金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
我有时候会说人类基因组是代码屎山,人类之外也有许多生物的基因拥有“祖传代码”的低效特征[1],但你是不能对所有生物一概而论的,演化更不是“从第一个 DNA 生物进化至人类,积累了很多祖传代码”这样抽象的情景。
大部分原核生物的基因组是没有内含子的,放眼望去所有的编码都可以发挥功能,尽管经常会有许多功能处在并不好使的状态。
- 远洋杆菌属(Pelagibacter)遍在远洋杆菌(P. ubique)可能是现代地球上数量最多的细菌,估计其数量级在万亿亿亿的程度,可以占据夏季温带海洋表层水中细胞总数的一半左右。该物种世界性分布,是革兰氏阴性菌,以溶解的有机碳为生,是已知的体型最小的独立生活的生物之一,比很多支原体的体型还要小:体长 370~890 纳米,直径 120~200 纳米。
- 2005 年测序表明遍在远洋杆菌 HTCC1062 菌株的基因组为 1308759bp,是已知的自由生活的物种中最小的基因组,只有 1354 个基因。它的基因组不含重复的基因拷贝,没有内含子和病毒基因(当然,正在被噬菌体攻击时例外),并适应缺氮的远海而减少了基因组中使用的氮。
人类已经亲自动手修改过一些生物的基因组,从里面剔除内含子和功能较弱的基因,生物仍然可以正常生存,例如克雷格·文特尔领导的研究组用自然界存在的支原体基因组删改出含有 525 个基因的支原体[2]。
人类基因组里的一些内含子和一些非编码序列是有功能的,目前估计人类基因组里至少 8% 到 15% 的碱基对是必需的。
美国国家人类基因组研究所的公共联合研究项目“DNA元件百科全书(ENCODE)”认为人类基因组的 80% 具有功能——他们对功能的定义过于宽泛,这里面有很多是低效的祖传代码。不过,你并不是总启动着它们的,人类现在的能量获取效率完全支持得起细胞复制时占用这么点核酸。
- 选择性剪切允许外显子和内含子的不同组合让同样的基因结构编码不同的蛋白,不同的基因还可以一起编码新蛋白。人类基因编码的蛋白质数量比基因数量高一个数量级,编码的RNA数量则比基因数量高两到三个数量级。
- 而且,你很快就会看到生活方式远比我们原始的生物在使用超过我们许多倍的庞大基因组。
- 2020 年,对整个人类基因组的研究有一定进展:基因型-组织表达项目相关的研究人员于九月上旬在《科学》、《细胞》等杂志上发表了 15 篇论文介绍他们的发现,《科学》杂志以封面报道的形式对此进行了介绍,你可以去看看。
根据过去几十年的观测事实,基因编码不是程序源码,而是有机体的工具箱,你无法从基因里看出器官排列的方式,多细胞生物的身体构造在很大程度上是细胞发生过程和环境互动的产物。演化也能随机地造成祖传基因的丢失或失去活性,现在每个人的基因组的两万来个基因里都有约 20 个完全沉默。
现代生物学已经放弃“高等生物”“低等生物”这样不准确的描述,“庞大的基因库”也是风趣的表达:
- “基因库”是互相能产生可育后代的群体中的全部个体所含有的全部基因的集合。
- 个体数量极多、遗传多样性高的物种的基因库远比人类大,毕竟全人类的遗传多样性比东非的几千只猩猩的遗传多样性还要低。
- 个体的基因组不是基因库,人类基因组也并不庞大。
正常人染色体 46 条,碱基对约 30 亿个,基因 20000~26000 个,说难听点,够干啥的。
- 老鼠基因组含约 33 亿个碱基对,约 29000 个基因。
- 瓶尔小草属的植物拥有已知多细胞生物中最多的染色体,约 1260 到 1400 条染色体。
- 石花肺鱼拥有已知多细胞动物中最大的基因组,约 1300 亿个碱基对。
- 在 2024 年之前,衣笠草拥有已知多细胞生物中最大的基因组,约 1490 亿个碱基对。这种植物是八倍体,可能是 4 种不同植物的异源多倍体杂交种。

- 2024 年 5 月发表的一篇文章称,Tmesipteris truncata 的单倍体基因组包含 1604.5 亿个碱基对,是现代技术考察范围内真核生物里最多的[3]:
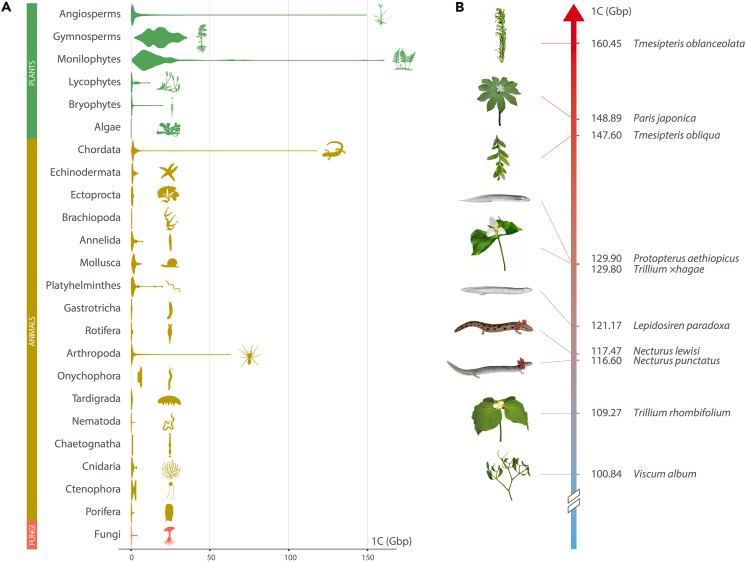
- 无恒变形虫 Polychaos dubium 拥有已知生物中最大的基因组,约 6700 亿个碱基对。不过,这是 1960 年代的分子生物学技术测出的,可能有很大的误差[4]:当年测定大变形虫拥有约 3000 亿个碱基对,现代技术重新测定则为约 400 亿个。但你瞧瞧咱们那 30 亿个的数据好了。
- 色藻界纤毛虫门旋毛纲的单细胞生物 Sterkiella histriomuscorum 拥有已知生物中最多的染色体,其二倍体大核装有约 16000 条染色体。
单细胞真核生物用一个细胞实现极度复杂的功能和丰富多样的行为,其身体构造的复杂程度和基因组的规模都和你我身上的细胞不是一个概念。谈人家是低等生物,很大程度是因为十九世纪的科研工具的性能太差,看不清楚人家在干什么。 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-9-14 15:03
发表于 2024-9-14 15:03


 发表于 2024-9-14 15:03
发表于 2024-9-14 15:03