金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
作为一名生物信息从业者,我倾向于用数据来说话。
话说之前已经回答过类似的问题了(链接),只是之前比较的是生物信息和分子生物学的薪资差异。这次想要看看生物信息和另外两个工作性质比较相近的职业之间的差异:开发工程师和数据分析。
生物信息的薪资:比上不足比下有余
- 数据是还是从猎聘上面搜集的,分别用生物信息、生物技术、开发工程师和数据分析四个关键词来搜索,获取前5页,保存html到本地文件夹中。
- 然后用python脚本提取里面的数据,进行数据清洗。
- 使用R语言绘制图表。
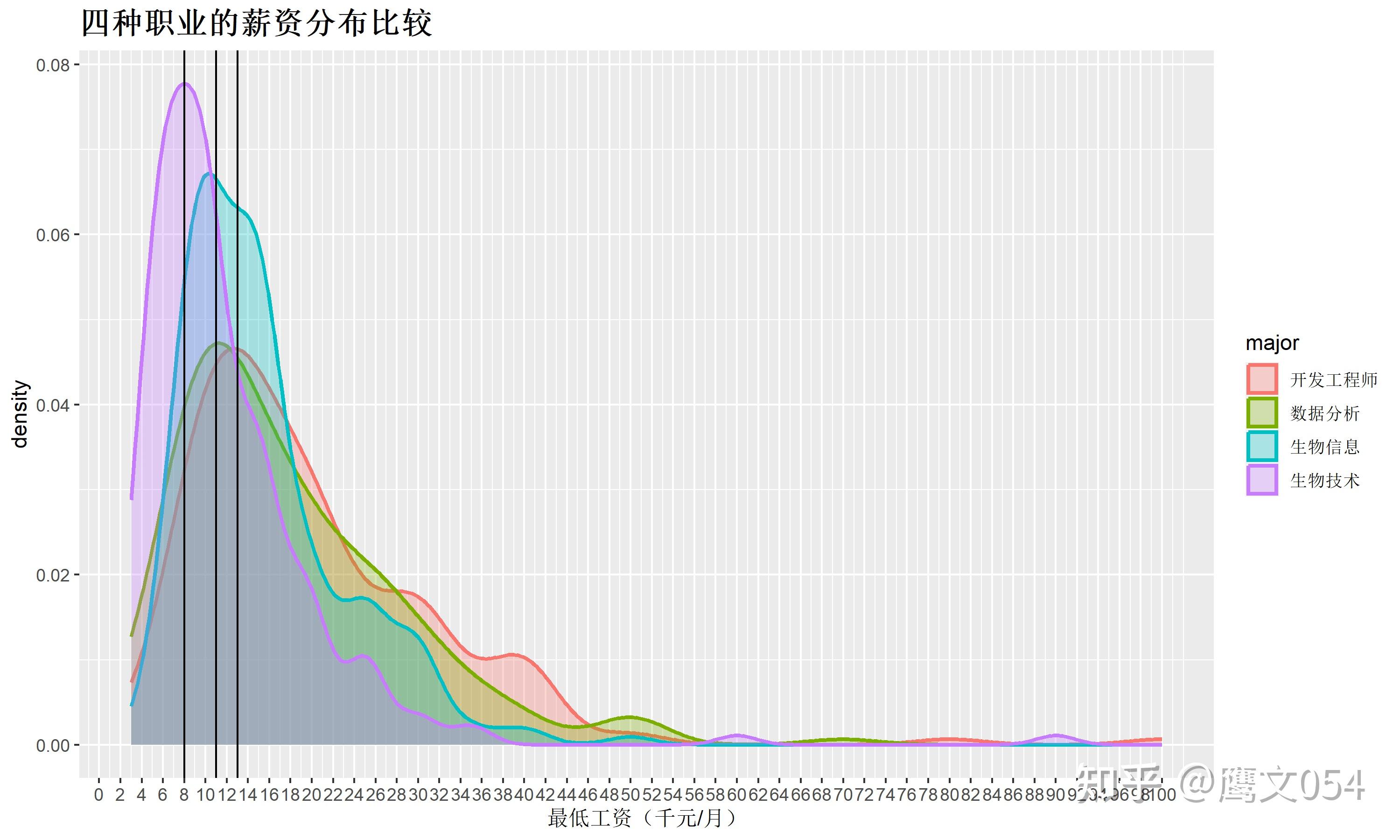
图1 四种职业的薪资分布图
根据上面的图表(图1),我们可以知道生物信息和数据分析相关的职位的工资大多在11K左右,生物技术相关职位在8K左右,开发工程师的工资在13K左右。果然还是程序员比较香。
生物信息的待遇明显要比生物技术的好,但是和岗位性质最相似的数据分析相比,在发展空间上显得不足,薪资20K以上的职位的比例明显比数据分析的低。
生物信息岗位数最少,但人员供给也少
在猎聘网上,限定了10K-20K,城市为上海以后:生物信息的岗位有10页(注:每页有40个岗位)。生物技术有20页。数据分析有20页。开发工程师也是20页。
限定了10K-20K,城市为重庆后:生物信息25个(不足1页)。生物技术4页。数据分析20页。开发工程师20页。
这说明了生物信息和另外三个职位的岗位数相比还是比较少的。不过这并不代表生物信息的工作难找,相反,从我个人的感觉来看,由于现有开设生物信息学的高校比较少,生物信息和其他几个专业相比找工作还是相对容易的。在学信网上可以搜索到,开设生物信息专业的学校有42个;开设生物技术专业的学校有368个;开设数据科学与大数据技术的学校有219个;开设软件工程的学校有645个。
生物信息学主要从事什么工作?
也是利用上面得到的数据,筛选出生物信息相关的岗位名称、相应的公司名称,分别过滤掉没有信息量的词以及单字以后,绘制词云图(图2、图3)。从岗位名称词云图里面,我觉得“工程”以及“科学”两个词师最能够反应这个岗位的性质的。工程,对应生物信息分析工程师这个岗位,一般在公司的技术部门工作,主要是运行流程、开发流程、开发软件等。科学,对应生物信息科学家,一般在公司的研发部门或者高校工作,更偏向于开发软件或者利用生物信息的技术来研究科学问题。
从公司的词云图来看,生物信息相关岗位主要集中在大城市,与生物医药有密切的联系。

图2 生物信息学岗位词云

图3 生物信息学公司词云
生物信息的工作内容
实际上,我这个回答的整个流程展示了生物信息的工作的基本流程:采集数据、整理数据、数据可视化、解读数据。为了采集数据,需要对各个生物学数据库比较熟悉。要整理数据和进行数据可视化,需要有一定的编程以及统计学的知识。为了解读数据,需要有相关的生物学知识背景。
总结
怎样,看完这个分析报告,你应该对生物信息相关的工作,以及薪资待遇非常清楚了吧。
还不赶紧点个赞!
以上分析用到的脚本:
数据整理脚本(python3)
# python3
from bs4 import BeautifulSoup
import pandas as pd
import re
majors = ["生物技术", "生物信息", "数据分析", "开发工程师"]
df = {"major":[], "position": [], "salary": [], "basic_salary": [], "company": []}
for major in majors:
for page in range(1, 6):
page = str(page)
html = open(f"data/{major}/{page}.html", encoding="utf-8").read()
soup = BeautifulSoup(html, 'html.parser')
jobs = soup.find_all("div", attrs={"class": "jsx-2297469327 job-card-pc-container"})
for job in jobs:
position = job.find("div", attrs={"class": "jsx-2693574896 ellipsis-1"})
position = position.attrs["title"]
salary = job.find("span", attrs={"class": "jsx-2693574896 job-salary"})
salary = salary.string
basic_salary = re.match("(\d+)-", salary)
if basic_salary:
basic_salary = basic_salary.group(1)
else:
basic_salary = "NA"
company = job.find("span", attrs={"class": "jsx-2693574896 company-name ellipsis-1"})
company = company.string
df["major"].append(major)
df["position"].append(position)
df["salary"].append(salary)
df["basic_salary"].append(basic_salary)
df["company"].append(company)
df2 = pd.DataFrame(df)
df2.to_csv("out.csv", encoding="gbk")绘图脚本(R):
# 绘制工资分布图
library(ggplot2)
data <- read.csv(&#34;out.csv&#34;, fileEncoding = &#34;gbk&#34;, row.names=1)
p <- ggplot(data, aes(basic_salary)) +
geom_density(aes(fill=major, color=major), alpha=.3, size=1) +
scale_x_continuous(breaks = seq(0, 100, by = 2)) +
geom_vline(aes(xintercept=8)) +
geom_vline(aes(xintercept=11)) +
geom_vline(aes(xintercept=13)) +
labs(x=&#34;最低工资(千元/月)&#34;, title=&#34;四种职业的薪资分布比较&#34;) +
theme(plot.title=element_text(face = &#34;bold&#34;, size=16))
ggsave(&#34;density_plot.png&#34;, p, width=10, height=6)
# 绘制词云。我电脑之前已经安装过remotes,这里不再重复安装。
install.packages(c(&#34;tmcn&#34;, &#34;tm&#34;, &#34;wordcloud2&#34;))
remotes::install_github(&#34;cran/Rwordseg&#34;)
library(tmcn)
library(tm)
library(Rwordseg)
library(wordcloud2)
heci <- data$position[data$major==&#34;生物信息&#34;]
ci <- segmentCN(heci)
ci <- unlist(ci)
ci <- ci[nchar(ci) != 1]
wd <- createWordFreq(ci, onlyCN = TRUE, nosymbol = TRUE,
stopwords = c(&#39;招聘&#39;),useStopDic = T)
wordcloud2(wd, size = 1)
heci <- data$company[data$major==&#34;生物信息&#34;]
ci <- segmentCN(heci)
ci <- unlist(ci)
ci <- ci[nchar(ci) != 1]
wd <- createWordFreq(ci, onlyCN = TRUE, nosymbol = TRUE,
stopwords = c(&#39;公司&#39;, &#39;有限&#39;),useStopDic = T)
wordcloud2(wd, size = 1) |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-9-6 19:59
发表于 2024-9-6 19:59


 发表于 2024-9-6 20:01
发表于 2024-9-6 20:01



