金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
在对时间序列进行分析的时候,经常会碰到具有周期性和非周期性的时间序列,这两种序列需要区别对待。那如何去判断时间序列的周期性呢?本文将介绍一种方法来检测时间序列的周期性。
检测方法
平滑处理
时间序列经常会出现毛刺的点,需要做平滑处理才能分析,类似下图中的数据。
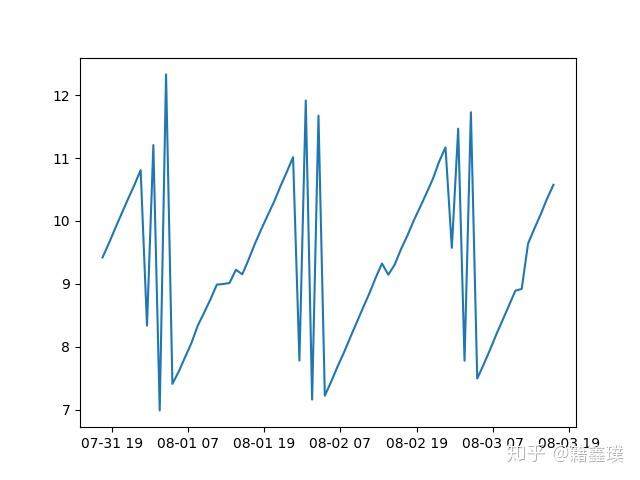
消除数据的毛刺,可以用移动平均法,但是移动平均有时候处理完后并不能使数据平滑,本文中采用的方法很简单:把每个点与上一点的变化值作为一个新的序列,对里边的异常值,也就是变化比较离谱的值剃掉,用前后数据的均值填充,详细的代码如下diff_smooth函数,输入的变量为时间序列以及要处理后的时间间隔,输出为处理后的时间序列。
def diff_smooth(ts, interval):
'''时间序列平滑处理'''
# 间隔为1小时
wide = interval/60
# 差分序列
dif = ts.diff().dropna()
# 描述性统计得到:min,25%,50%,75%,max值
td = dif.describe()
# 定义高点阈值,1.5倍四分位距之外
high = td['75%'] + 1.5 * (td['75%'] - td['25%'])
# 定义低点阈值
low = td['25%'] - 1.5 * (td['75%'] - td['25%'])
i = 0
forbid_index = dif[(dif > high) | (dif < low)].index
while i < len(forbid_index) - 1:
# 发现连续多少个点变化幅度过大
n = 1
# 异常点的起始索引
start = forbid_index
if (i+n) < len(forbid_index)-1:
while forbid_index[i+n] == start + datetime.timedelta(minutes=n):
n += 1
i += n - 1
# 异常点的结束索引
end = forbid_index
# 用前后值的中间值均匀填充
value = np.linspace(ts[start - datetime.timedelta(minutes=wide)], ts[end + datetime.timedelta(minutes=wide)], n)
ts[start: end] = value
i += 1
return ts
上图的数据经过处理以后,变成了下图的样子。可以看到毛刺已经被去掉,序列变得平滑了很多,有利于我们进行下面的分析。
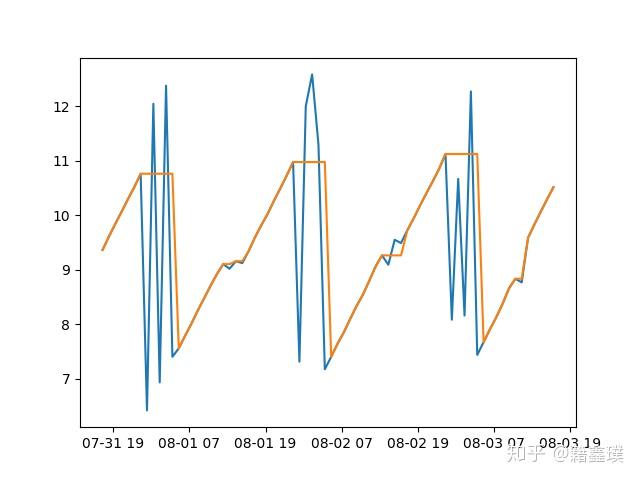
分段求DTW
对数据进行平滑处理以后,我们接下来就会检测序列是否具有周期性。对周期性进行检测,很容易想到的方法是:
- 找到时间序列的周期T;
- 以T为分割点,对序列进行分割。假设序列的长度是n,分割后就会有n/T个单元;
- 比较这n/T个单元的相似度,如果比较相似,则说明具有周期性,如果不是,则不具有周期性;
本文也按照上面的方法对序列进行切割,切割后形成三个单元,如下图:
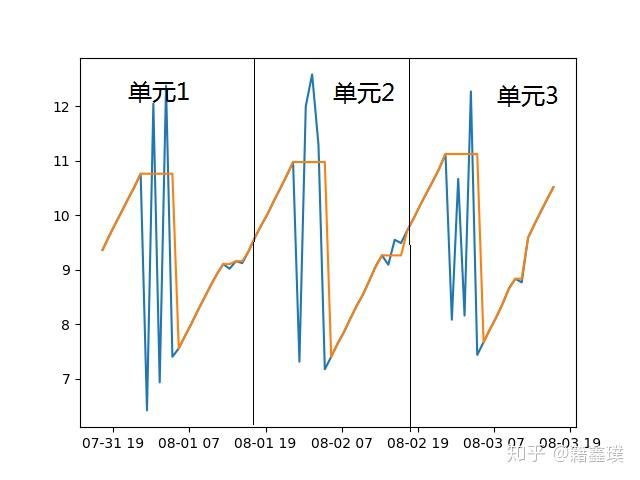
对于序列周期性检测最终转化为求三个单元的相似度。求时间序列的相似度有皮尔逊相关系数、有曲线拟合方法等,我们借鉴了NLP中求语音片段相似度的方法--DTW距离,来求三个单元的相似度。DTW通过把时间序列进行延伸和缩短,来计算两个时间序列性之间的相似性。
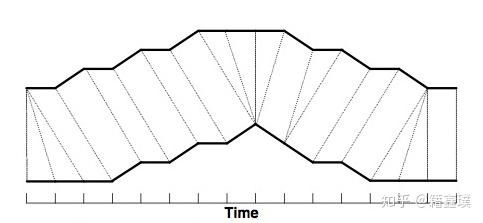
如上图所示,上下两条实线代表两个时间序列,时间序列之间的虚线代表两个时间序列之间的相似的点。DTW使用所有这些相似点之间的距离的和,称之为归整路径距离(Warp Path Distance)来衡量两个时间序列之间的相似性。
python中有dtw包,直接可以计算两个时间序列的相似度。
dist, cost, acc, path = dtw(x, y, dist=lambda x, y: np.linalg.norm(x - y, ord=1))返回值中dist代表距离,如果dist越大,则距离越大,两个时间序列越不相似。
本文比较了两个相邻时间单元的相似度,也就是求相邻单元的DTW距离。假如有N个时间单元的话,就需要求N-1次距离。我们将所有的距离值保存到dist_list这个列表中,根据设置的阈值,就可以判断出是否具有周期性。
DTW的阈值到底设置多少比较合适?到目前为止,还没有一个比较好的思路。我们是通过观察所有曲线来区设置该阈值。如果您有比较好的方法,可以和我联系。
总结
上一篇博客介绍了周期性时间序列的预测工作,这篇介绍了时间序列的检测方法,至此,对于时间序列的分析将告一段落,但是我们的研究不会停止,接下来还会有智能运维领域的更多研究成果,请您持续关注。
原文地址:https://zhuanlan.zhihu.com/p/43136171 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-9-12 06:32
发表于 2024-9-12 06:32



