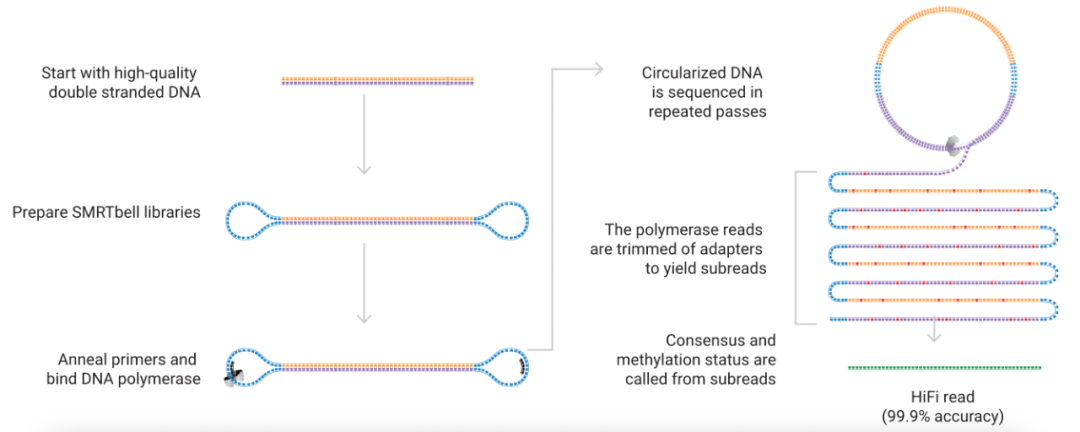
高错误率常被认为是三代测序技术的主要特征之一。不够准确的长读长测序,就像锋利而命中率不高的飞镖,破空而去,却射不中目标,不免令人失望。 然而近几年,情况似乎发生了变化。三代测序准确率有了明显的提升。它在科研界似乎从幕后走向台前,应用实例变多了,受到的关注也日渐增多。这其中发生了什么? > HiFi测序的诞生:一遍读不准,那就多读几遍咯 HiFi测序由PacBio公司开发,意思是High-Fidelity(高保真)测序。你可以认为是SMRT测序技术的进阶版。它兼具长读长和高准确率,也是目前正在推广和应用的、最具代表性的版本。 准确率之所以提升,主要是因为它采取了一种被称作Circular Consensus Sequencing (CCS)的测序模式。有人将CCS翻译为“环化共有序列”,听起来很唬人,但如果把两个词拆开来理解可就容易多了。 首先是Circular。在HiFi测序流程中,样品先被打断为一定长度的双链DNA分子(>10 kb)后,然后其两端被接上发卡结构的接头序列(Hairpin adapters)。两条链接续起来,构成哑铃形状,如下图所示。把它展开以后就是一个由DNA正链、反链和接头序列组成的环状分子。由此构建的文库叫做SMRTbell Library。
与Illumina和其他二代测序技术相似,SMRT测序过程是边合成边测序(Sequencing by synthesis),也就是说,以待测DNA为模板进行DNA复制,在合成新链的同时,通过检测新捕捉的核苷酸来确定DNA序列。HiFi测序的模板就是上述带有发卡接头的、环化了的DNA分子。由于两条链已经连接起来,DNA复制过程不存在断点,聚合酶能够在这个环状模板上跑完一遍又一遍,进行周而复始的滚环复制。这是CCS测序模式得以实现的基础。
SMRT测序技术本身的准确率不高,DNA聚合酶在环状模板上跑一次测得的序列准确率通常在90%以下。但由于测序错误的产生是随机的,这种错误可以用一个极其简单直接的方法来矫正,那就是:多跑几遍。 就好像是你有一群不聪明但很认真的孩子,你无法直接阅读一本书,而只能通过他们来间接获取关于这本书的信息。他们会向你逐字逐句地转述书的内容,但每个人都可能随机地在10-15%的字词上出错。 于是,通过比对、得到一致性序列,可以得到高准确率的测序结果。相当于让这些孩子围坐在一起讨论,所达成的共识(Consensus)部分,就可以认为是准确的。因为所有孩子在同一字词上犯错的概率极小。 如下图所示,当你有5个“孩子”,能够实现Q20(99%)以上的准确率,而当你有10个“孩子”,即在环状模板上跑10次(10 passes),准确率就能达到Q30(99.9%)。
听起来简单粗暴、量大管饱,但实现起来没那么容易。前文所说的,发卡接头将两条链接续起来后DNA连续复制是理想状况,实际上,导至DNA复制过程的中断另有其他因素,比如样品DNA本身。DNA的损伤会让聚合酶在复制中途脱落,从而使测序过程中断。因此,CCS测序模式非常依赖于样品DNA质量。需要预先筛选出高质量DNA分子,最大程度地减少受损DNA的比例,才能有效地实现高准确率测序。 另外,pass次数不可能是无限的,测序准确率的提升也是有天花板的。在环状模板上周而复始地复制,对于DNA聚合酶来说是连轴转的苦力活。它很容易就过劳死了,不可能在那个环上工作到天荒地老。 > 纳米孔测序的进阶:工欲善其事,必先利其器 与PacBio HiFi测序的“电梯直达”式的进阶之路不同,ONT提高纳米孔测序准确率的道路要显得曲折一些,更像是阶梯式的螺旋上升。 在发展纳米孔测序技术的早期阶段,ONT也曾采取与CCS相似的方法。他们也在样品DNA上连接发卡接头,只不过是其中的一端,而不是两端。这样将两条链串联起来以后,马达蛋白先牵引模板链通过纳米孔,发卡接头和另一条互补链紧随其后,从而一次完成两条链的测序,相当于对一条序列正着测又反着测,测了两次,因此ONT称之为2D模式。读取的序列则被称作2D read。对某种特定的纳米孔而言,例如ONT的R9.4纳米孔,2D模式下的测序准确率从原先1D模式下的86%提升到94%。 继2D模式后,ONT于2017年推出了1D2测序方法。他们为DNA分子的两条链分别接上一种特殊的接头,该接头大概率能使互补链和模板链被同一个纳米孔所捕获,但不能确保这一事件的发生(概率>60%)。
但由于两种测序技术在测序原理和过程上存在本质的不同,CCS策略在PacBio的SMRT测序中一路高歌的盛况,却在纳米孔测序中难以复现。纳米孔测序为边解旋边测序(不是边合成边测序),一经解旋便无法恢复,所以是一过性的,不支持反复跑、反复测。另外,核苷酸链一旦通过纳米孔,以目前的技术,应该是没法让同一条链反向再次通过同一纳米孔。所以HiFi测序中5个pass、10个pass对于Nanopore测序来说几乎不可能实现。 对纳米孔测序而言,纳米孔本身与马达蛋白的优化,可能才是属于它的康庄大道。 ONT从未停止过改进纳米孔和马达蛋白的步伐。2014年的R7纳米孔测序准确率仅为64%左右,而2016年推出的R9纳米孔一下子把准确率提升至~87%。根据ONT官网提供的数据,R10.4.1在特定的测序条件下,可以达到99.9%以上的准确率。 事实上,获取共有序列(Consensus sequence),即对同一序列的多个拷贝进行测序,或者对同一序列多次测序,是消除随机误差的常见方法。采取此方法的测序准确率也被称作Consensus accuracy。除了HiFi测序的CCS模式以外,还可以通过扩增样品DNA、提高测序深度、算法矫正等方式来提高准确率。ONT纳米孔测序的最新版本R10.4.1,其Consensus accuracy据说可以达到99.999%(10-20x测序深度)。 在2021年发表于Nature Methods上的一篇文章中,作者将一种早已用在单细胞转录组测序研究中的独特分子标志符(Unique molecular identifier, UMI)与三代测序技术结合。UMI是一串随机的寡核苷酸序列,每一条UMI都独一无一。它被嵌入到模板DNA时,则成为一种分子标签。可以认为它是DNA分子的“身份证”。通过识别这串随机字符,能够识别扩增后的DNA分子来源于哪一条模板DNA。考虑到三代测序错误率高的特点,作者采取了特殊的UMI设计,并通过数据过滤,有效地提高了UMI识别能力,从而把ONT纳米孔测序的错误率降低到了0.0042%(R10.3),把PacBio的HiFi测序错误率降低到了0.0007%。 不过,在测序前先对模板DNA进行扩增的做法,似乎没有让三代测序技术发挥它单分子测序的优势。现在的三代测序技术稳中求进,但好像缺乏一种颠覆性的创新,或者一股磅礴的能量,让它彻底沸腾起来。否则仅有长读长这一项优势,相关的数据处理软件也尚未成熟,它将很难超越或者替代二代测序。 至于技术,从来都没有什么秘密,无非是千万次地优化,不断地改进罢了。
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号