金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
- 操作系统方面,一定要懂基本的 Linux 操作命令,但要求不算高,能够在终端(Terminal)下操作数据,会用 awk/sed/grep 等基本命令,我估计这个应该就是计算机二级水平。总之就是能够在linux下,编写基本的bash script。
- 编程语言方面Python、C/C++、Java等至少要精通一样,绝对不能仅仅只会R。而如果你掌握了Python,那么R可学也可不学,但要会看懂。我自己早期是Perl和C++,Perl语言其实也比较容易学(不过前提是你之前学过编程语言),期间我自己为项目写了多个Perl包,但后来Perl换成了Python,原因是我比较喜欢Python,另一个原因是感觉Perl老了,社区都跟不上了。
- 如果学了Python的话,一定要掌握到面向对象,包括能够写Class,能够自己写Python包,最好是能够写C拓展;
- 如果学的是C,那么数据结构、结构体、指针、动态内存分配,文本操作要全掌握,能够写1000行以上的有意义代码,处理生物信息问题;
- 如果是C++,除了上面C里面提到的内容之外,最好要掌握面向对象编程,STL标准库常用数据类型(如:vector、map等),能够写class。
如果编程方面仅仅只会Python,那么最好要掌握如何用Cython写C拓展,但其实Cython的语法模式和编写思想源自C/C++,还是没有直接用C/C++干脆,但好处就是能够和Python共同编写,可以直接调用Python包,效率写起来比单纯用C/C++高,代价就是达不到C/C++的速度(不必相信网上给出的测试说Cython其实效率可以比C高的说法,那些测评都太过简单,真正做起项目来是达不到的),并且代码风格不太好。
我的观点:如果懂用C/C++,那么写核心程序,比如设计生信算法方面就不要用Cython了,可以自己全面写成C/C++之后,编译,再用Python去调用。日常普通的数据处理、小规模的数据分析、写分析流程、统计分析、机器学习和数据可视化(画图),用Python是足够的。
以上。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-9-25 17:54
发表于 2024-9-25 17:54



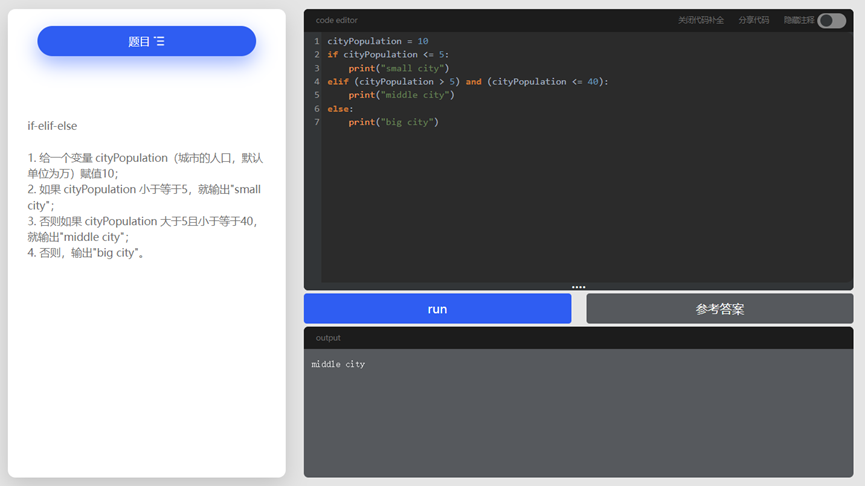

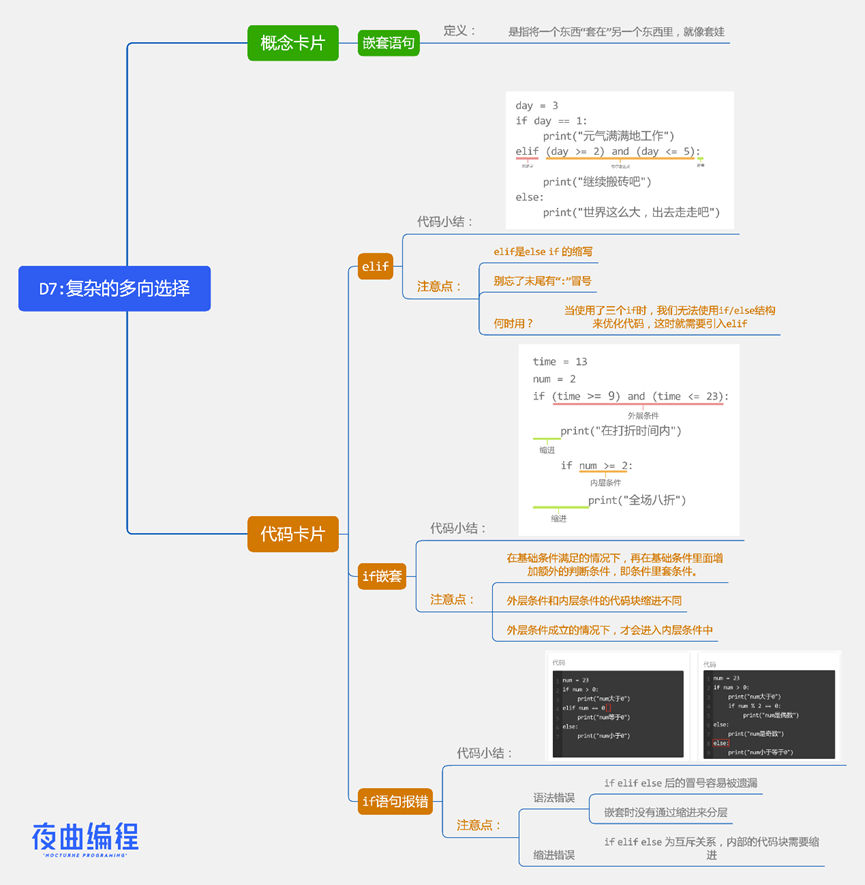


 发表于 2024-9-25 17:55
发表于 2024-9-25 17:55



