金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
DeepSeek前脚刚发布R1模型,又赶在大年三十发布了最新的多模态大模型Janus-Pro-7B,支持理解生成图像,这可能又是一个爆炸性的产品,要知道R1已经在海外火的一塌糊涂,让英伟达股票大跌10%以上,连ChatGPT都回应:排名变化也许是暂时的。
先看看官方展示的文生图demo,效果还是相当可以。


Janus-Pro-7B是在Janus(24年11月发布)基础上升级的,并非全新产品,这一次优化了训练策略,扩大了训练数据,模型规模也更大,因此不管是多模态理解还是文生图能力都强大很多。
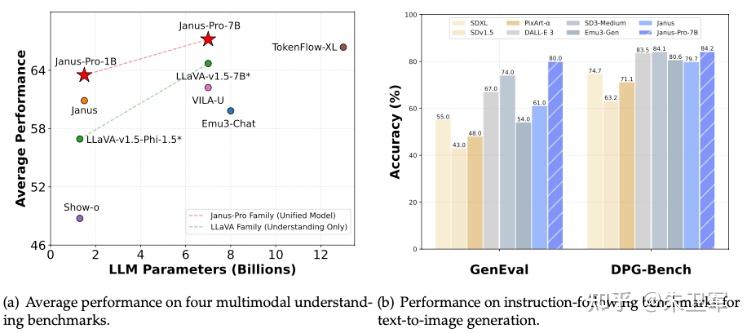
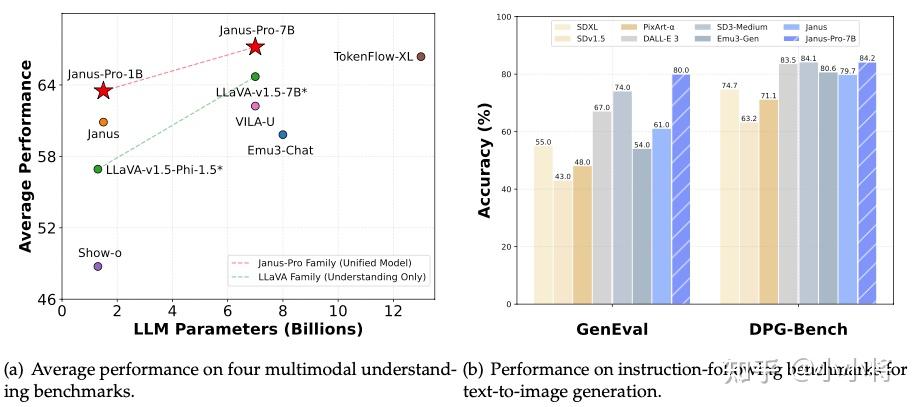
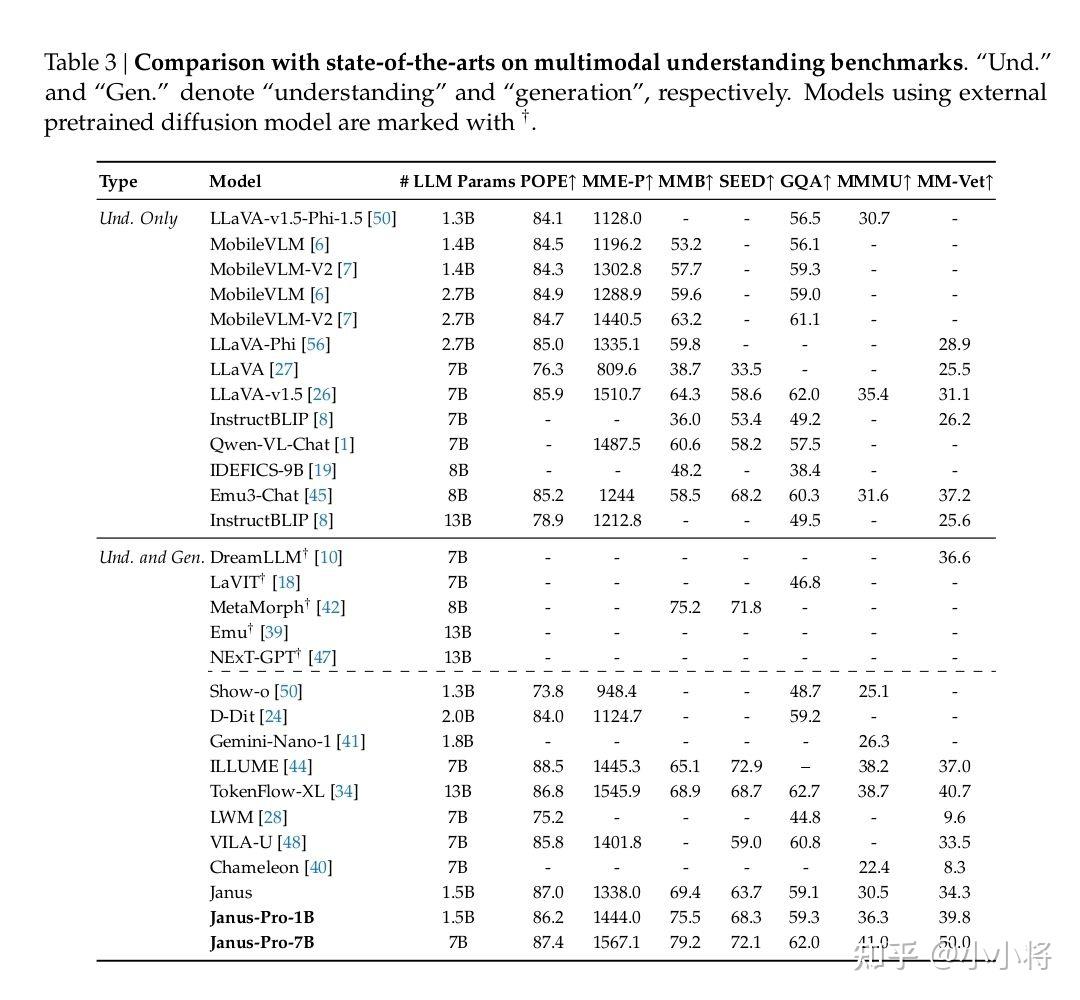
大家可以看下上面多模态模型相关的两项性能对比。
左边的图用来评价多模态模型在四个多模态理解基准测试上的平均性能,横轴为大语言模型(LLM)参数数量(单位为十亿),纵轴为平均性能。
和LLaVA - v1.5 - 7B+、VILA - U、Emu3 - Chat、LLaVA - v1.5 - Phi - 1.5、Show - o 相比,Janus-Pro-7B有明显的性能优势。
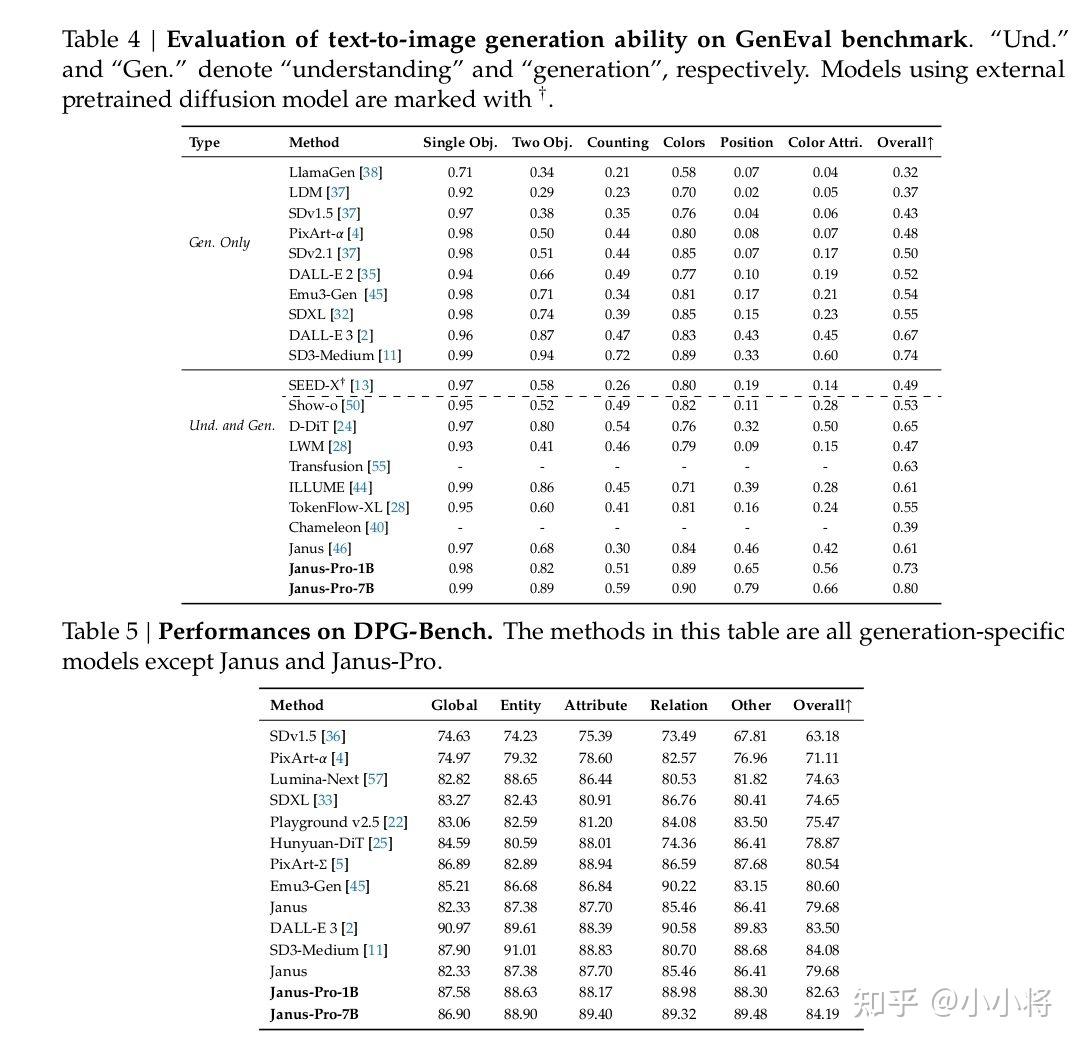
右边的图用来评价模型在文生图指令跟随基准测试(GenEval 和 DPG - Bench)上的准确率, 两项指标都超过了DALL・E 3、Emu3 - Gen、SDXL、Pika - v1 - 0、SD3 - Medium、SDV1.5等模型。
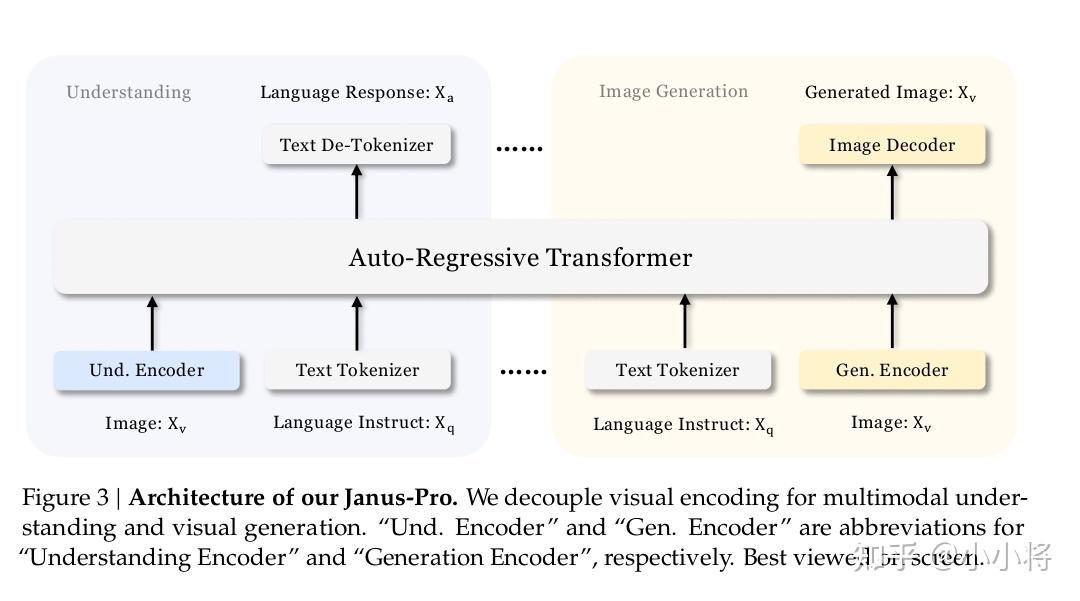
从技术上看,Janus-Pro-7B采用了一种全新的自回归框架,把视觉编码分成不同路径,分别来处理多模态理解和文生图,两个任务互不干扰,能避免混乱,图像理解和生成质量会更高。
怎么理解呢?传统模型是一个人干两个人的活(理解和生成),而Janus-Pro-7B则是派两个人分别做理解和生成图像这两件事,这样增强了整个框架的灵活性,能更好地应对不同的情况。
现在DeepSeek网页版和手机端都还不支持文生图功能,似乎只可以下载模型后做本地部署。
# Load model directly
from transformers import AutoModel
model = AutoModel.from_pretrained("deepseek-ai/Janus-Pro-7B")上面这段代码用来加载预训练模型,transformers 库会自动从 Hugging Face 模型库中下载 Janus-Pro-7B 模型的权重文件,并加载到内存中。
然后使用加载的模型进行文生图等操作,具体我还没来得及测试,后面抽时间玩玩。
以下是官方示例的注释版,我做了中文备注,大家可以看看。
首先是多模态理解的代码,也就是图像识别。
import torch
# 从transformers库中导入用于因果语言模型的类
from transformers import AutoModelForCausalLM
# 从janus.models模块中导入多模态因果语言模型和VLChat处理器
from janus.models import MultiModalityCausalLM, VLChatProcessor
# 从janus.utils.io模块中导入加载PIL图像的函数
from janus.utils.io import load_pil_images
# 指定要使用的模型路径,这里使用的是deepseek-ai组织的Janus-Pro-7B模型
model_path = "deepseek-ai/Janus-Pro-7B"
# 从指定路径加载VLChat处理器,该处理器用于处理多模态对话的输入
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
# 从VLChat处理器中获取分词器,用于将文本转换为模型可接受的输入格式
tokenizer = vl_chat_processor.tokenizer
# 从指定路径加载多模态因果语言模型
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True # 允许加载远程代码,因为模型可能依赖一些自定义的代码
)
# 将模型的数据类型转换为bfloat16,以减少内存使用和加速计算
vl_gpt = vl_gpt.to(torch.bfloat16)
# 将模型移动到GPU上进行计算
vl_gpt = vl_gpt.cuda()
# 将模型设置为评估模式,关闭一些在训练时使用的特殊操作(如Dropout)
vl_gpt = vl_gpt.eval()
# 定义一个对话列表,模拟用户和模型之间的交互
conversation = [
{
# 表示这是用户的发言
&#34;role&#34;: &#34;<|User|>&#34;,
# 用户的发言内容,<image_placeholder>表示此处有一张图片,question是用户的文本问题
&#34;content&#34;: f&#34;<image_placeholder>\n{question}&#34;,
# 用户提供的图片列表,这里假设image是一个有效的图像对象
&#34;images&#34;: [image],
},
{
# 表示这是助手(模型)的发言,初始内容为空,等待模型生成回复
&#34;role&#34;: &#34;<|Assistant|>&#34;,
&#34;content&#34;: &#34;&#34;
},
]
# 调用load_pil_images函数加载对话中涉及的图片,并将其转换为PIL图像对象
pil_images = load_pil_images(conversation)
# 使用VLChat处理器对对话和图像进行处理,将其转换为模型可接受的输入格式
# force_batchify=True表示强制进行批量处理
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device) # 将处理后的输入移动到与模型相同的设备上
# 调用模型的prepare_inputs_embeds方法,对处理后的输入进行编码,得到图像嵌入表示
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
# 使用模型的语言模型部分进行生成,得到回复的输出
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds, # 输入的嵌入表示
attention_mask=prepare_inputs.attention_mask, # 注意力掩码,用于指示哪些位置需要关注
pad_token_id=tokenizer.eos_token_id, # 填充标记的ID,这里使用结束标记的ID
bos_token_id=tokenizer.bos_token_id, # 开始标记的ID
eos_token_id=tokenizer.eos_token_id, # 结束标记的ID
max_new_tokens=512, # 最大生成的新标记数量
do_sample=False, # 不使用采样策略,采用贪心搜索生成
use_cache=True # 使用缓存以加速生成过程
)
# 将模型生成的输出解码为文本,跳过特殊标记
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
# 打印格式化的输入和模型生成的回复
print(f&#34;{prepare_inputs[&#39;sft_format&#39;][0]}&#34;, answer)接着是文生图的代码。
import os
import PIL.Image
import torch
import numpy as np
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
# 指定要使用的模型路径,这里使用的是 deepseek-ai 组织的 Janus-Pro-7B 模型
model_path = &#34;deepseek-ai/Janus-Pro-7B&#34;
# 从指定路径加载 VLChat 处理器,该处理器用于处理多模态对话的输入
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
# 从 VLChat 处理器中获取分词器,用于将文本转换为模型可接受的输入格式
tokenizer = vl_chat_processor.tokenizer
# 从指定路径加载多模态因果语言模型
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True # 允许加载远程代码,因为模型可能依赖一些自定义的代码
)
# 将模型的数据类型转换为 bfloat16,以减少内存使用和加速计算
vl_gpt = vl_gpt.to(torch.bfloat16)
# 将模型移动到 GPU 上进行计算
vl_gpt = vl_gpt.cuda()
# 将模型设置为评估模式,关闭一些在训练时使用的特殊操作(如 Dropout)
vl_gpt = vl_gpt.eval()
# 定义一个对话列表,模拟用户和模型之间的交互
conversation = [
{
# 表示这是用户的发言
&#34;role&#34;: &#34;<|User|>&#34;,
# 用户的发言内容,描述了一个来自喀布尔,穿着红白传统服装,蓝眼睛、棕头发的迷人公主
&#34;content&#34;: &#34;A stunning princess from kabul in red, white traditional clothing, blue eyes, brown hair&#34;,
},
{
# 表示这是助手(模型)的发言,初始内容为空,等待模型生成回复
&#34;role&#34;: &#34;<|Assistant|>&#34;,
&#34;content&#34;: &#34;&#34;
},
]
# 对多轮对话提示应用 SFT(Supervised Fine-Tuning)模板
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt=&#34;&#34;, # 系统提示为空
)
# 拼接图像开始标签,形成最终的提示
prompt = sft_format + vl_chat_processor.image_start_tag
# 使用 torch.inference_mode() 上下文管理器,禁用梯度计算,以提高推理速度
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM, # 多模态因果语言模型
vl_chat_processor: VLChatProcessor, # VLChat 处理器
prompt: str, # 输入的提示文本
temperature: float = 1, # 温度参数,控制生成的随机性
parallel_size: int = 16, # 并行生成的图像数量
cfg_weight: float = 5, # 分类器自由引导(CFG)的权重
image_token_num_per_image: int = 576, # 每张图像的令牌数量
img_size: int = 384, # 生成图像的大小
patch_size: int = 16, # 图像块的大小
):
# 使用分词器对提示文本进行编码,转换为模型可接受的输入 ID
input_ids = vl_chat_processor.tokenizer.encode(prompt)
# 将输入 ID 转换为 PyTorch 的 LongTensor 类型
input_ids = torch.LongTensor(input_ids)
# 创建一个形状为 (parallel_size*2, len(input_ids)) 的零张量,用于存储输入的令牌
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size*2):
# 将输入 ID 复制到每个样本中
tokens[i, :] = input_ids
# 对于奇数样本,将除首尾之外的令牌设置为填充 ID
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id
# 通过模型的输入嵌入层将令牌转换为嵌入向量
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
# 创建一个形状为 (parallel_size, image_token_num_per_image) 的零张量,用于存储生成的图像令牌
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
# 逐令牌生成图像
for i in range(image_token_num_per_image):
# 运行模型,获取输出
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
# 获取模型的最后一层隐藏状态
hidden_states = outputs.last_hidden_state
# 通过生成头将隐藏状态转换为对数概率
logits = mmgpt.gen_head(hidden_states[:, -1, :])
# 分离条件对数概率和无条件对数概率
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
# 应用分类器自由引导(CFG)
logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
# 对对数概率应用 softmax 函数,得到概率分布
probs = torch.softmax(logits / temperature, dim=-1)
# 根据概率分布采样下一个令牌
next_token = torch.multinomial(probs, num_samples=1)
# 将采样得到的令牌存储到生成的图像令牌张量中
generated_tokens[:, i] = next_token.squeeze(dim=-1)
# 复制下一个令牌,用于条件和无条件输入
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
# 准备生成图像的嵌入向量
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
# 调整图像嵌入向量的形状
inputs_embeds = img_embeds.unsqueeze(dim=1)
# 使用生成的视觉模型解码生成的图像令牌,得到图像的张量表示
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
# 将图像张量转换为浮点数类型,并移动到 CPU 上,调整维度顺序
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
# 将图像像素值缩放到 [0, 255] 范围
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
# 创建一个形状为 (parallel_size, img_size, img_size, 3) 的零数组,用于存储可视化的图像
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
# 创建一个名为 generated_samples 的目录,用于保存生成的图像
os.makedirs(&#39;generated_samples&#39;, exist_ok=True)
# 遍历每个生成的图像,保存为 JPEG 文件
for i in range(parallel_size):
save_path = os.path.join(&#39;generated_samples&#39;, &#34;img_{}.jpg&#34;.format(i))
PIL.Image.fromarray(visual_img).save(save_path)
# 调用生成函数,传入模型、处理器和提示
generate(
vl_gpt,
vl_chat_processor,
prompt,
) |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-1-28 20:01
发表于 2025-1-28 20:01