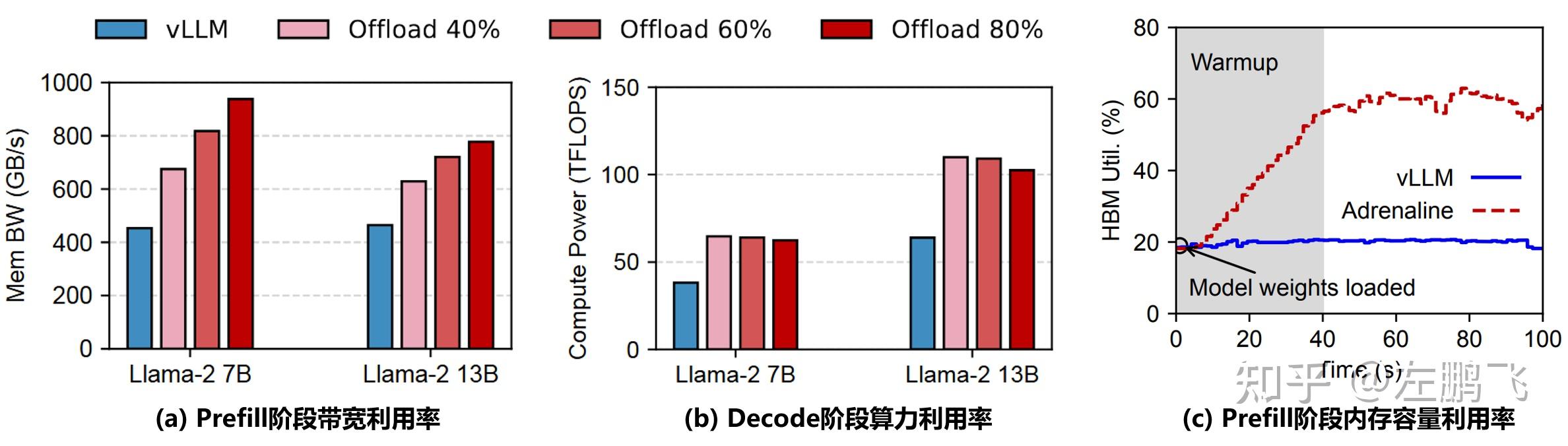
为了解决上述问题,我们提出Adrenaline,一种注意力分离和卸载机制,旨在提高LLM服务系统的资源利用率和性能。Adrenaline的核心思想是将Decode阶段的部分Attention计算任务分离并卸载到Prefill实例中。通过卸载这些内存密集型的Attention计算任务,Prefill实例的HBM容量和带宽利用率得到了提高。此外,这也使得Decode实例中的总批处理大小得以增加,从而提高了Decode实例的算力资源利用率 —— 一举两得。
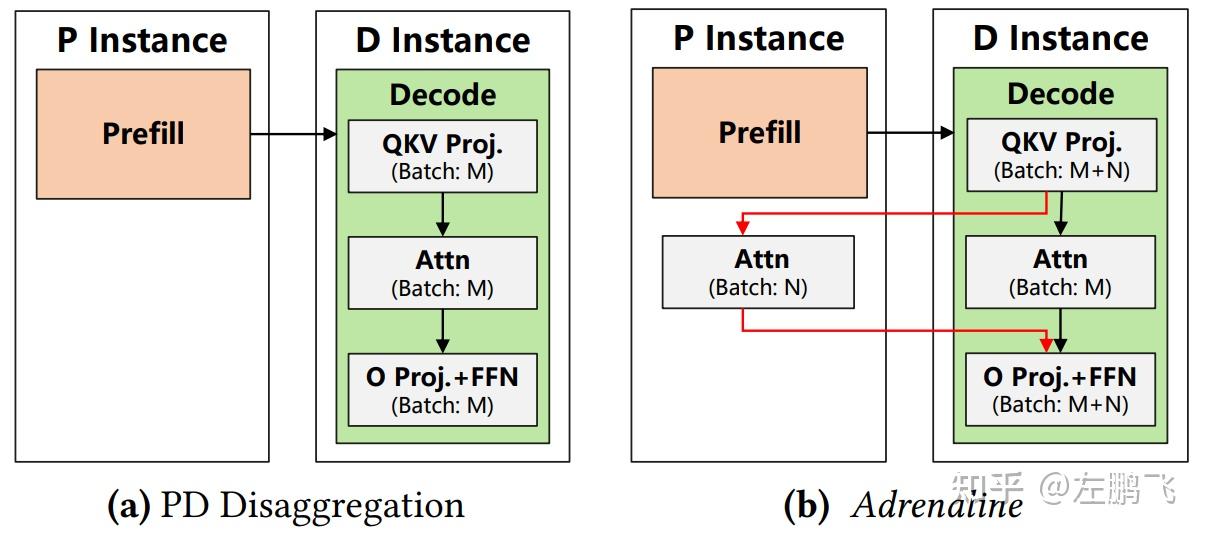
图3展示了传统PD分离和Adrenaline方案的区别。在图3a中的PD分离方案中,由于Decode实例上的HBM带宽和容量限制,Decode的批大小只能跑到 M。在图3b中的Adrenaline方案中,我们将 N 个Attention计算请求卸载到Prefill实例上执行,Decode的总批大小从 M 提升到 M+N,从而大幅提升了推理系统的整体吞吐量。
图3:传统PD分离和Adrenaline的方案对比
4 Adrenaline系统设计
4.1 Challenges
然而,在现在的PD分离推理系统中实现Adrenaline方案面临三个主要挑战。
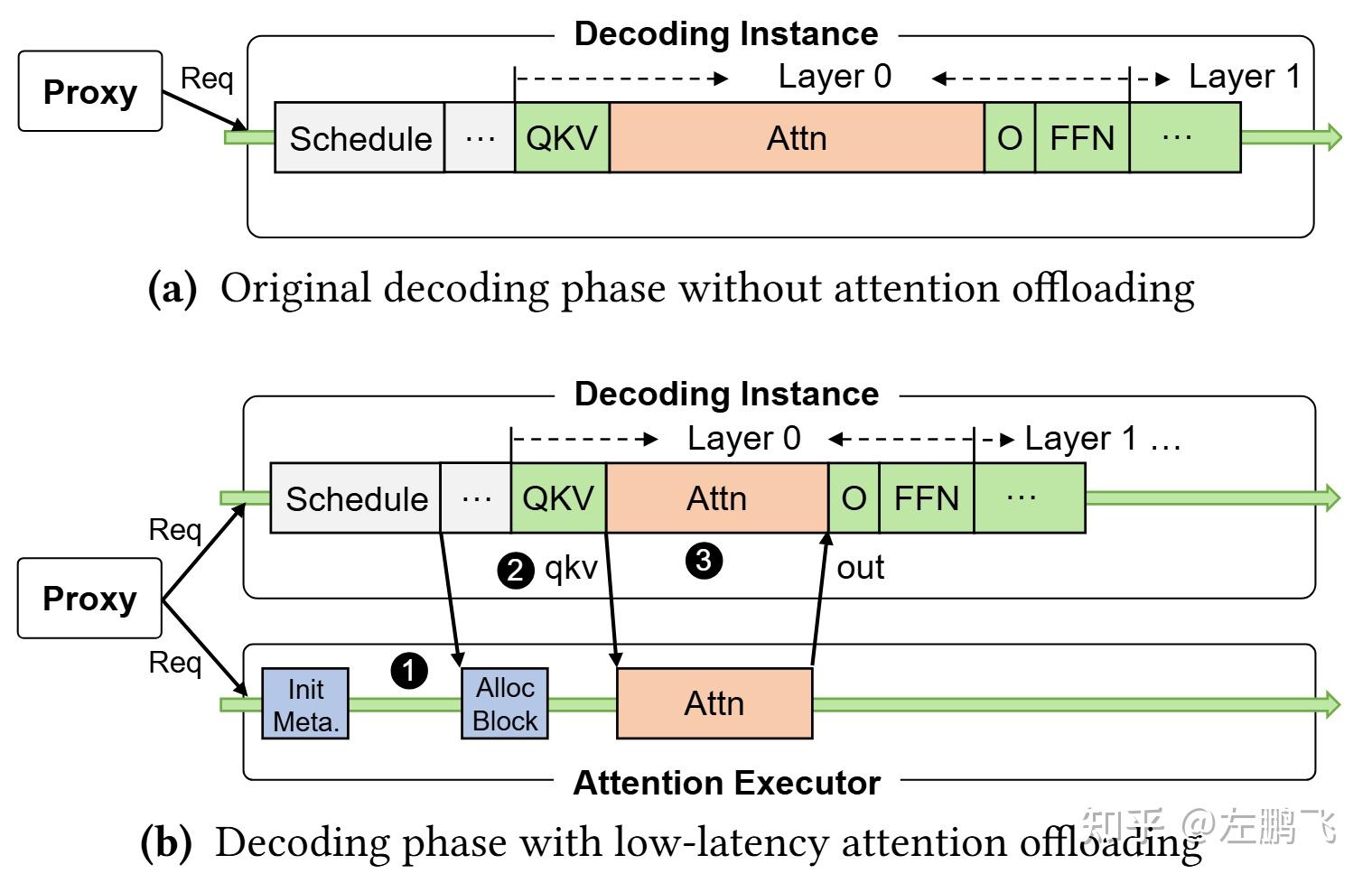
1. Decode阶段的Attention同步开销:卸载Attention会在Decode阶段的每个Transformer层中引入额外的同步步骤。如图3b所示,为了卸载Attention计算,Decode实例必须将输入参数(即qkv)发送到Prefill实例。一旦卸载的Attention计算完成,输出(即attn_out)必须发送回Decode实例进行下一步的处理。这些额外的步骤——发送qkv、执行卸载的Attention计算并接收输出——必须与Decode实例中的本地Attention计算完美重叠,才能不影响TPOT。
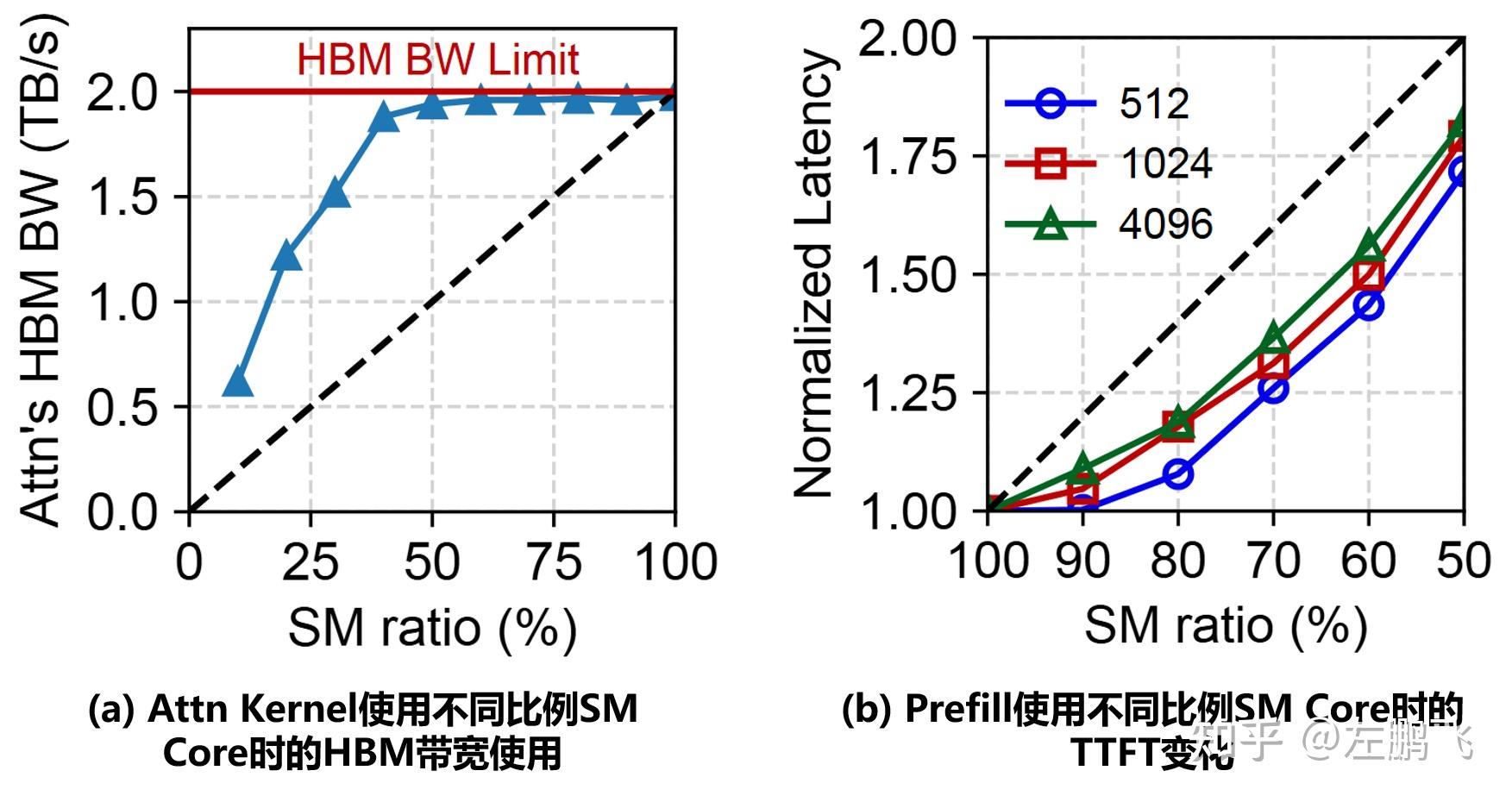
2. Prefill实例上的性能干扰:在Prefill实例上的同一张卡上,并行运行卸载的Attention计算任务和Prefill计算任务可能会导致资源竞争、运行调度等方面的干扰,而影响TTFT。
3. 准确地控制卸载率:准确控制要卸载的Attention计算任务的数量非常重要(也就是图3b中的N)。一个好的卸载比率必须平衡Prefill和Decode实例中的计算和内存资源利用率,如果卸载比率设置的不好反而会导致推理性能恶化。
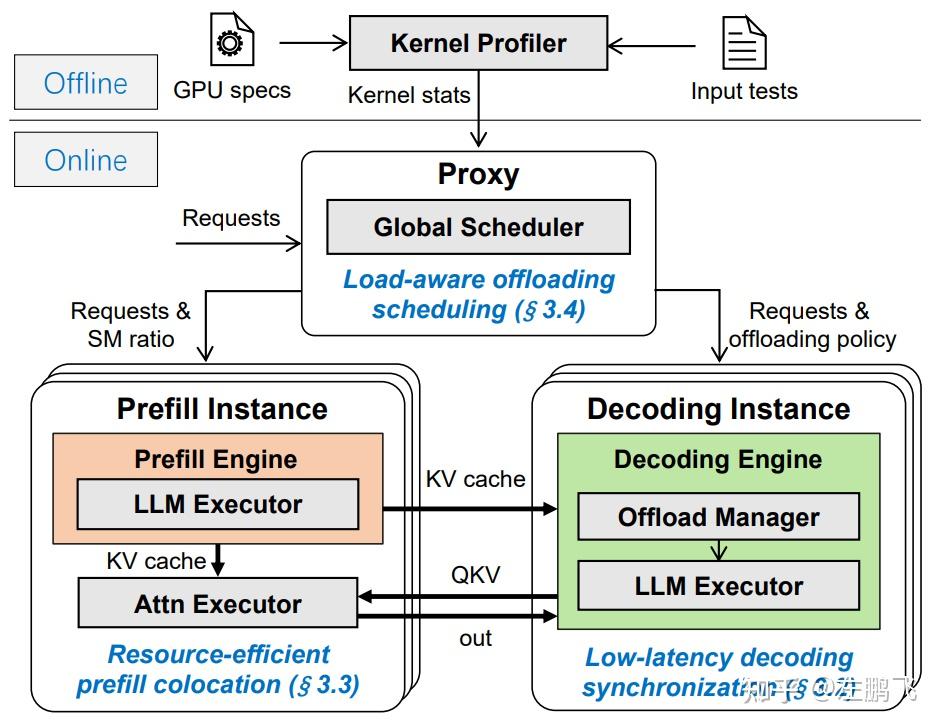
4.2 System Overview

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-3-29 13:23
发表于 2025-3-29 13:23



 提升卡
提升卡


