿通道
-
友链申请
-
手机版
-
联系我们
-
免责声明
-
返回首页
Copyright © 2008-2024
小桔灯网
(https://www.iivd.net) 版权所有 All Rights Reserved.
免责声明: 本网不承担任何由内容提供商提供的信息所引起的争议和法律责任。
Powered by
Discuz!
X3.5 技术支持:
宇翼科技
浙ICP备18026348号-2
浙公网安备33010802005999号
快速回复
返回顶部
返回列表

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2024-10-10 16:58
发表于 2024-10-10 16:58


 提升卡
提升卡


