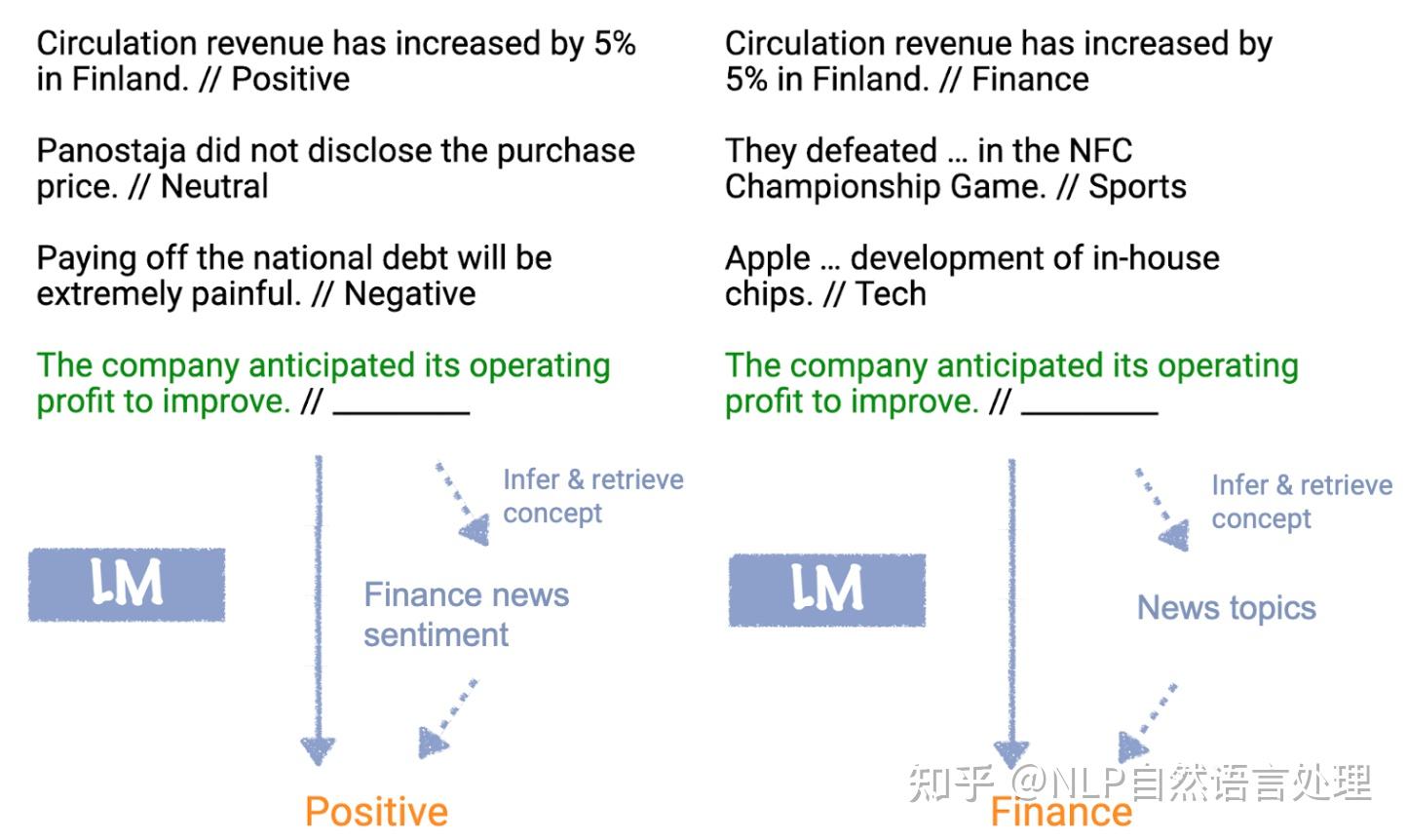
在对于ICL能力的早期研究中,斯坦福Xie等人的论文“An Explanation of In-context Learning as Implicit Bayesian Inference”也试图研究ICL是如何出现在预训练过程中的,并提出了一个数学框架进行解释,在这个框架中,LM使用上下文学习提示来“locate”先前学习的concept来完成上下文学习任务。如下图所示:LM使用训练示例在内部确定任务是情感分析(左)还是主题分类(右),并将相同的映射应用到测试输入。
如果p(concept|prompt)用更多的例子集中在提示概念上,LM通过边缘化的方式“选择”提示concept——这等同于执行贝叶斯推理。
接下来,作者详细描述了他们的理论设置——预训练分布是一个混合HMM (MoHMM),用\theta表示潜在概念中的一个concept,它定义了词汇表中可见Token的分布。他们通过从先验p(\theta)中抽取concept来生成文档,并在给定concept的情况下对文档进行抽样——给定concept的文档(长度为 T 的序列)的概率由HMM定义,\theta决定HMM 的转移概率矩阵隐藏状态。他们的上下文预测器,贝叶斯预测器,根据提示分布给出的提示,在预训练分布上输出了最大可能的预测。最终实验证明了「当预训练分布是HMM的混合分布时,上下文学习就会发生」。
另外一项工作是Min等发布的“Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?”,本文主要分析了prompt的哪些方面会影响模型在下游任务中的表现,具体包括:输入标签映射、输入文本的分布、标签空间、格式。在文中作者发现,在一系列分类和多选择任务上,模型采用随机标签和Gold标签示例能够实现类似的改进,并都要优于Few-shot极限版本。除此之外,标签空间的调整对于模型性能有显著的提示,格式的对于模型效果的改进同样重要,
总之,对于ICL而言,最终重要的三件事是输入分布(ICL提示样例中的底层分布输入来自于此)、输出空间(任务中的输出类或答案选择集)以及提示格式。斯坦福大学人工智能实验室的一篇博客文章(http://ai.stanford.edu/blog/understanding-incontext/)将Min等人的研究成果与Xie等人提出的假设联系起来:「由于LM不依赖于提示中的输入-输出对应关系,它们可能已经在预训练期间接触到这种对应关系的概念,然后ICL就会利用这种对应关系」。提示的其它样例可以被视为提供证据,使模型能够定位它已经学习的concept(Xie将其定义为包含文档级统计信息的潜在变量)。 Induction heads&梯度下降
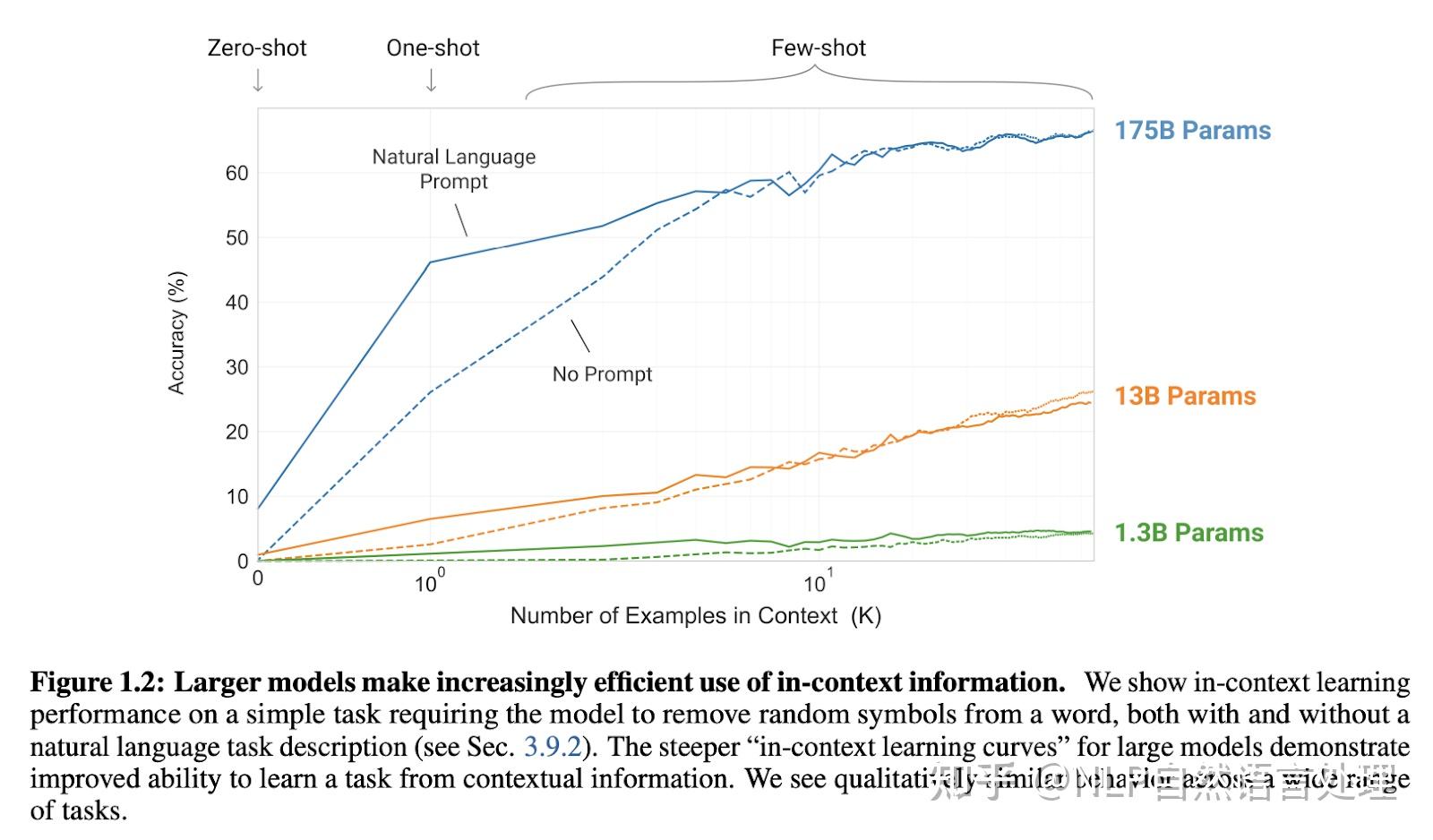
首先,“The Learnability of In-Context Learning”提出了首个基于PAC的上下文可学习框架。通过对模型的预训练样例数量和下游任务样例数量的假设,作者指出当预训练分布是潜在混合任务时,这些任务可以通过ICL进行有效地学习。这篇论文的主要结论是:「这项工作进一步激发了ICL定位语言模型已经学习的概念的直觉」。
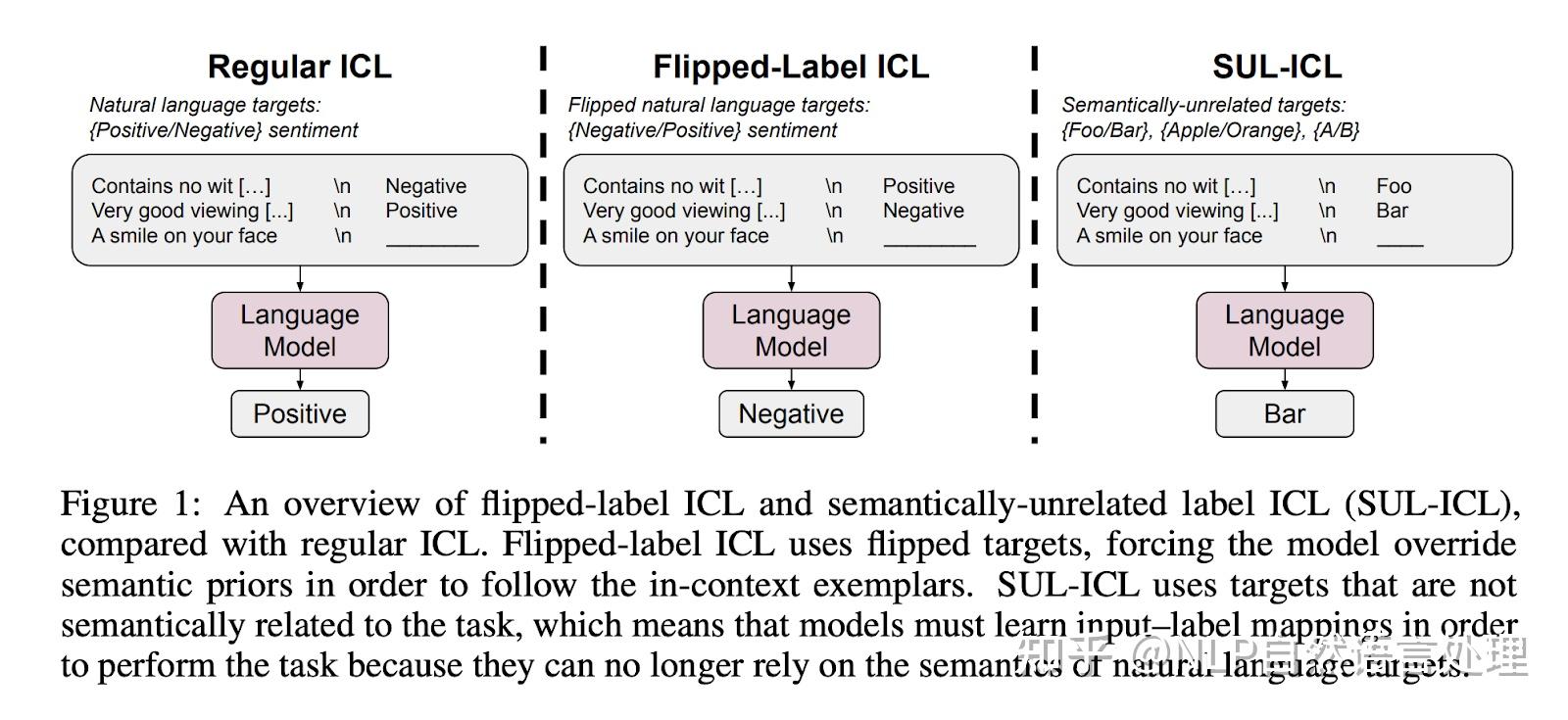
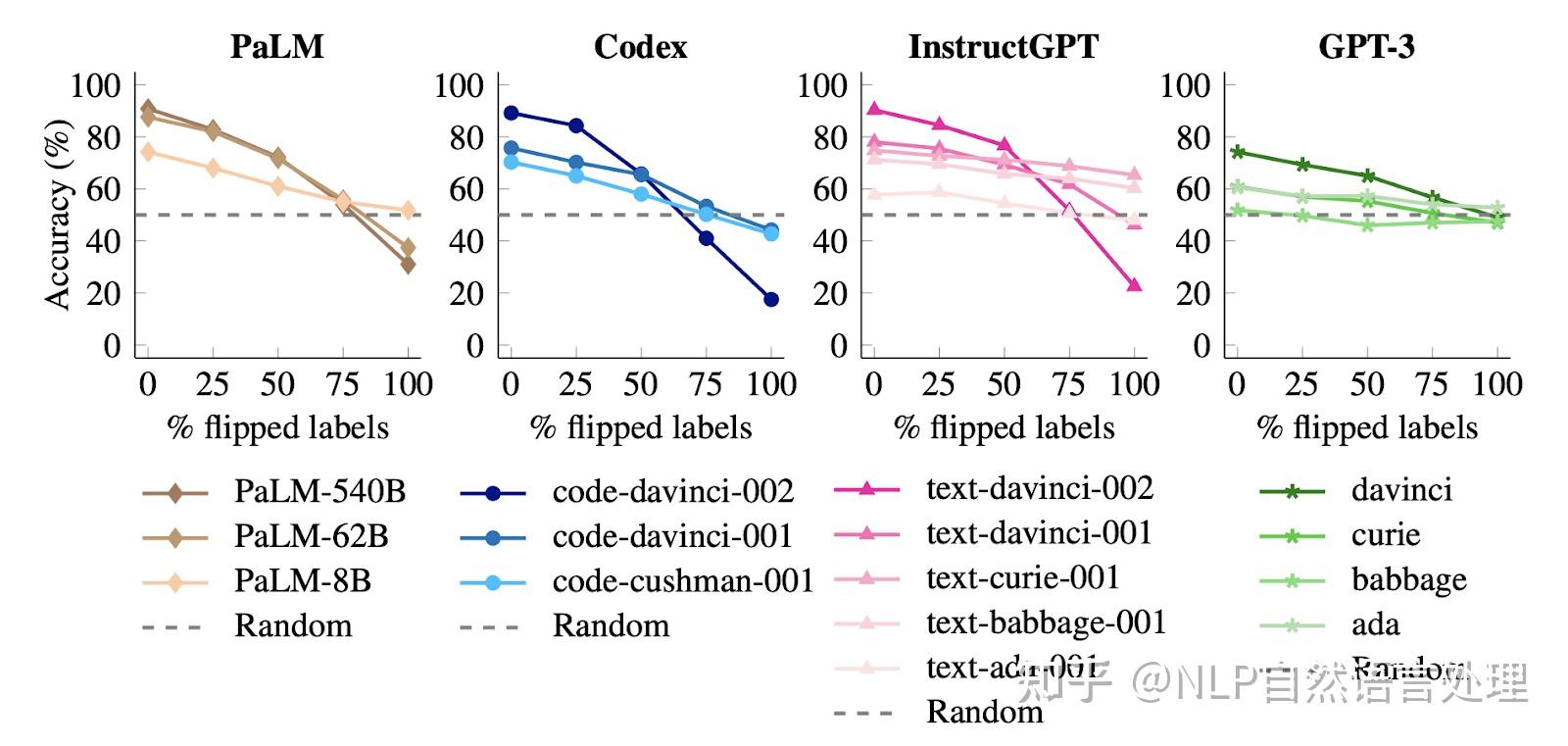
然后,“Large Language Models Do In-Context Learning Differently”「进一步研究了ICL的哪些方面会影响性能,进一步阐明“学习”是否真的发生在ICL中」。“Rethinking the Role of Demonstrations”表明,呈现具有随机映射而不是正确输入输出值的模型不会对性能产生实质性影响,这表明语言模型主要依赖于语义先验知识,同时遵循上下文示例的格式。 同时,关于 ICL 和梯度下降的研究表明,简单设置中的变换器从上下文示例中学习输入标签映射。在本文,Wei等人研究了语义先验和输入标签映射如何在三种情况下相互作用:

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2024-9-5 13:39
发表于 2024-9-5 13:39




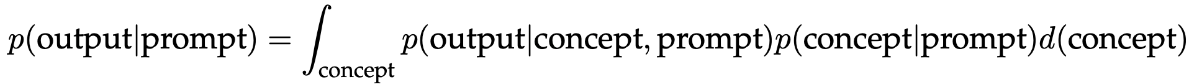

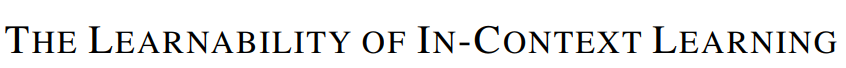

 提升卡
提升卡


