金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
生物信息学或者计算生物学,未来几年发展将会加快。
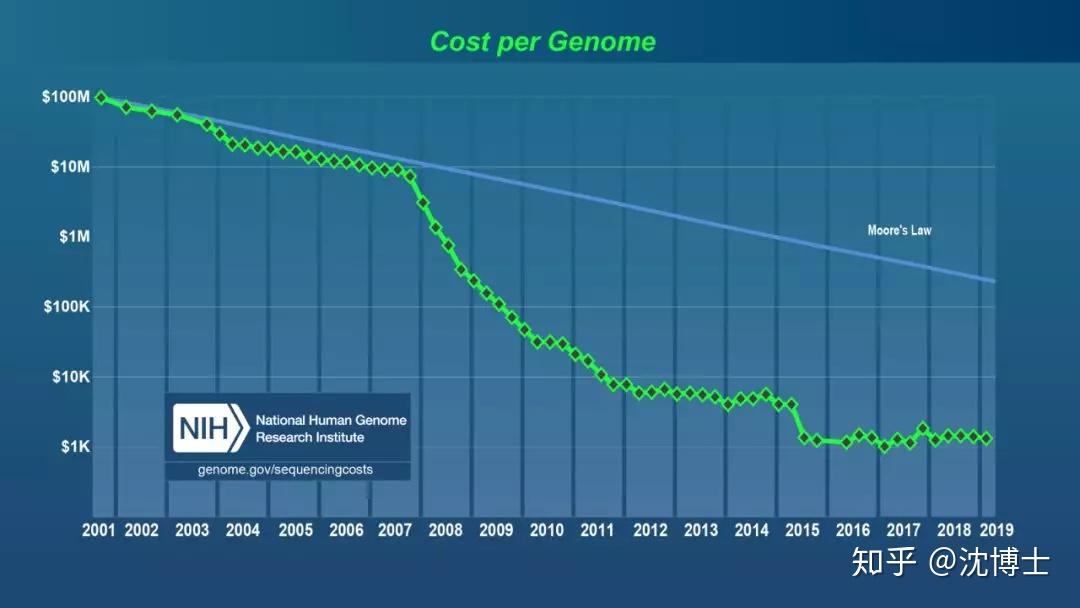
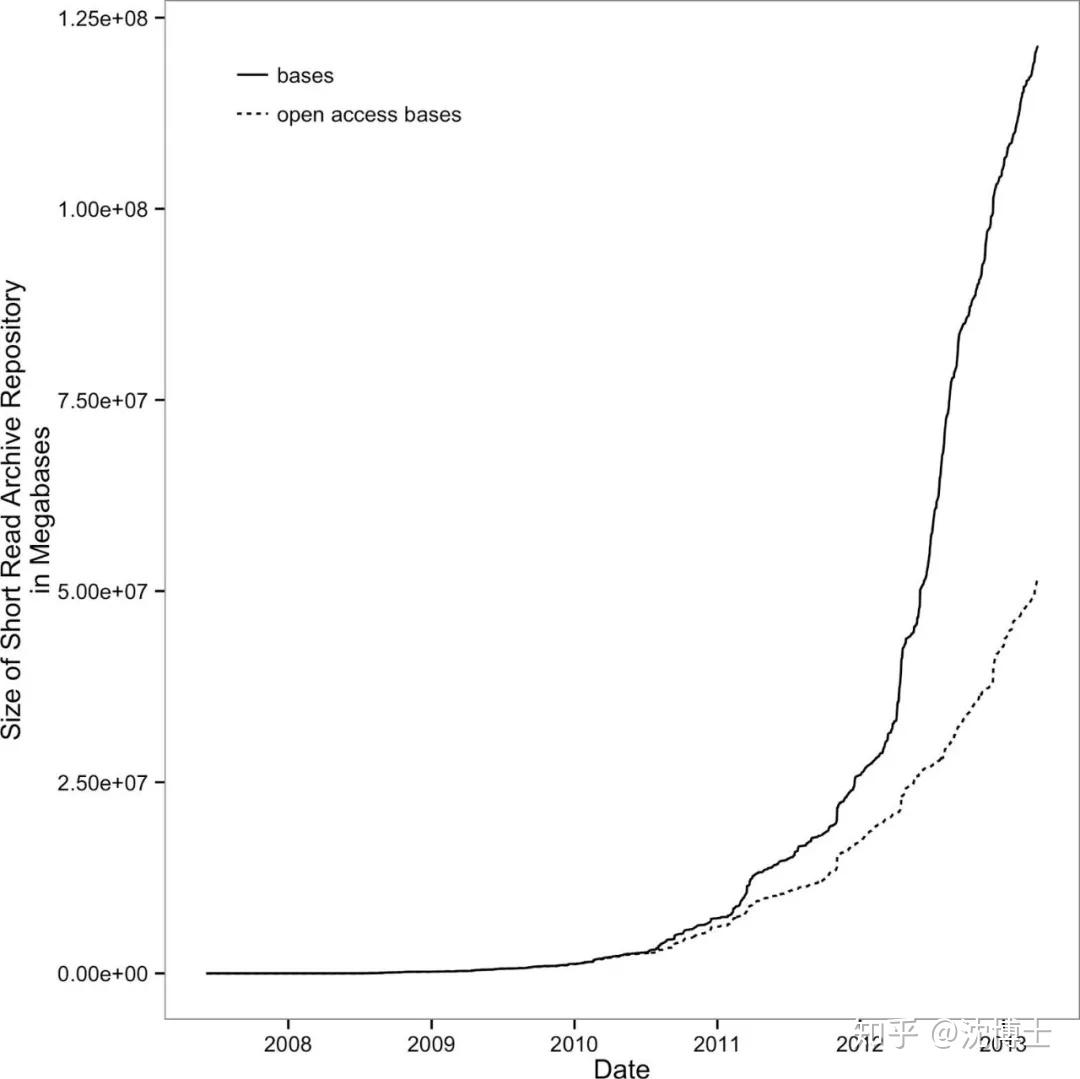
1 数据产生的速度
我们来看一组数据:
- GSE1000,Public on Jan 28, 2004
- GSE5100,Public on Jun 20, 2006。GSE5000查不到
- GSE10000,Public on Dec 16, 2008。
一年增加1000个数据左右
- GSE20000, Public on Jan 26, 2010
- GSE30000, Public on Jun 16, 2011
- GSE50000, Public on Feb 15, 2014
一年增加1万个数据集左右
- GSE100000,Public on Apr 25, 2018
- GSE125000,Public on Jan 12, 2019
- GSE150000,Public on Jul 09, 2021
一年增加1.5万个数据左右
- GSE150000,Public on Jul 09, 2021
- GSE175000,Public on May 23, 2021
- GSE200100,Public on Apr 09, 2022
一年增加3万个数据左右
我们可以看看,数据生成的速度在不断加快。
2 技术的变化
多组学:组装相关的算法、统计分析相关的算法、变异分析算法(CNN、Transformer)等
单细胞:PCA降维 -> VAE(变分自动编码器) -> 一维Transformer(注意力机制)等
蛋白质结构预测:三维Transformer(注意力机制,AlphaFold)等
肿瘤微环境:图论、知识发现、因果推理等
3 应用与挑战
3.1 单细胞多组学的挑战
Single-cell transcriptomics in cancer: computational challenges and opportunities
3.2 临床应用的挑战
From bench to bedside: Single-cell analysis for cancer immunotherapy
3.3 免疫治疗的挑战
Technological advances in cancer immunity: from immunogenomics to single-cell analysis and artificial intelligence
3.4 药物发现
Artificial intelligence in drug discovery and development
<hr/>生物信息学或者计算生物学在未来将有非常多的机会与挑战,如果需要加一个新名词,那就是AI for Life Science,生命科学+人工智能,将在未来发挥重要的作用。
<hr/>我们正在准备动手学系列教程、动手建系列图谱,希望和大家一起成长同时,也建立一系列有用的工具和数据库。
已开展的工作:
我们不断在更新,请持续关注!
<hr/>1. 《动手学深度学习》
目录
第一章 介绍
第二章 基础
第三章 进阶
第四章 提升
第五章 自监督学习
第六章 自然语言处理
第七章 计算机视觉
第八章 应用案例
2. 《动手学单细胞分析》
目录:
第一章 介绍
第二章 基础
第三章 进阶
第四章 提升
-- 待更新
3. 《动手建人类细胞图谱》
目录:
第一章 介绍
-- 待更新
4. 《动手学肿瘤免疫微环境分析》
-- 待更新
5. 《动手建人类肿瘤免疫微环境图谱》
-- 待更新
谢谢您的支持!
## 联系我们 ##
如果您有任何意见和建议,或者技术服务需求,请随时联系我们。
公众号: AI-for-Sci |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-9-25 11:06
发表于 2024-9-25 11:06


 发表于 2024-9-25 11:06
发表于 2024-9-25 11:06