金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
PD分离是很复杂的分布式系统方案,需要考虑的东西很多,我们先可以回顾PD分离的目的
- TTFT和TPOT是两个原理上截然不同的性能指标,且都非常重要,现有的chunked prefill方法很难同时优化好这两个目标。
- Prefill和Decode对硬件的要求有很大不同,Prefill需要计算能力强,Decode需要显存大,分开优化可以更好地利用不同的硬件,比如不同的GPU型号。
- PD分离能解耦kv cache的管理,使得框架本身无需支持复杂的kv cache多硬件层次管理。
PD分离首先带来的就是kv cache的传输问题,通过GPU RDMA的方式能有效降低通信量,但是如果P一次性传输几个G的kv cache,对网络是个很大的挑战,也没法做到很好的计算和通信重叠,因此layerwise kv transfer就是PD分离的基本要求。
在知乎上参考了几位大佬关于PD分离的文章,感觉以小白的角度还是用SGLang更方便去理解PD分离的实现,所以本文基于SGLang v0.4.6做一些PD分离的研究实践。
参考SGLang的设计目标

- 可扩展的成对prefill和decode服务器连接
- 非阻塞kv transfer
- 动态TP并行
- RDMA支持
SGLang的PD分离是一个Producer-Consumer模式,使用多个queue实现非阻塞式的kv transfer,具体可以参考 @kaiyuan大佬的这篇文章kaiyuan:vLLM PD分离方案浅析。
SGLang实现了两种KV connector后端,Mooncake和NIXL,每个connector有四个角色
| KVBootstrap | 只用于prefill,记录prefill和decode交互所用的信息,可以有很多种,decode会请求该信息和prefill进行连接 | | KVManager | 负责初始化内存、Bootstrap server以及发送kv cache,prefill和decode都有,作为KV connector的管理器 | | KVSender | 专属于prefill,发送kv cache | | KVReceiver | 专属于decode,和prefill握手,获取bootstrap server的交互信息,接收kv cache |
Prefill Node和Decode Node是如何建立连接
创建TokenizerManager时,prefill会初始化KVBootstrap
# srt/managers/tokenizer_manager.py
class TokenizerManager:
"""TokenizerManager is a process that tokenizes the text."""
def __init__(
self,
server_args: ServerArgs,
port_args: PortArgs,
):
...
# for disaggregtion, start kv boostrap server on prefill
if self.disaggregation_mode == DisaggregationMode.PREFILL:
# only start bootstrap server on prefill tm
kv_bootstrap_server_class = get_kv_class(
self.transfer_backend, KVClassType.BOOTSTRAP_SERVER
)
self.bootstrap_server = kv_bootstrap_server_class(
self.server_args.disaggregation_bootstrap_port
)KVBootstrap启动一个server,提供两个接口,/metadata负责存储一些meta信息,/route负责传递prefill的ip和port等信息。
Prefill在BootstrapQueue初始化KVManager,Manager会启动一个socket监听来自decode的传输请求,并且将自己的信息通过/route注册到bootstrap server上。Decode在PreallocQueue初始化KVManager。
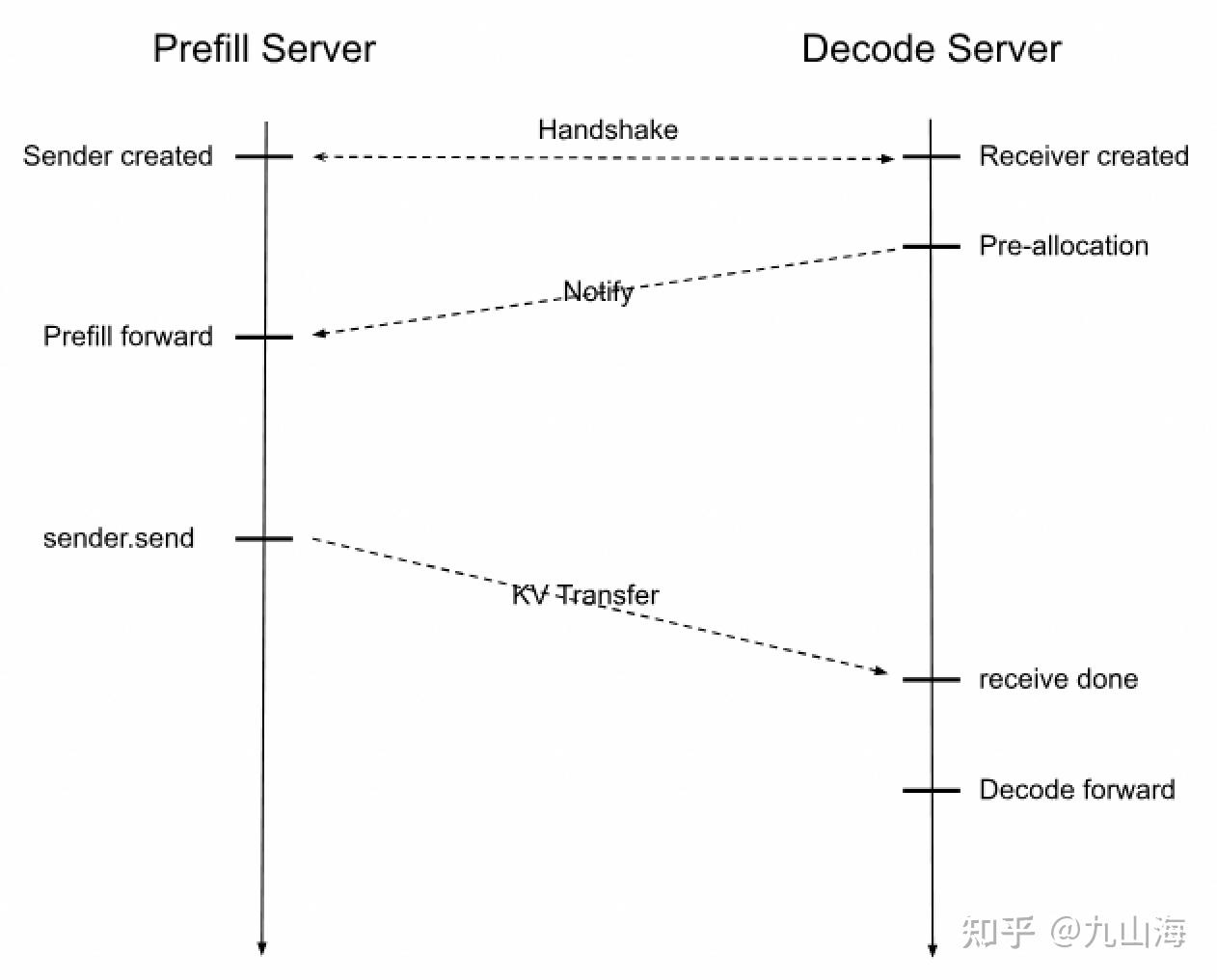
我们以Mooncake KV connector的视角理解上面sglang给出的prefill和decode的整个传输过程
- prefill和decode分别会创建KV manager对象,prefill和decode都会在manager内启动tcp server,prefill会额外将自己的端口传给bootstrap server保存,这个过程就是“handshake”。prefill会额外启动一个transfer线程来异步地传输kv cache。
- 在manger中,prefill和decode同时也会各自启动一个线程,prefill监听来自decode的pre-allocated信号,得到一些信息,然后将自身状态设置成WaitingForInput;decode监听来自prefill的两个信息:room id和status。
- 在scheduler中,对每个req,会生成一个随机room id用来在KV manager内唯一标识一对prefill和decode,prefill和decode分别会创建一个KV sender和KV receiver与req绑定,KV receiver会从bootstrap server中得到prefill的ip和port。
- 然后在prefill和decode各自的event_loop中
- 对于prefill,调用BootstrapQueue的pop_bootstrapped,获取每个req的status,只有status为WaitingForInput的req才会初始化KV sender,并将req移动到WaitingQueue。
- 对于decode,先调用PreallocQueue的pop_preallocated,预分配KV cache,初始化KV receiver,其初始化过程为,向prefill的监听线程发送五个信息:room id、decode的ip和port、Mooncake engine的session id、预分配的kv cache的虚拟地址、first token的输出位置(ReqToMetadataIdxAllocator生成)。prefill的manager收到之后记录这些信息然后将自己的状态变更为WaitingForInput,这一步就是“notify”。然后将req移动到TransferQueue中。
- 前面我们提到在KV manager中,decode也会监听prefill,这个监听其实就是等待prefill完成KV transfer。何时完成KV transfer?sglang考虑了chunked prefill,每运行完一次chunk,prefill的scheduler会调用send_kv_chunk,内部调用KV sender将kv cache的虚拟地址和在mooncake的物理地址传给decode,具体传法是:并行地传每layer的KV cache。到了最后一个chunk,sender会额外发送一些辅助数据,并且将room id和status(状态是Success)发送给decode的监听线程。这一步就是“KV Transfer”。
以上就是SGLang大概的Prefill和Decode的交互过程,全部的实现非常复杂。SGLang的PD分离实现是一个简单的方案,decode等待prefill完成,prefill内部做prefix caching。
我们接下来重点看看以mooncake为视角,kv cache的管理与传输,这些都是可以独立于框架之外理解,通过SGLang我们也可以更好地了解mooncake的设计。
初始化阶段,prefill和decode在KVManager都需要初始化一个Mooncake engine
class MooncakeTransferEngine:
def __init__(self, hostname: str, gpu_id: int, ib_device: Optional[str] = None):
try:
from mooncake.engine import TransferEngine
except ImportError as e:
raise ImportError(
"Please install mooncake by following the instructions at "
"https://github.com/kvcache-ai/Mooncake/blob/main/doc/en/build.md " # noqa: E501
"to run SGLang with MooncakeTransferEngine."
) from e
self.engine = TransferEngine()
self.hostname = hostname
self.gpu_id = gpu_id
# 可以在外指定infiniband设备,不指定mooncake会自动检测
self.ib_device = ib_device
self.initialize(
hostname=self.hostname,
device_name=self.ib_device,
)
self.session_id = f"{self.hostname}:{self.engine.get_rpc_port()}"
def initialize(
self,
hostname: str,
device_name: Optional[str],
) -> None:
"""Initialize the mooncake instance."""
# 四个参数分别为
# ip
# metadata server地址,可以是etcd,P2PHANDSHAKE代表使用socket进行握手
# Transport的数据传输方式,rdma/tcp/nvmeof
# infiniband设备名
ret_value = self.engine.initialize(
hostname,
"P2PHANDSHAKE",
"rdma",
device_name if device_name is not None else "",
)
if ret_value != 0:
logger.error("Mooncake Transfer Engine initialization failed.")
raise RuntimeError("Mooncake Transfer Engine initialization failed.")infiniband device指的是nvidia的infiniband网卡,参考NVIDIA InfiniBand 网卡,支持GPUDirect RDMA。
mooncake的transfer engine的初始化:其一创建TransferMeta,用于管理mooncake的所有元数据,包含两个plugin
- 基于rpc的handshake socket。
- metadata storage管理plugin,元数据存储,可以是etcd、redis或者http,本地一般用redis即可。
其二创建MultiTransport,实现Mooncake的数据传输功能,支持tcp、rdma及nvmeof。
我们结合SGLang的源代码看,在初始化KVManager时,sglang会把已经分配的kv cache地址信息以及metadata的地址信息注册到Transfer Engine里,这一步prefill和decode的逻辑是一致的。
class PrefillBootstrapQueue:
def _init_kv_manager(self) -> BaseKVManager:
kv_args = KVArgs()
kv_args.engine_rank = self.tp_rank
# 格式为N层K的地址+N层V地地址
# KV_item存的是单个K和V page的字节数
kv_data_ptrs, kv_data_lens, kv_item_lens = (
self.token_to_kv_pool.get_contiguous_buf_infos()
)
kv_args.kv_data_ptrs = kv_data_ptrs
kv_args.kv_data_lens = kv_data_lens
kv_args.kv_item_lens = kv_item_lens
# Define req -> input ids buffer
kv_args.aux_data_ptrs = [
metadata_buffer.data_ptr() for metadata_buffer in self.metadata_buffers
]
kv_args.aux_data_lens = [
metadata_buffer.nbytes for metadata_buffer in self.metadata_buffers
]
kv_args.aux_item_lens = [
metadata_buffer[0].nbytes for metadata_buffer in self.metadata_buffers
]
kv_args.ib_device = self.scheduler.server_args.disaggregation_ib_device
kv_args.gpu_id = self.scheduler.gpu_id
kv_manager_class = get_kv_class(self.transfer_backend, KVClassType.MANAGER)
kv_manager = kv_manager_class(
kv_args, DisaggregationMode.PREFILL, self.scheduler.server_args
)
return kv_manager
class MooncakeKVManager(BaseKVManager):
def register_buffer_to_engine(self):
for kv_data_ptr, kv_data_len in zip(
self.kv_args.kv_data_ptrs, self.kv_args.kv_data_lens
):
# 逐层注册memory,先注册所有K,再注册所有V
self.engine.register(kv_data_ptr, kv_data_len)
for aux_data_ptr, aux_data_len in zip(
self.kv_args.aux_data_ptrs, self.kv_args.aux_data_lens
):
self.engine.register(aux_data_ptr, aux_data_len)Transfer Engine调用的是Transport的注册方法,如果使用RDMA,则是将KV cache的物理地址和infiniband设备做一个映射。我们前面提到KV sender会并行地发送每层的KV cache,在prefill forward出一个chunk之后,调用KV sender的send方法将kv_indices发送给prefill的transfer thread,kv_indices的定义为
kv_indices = (
self.req_to_token_pool.req_to_token[req.req_pool_idx, start_idx:end_idx]
.cpu()
.numpy()
)得到的是虚拟地址,即在物理地址上的索引,transfer thread调用send_kvcache,需要三个信息:kv chunk在prefill的虚拟地址、在decode上全局的kv物理地址、在decode上kv cache物理地址上的索引
ret = self.send_kvcache(
req.mooncake_session_id,
kv_chunk.prefill_kv_indices,
self.decode_kv_args_table[req.mooncake_session_id].dst_kv_ptrs,
chunked_dst_kv_indice,
)send_kvcache会将prefill_kv_indices和dst_kv_indices做一个连续内存的聚类,连续的内存地址一次性发送
比如prefill_kv_indices=[1,2,3,5,6],dst_kv_indices=[2,3,4,7,8],则发送就是
transfer_sync(src=[1,2,3], dst=[2,3,4])和transfer_sync(src=[5,6], dst=[7,8])每chunk prefill跑完一次性发送所有层的kv cache。前面提到在prefill最后一个chunk完成后,transfer engine还会发送一些辅助信息,这个辅助信就是prefill的第一个token id,decode收到后将其初始化到decode batch的output_ids结果里面
# sglang/srt/disaggregation/decode.py
def process_prebuilt_extend(
self: ScheduleBatch, server_args: ServerArgs, model_config: ModelConfig
):
"""Assign the buffered last input id to schedule batch"""
self.output_ids = []
for req in self.reqs:
if req.output_ids and len(req.output_ids) > 0:
# resumed retracted req
self.output_ids.append(req.output_ids[-1])
else:
assert req.transferred_output_id is not None
req.output_ids.append(req.transferred_output_id)
self.output_ids.append(req.transferred_output_id)
self.tree_cache.cache_unfinished_req(req)
self.output_ids = torch.tensor(self.output_ids, device=self.device)总结来看,SGLang给出了一个标准的PD分离方案实现,prefill得到所有层的kv cache,然后一次性发送给decode,prefill的第一个token不会直接返回给proxy,而是交给decode继续处理。对于KV cache的存储,其实也是交给prefill和decode自己,尚未利用mooncake的store,也就是P2P的KV cache存储方案。
一口吃不成胖子,从SGLang的实现我们可以理解一个基本的PD分离方案是如何实现出来的。
Benchmark
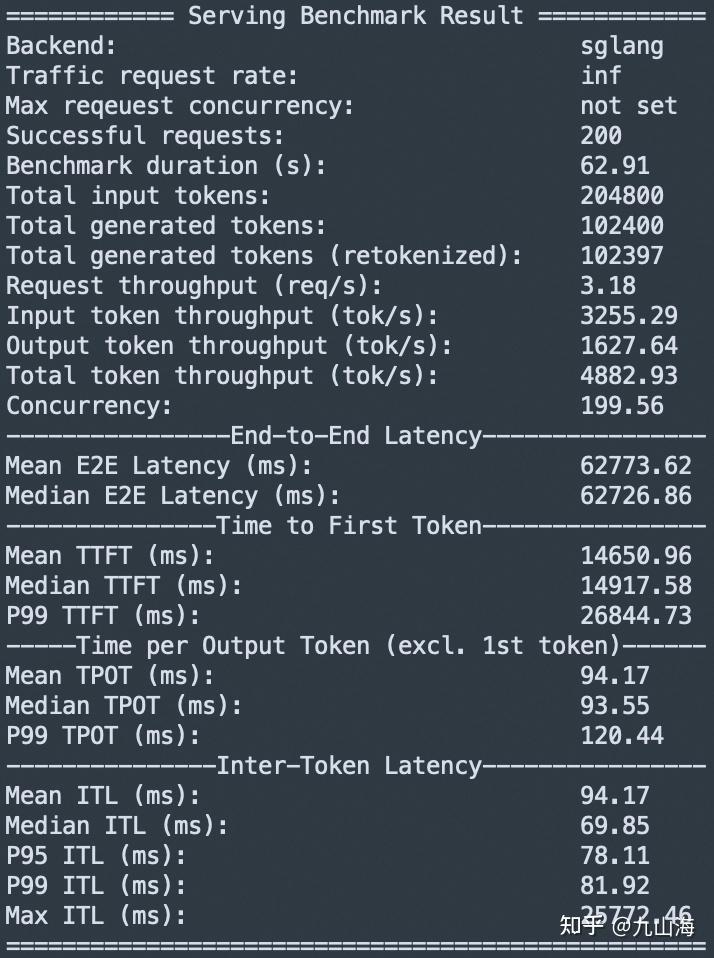
我们比较一下,一个简单的PD分离方案能否带来收益。
我们使用Qwen3-32B在4xH20上测试,因为SGLang默认的chunked_prefill_size在H20上是8192,测试长度不超过8192,所以prefill只会发送一次。
# sglang no-disagg
python -m sglang.launch_server --model Qwen/Qwen3-32B --tp-size 4 --attention-backend fa3 --enable-torch-compile
# benchmark command
python -m sglang.bench_serving --backend <vllm|sglang> --dataset-name random --random-range-ratio 1 --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split/ShareGPT_V3_unfiltered_cleaned_split.json --random-input-len 1024 --random-output-len 512 --num-prompts 200
1P1D,分别使用2个GPU,后端是mooncake
# Prefill
python -m sglang.launch_server --model Qwen/Qwen3-32B --attention-backend fa3 --enable-torch-compile --disaggregation-mode prefill --port 30000 --host 127.0.0.1 --tp-size 2
# Decode
python -m sglang.launch_server --model Qwen/Qwen3-32B --attention-backend fa3 --enable-torch-compile --disaggregation-mode decode --port 30001 --base-gpu-id 2 --host 127.0.0.1 --tp-siz
e 2
# Proxy,这个Proxy没有多少功能,就是提供一个统一的接口
python -m sglang.srt.disaggregation.mini_lb --prefill http://127.0.0.1:30000 --decode http://127.0.0.1:30001 --host 0.0.0.0 --port 8000
# Benchmark
python -m sglang.bench_serving --backend sglang --dataset-name random --random-range-ratio 1 --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split/ShareGPT_V3_unfiltered_cleaned_split.json --random-input-len 1024 --random-output-len 512 --num-prompts 200
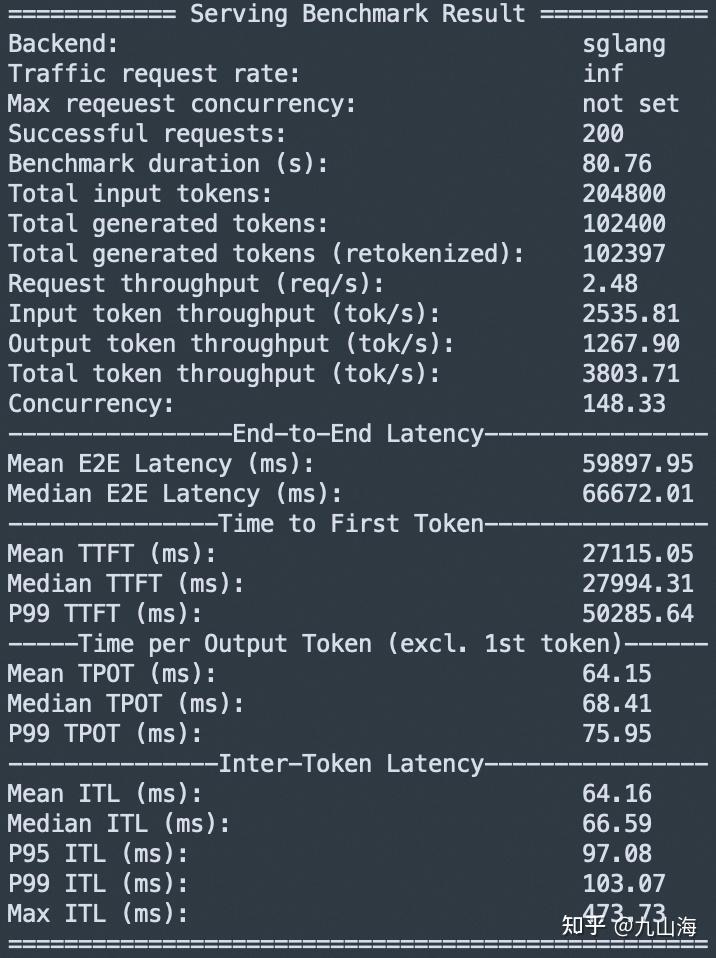
和Mooncake给出的benchmark Mooncake/docs/source/performance/sglang-benchmark-results-v1.md at main · kvcache-ai/Mooncake 类似,TTFT增加了一倍,TPOT减少了三分之一。
TTFT的计算是根据response的第一个token返回的时间算的,因为prefill在计算完之后直接发给了decode而不是Proxy,所以会加上传输数据的时间。
原文地址:https://zhuanlan.zhihu.com/p/1912106909617624371 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-6-4 17:33
发表于 2025-6-4 17:33
 提升卡
提升卡


