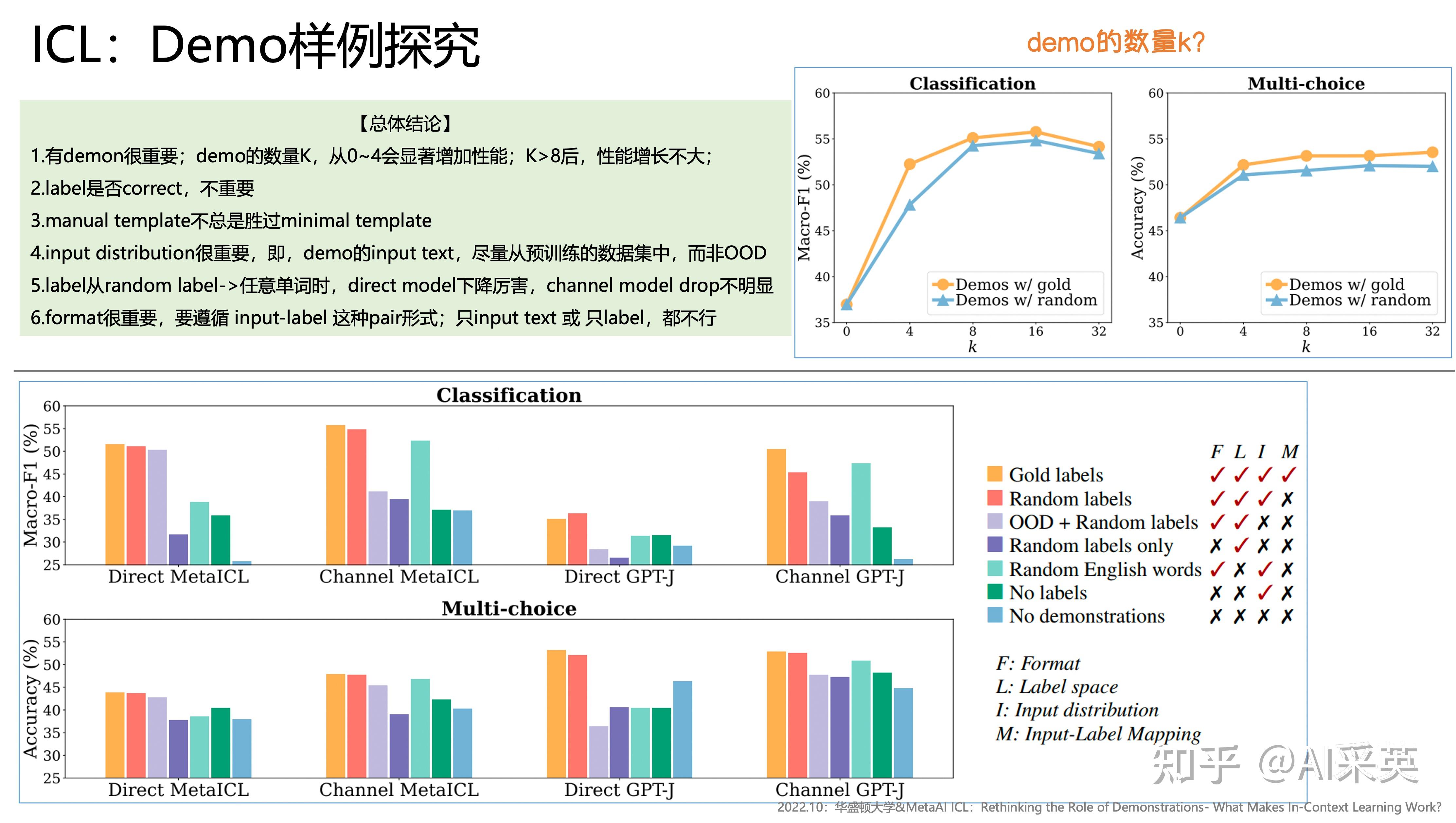
label从random label->任意单词时,direct model下降厉害,channel model drop不明显
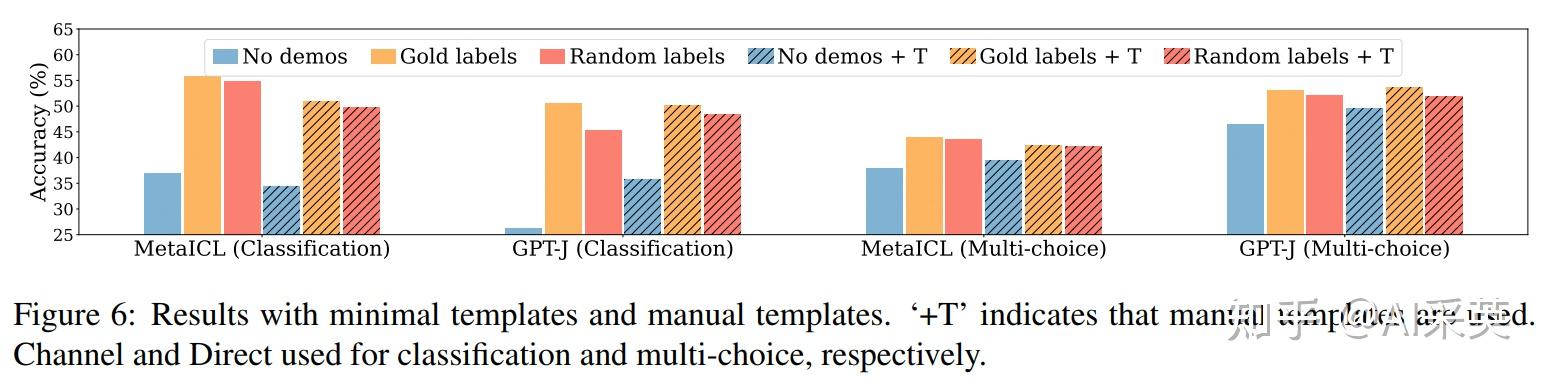
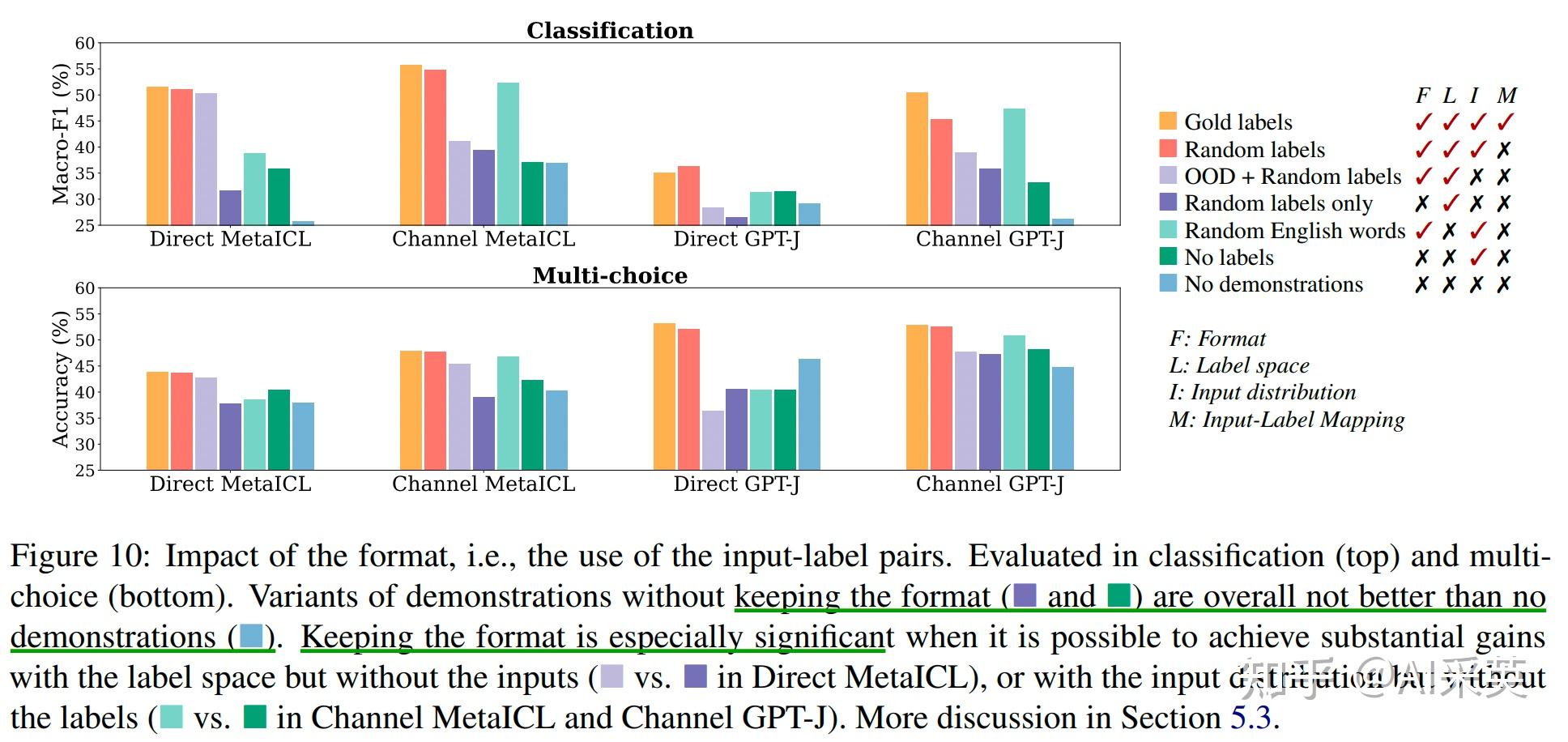
format很重要,要遵循 input-label 这种pair形式;只input text 或 只label,都不行
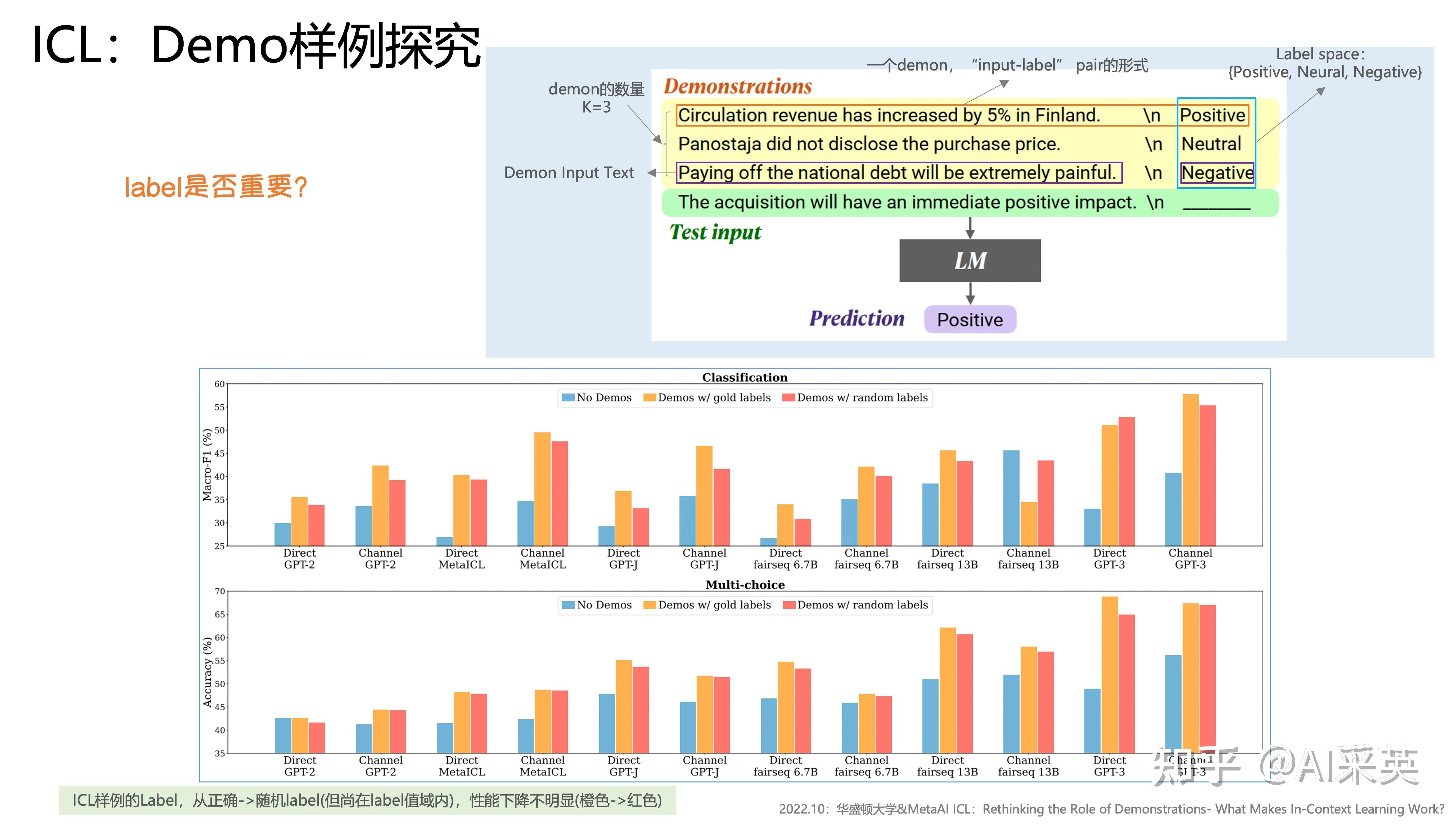
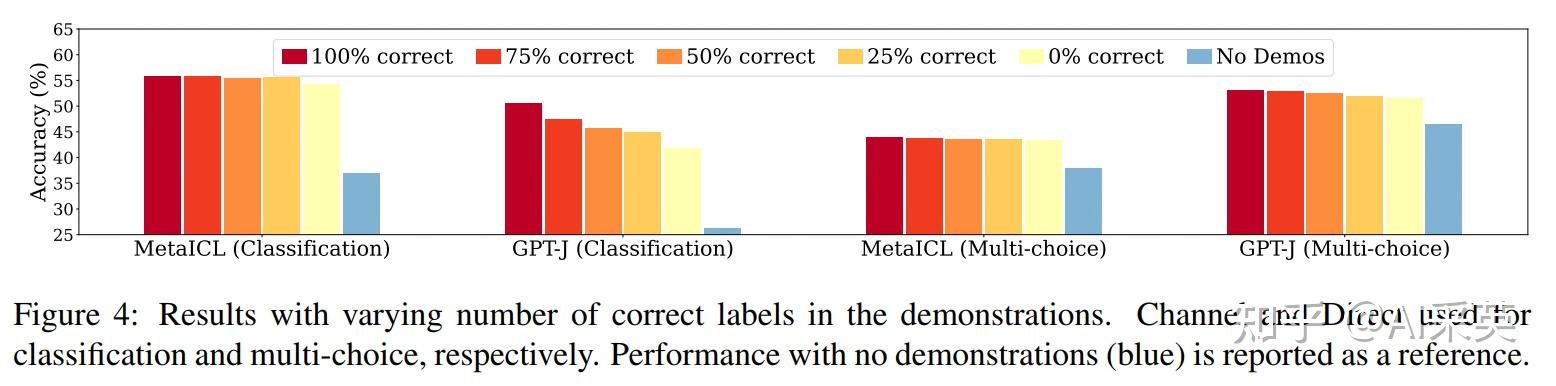
1)ground truth的demo不重要
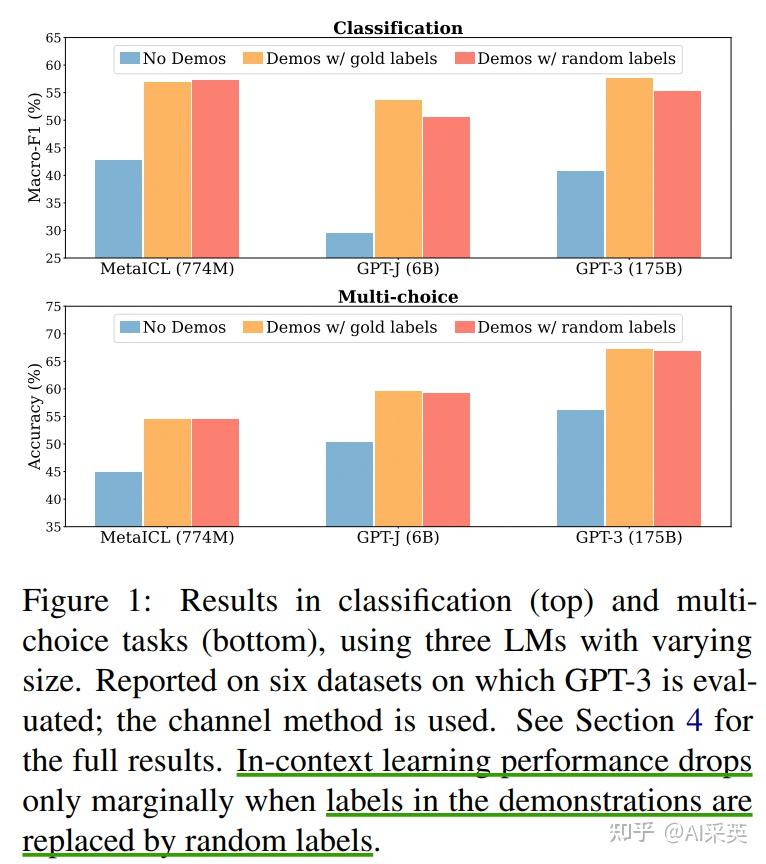
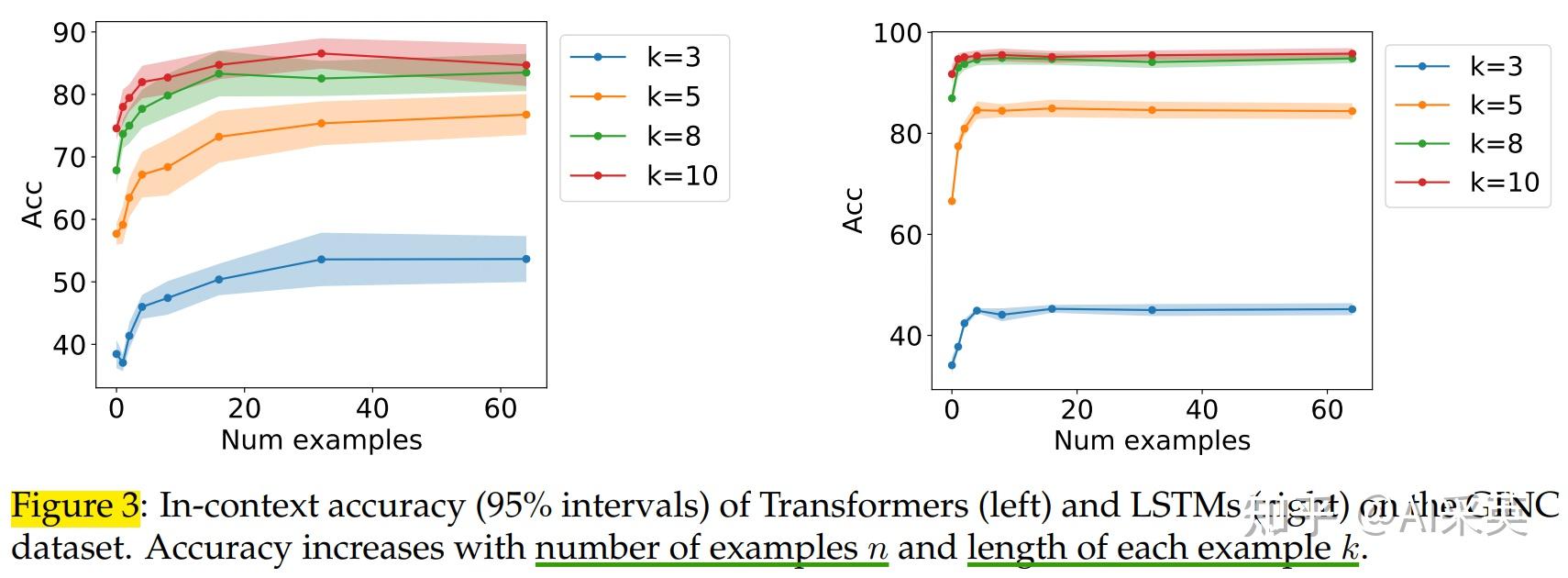
:ICL随着shot增多、规模增大,而逐渐变好;但,给demonstration错误/随机的label,性能下掉。
random label,基于不影响性能;
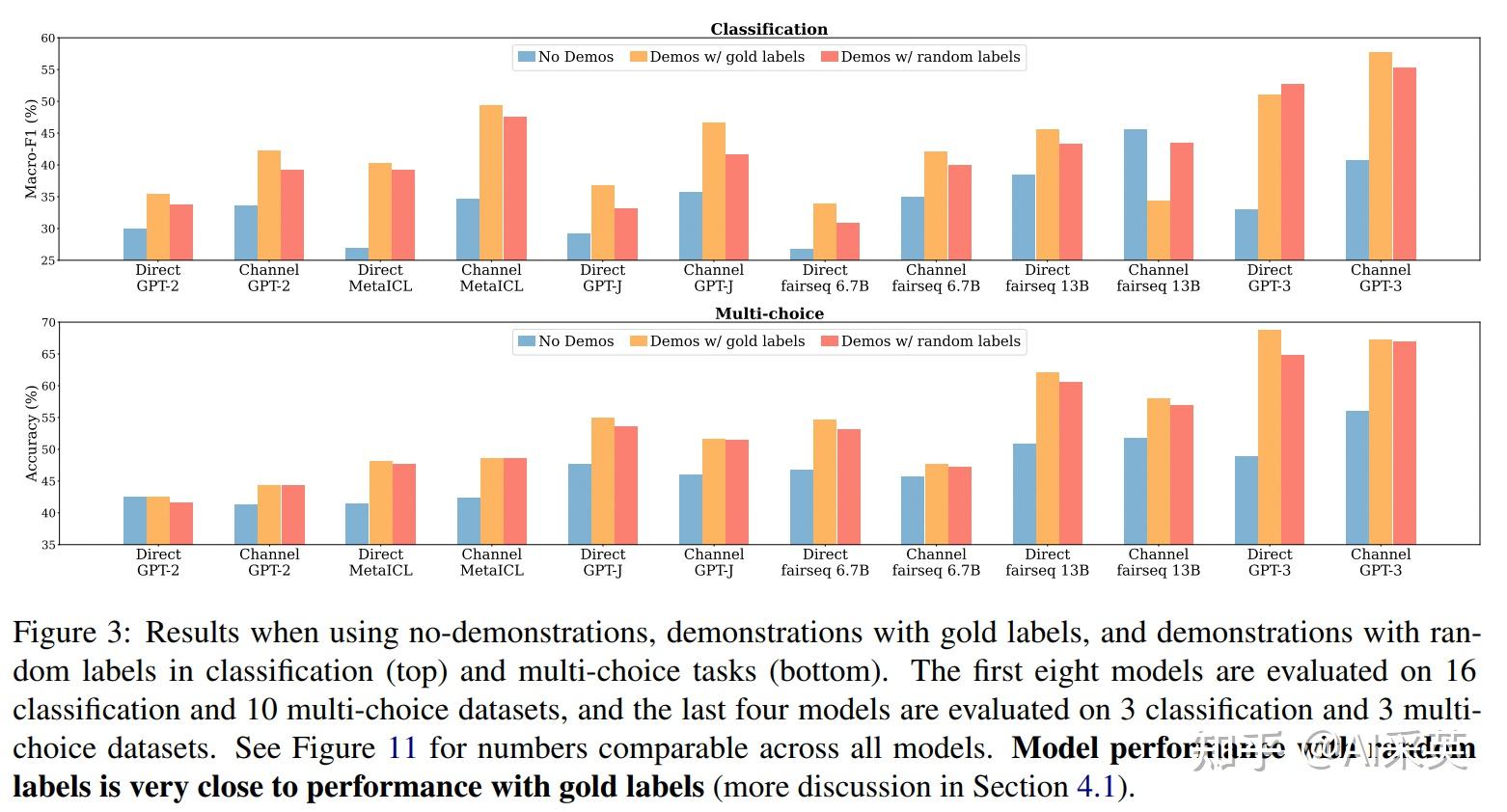
demonstrations with random labels barely hurts performance in a range of classification and multi-choice tasks。the model does not rely on the input-label mapping in the demonstrations to perform the task
我们发现:
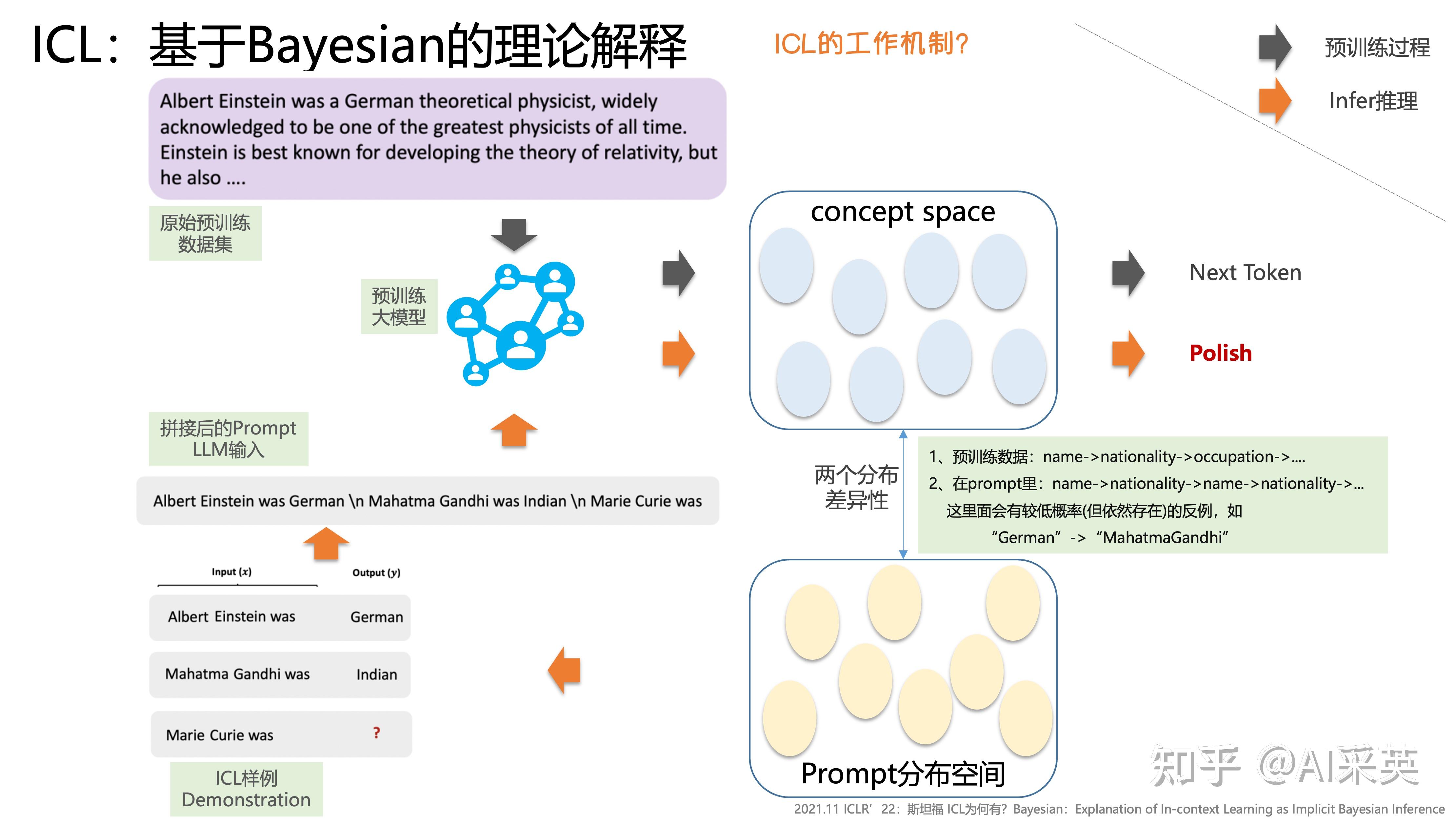
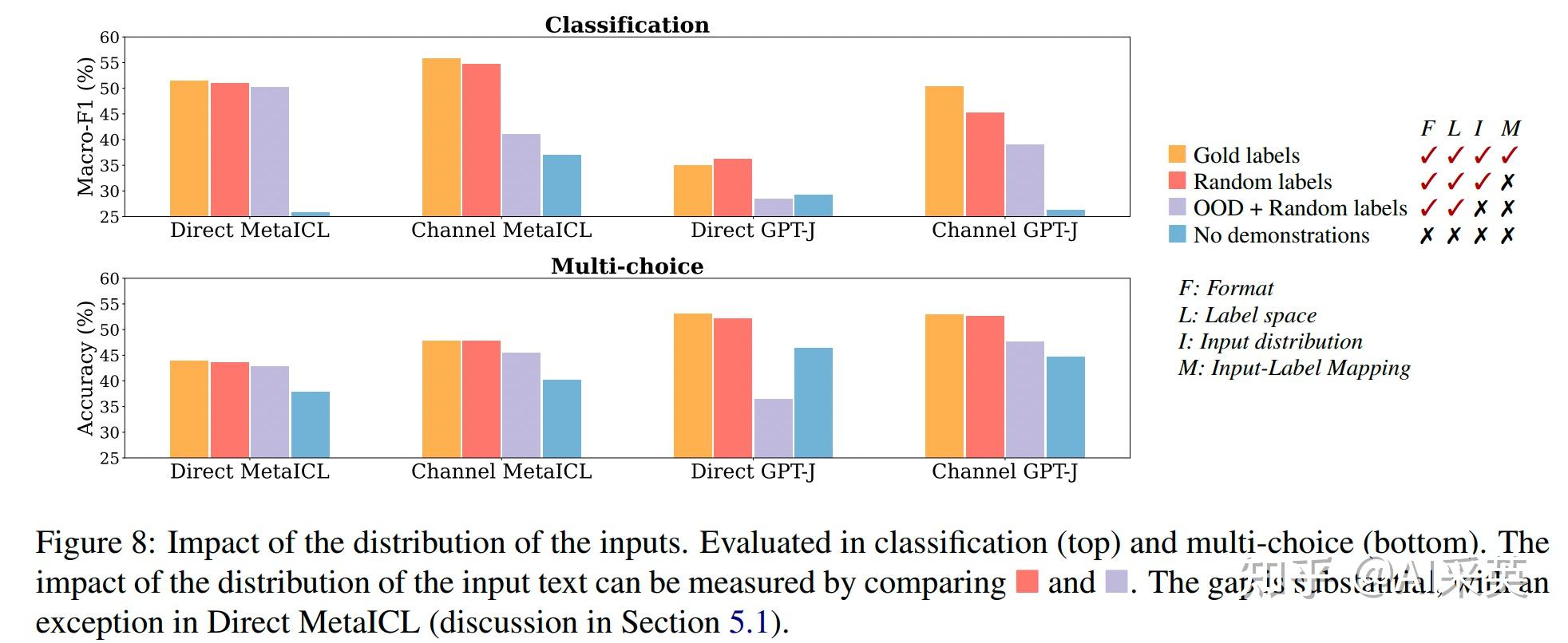
1、the label space and the distribution of the input text specified by the demonstrations are both key to in-context learning (regardless of whether the labels are correct for individual inputs);
:label space和input分布,是影响ICL效果的关键因素
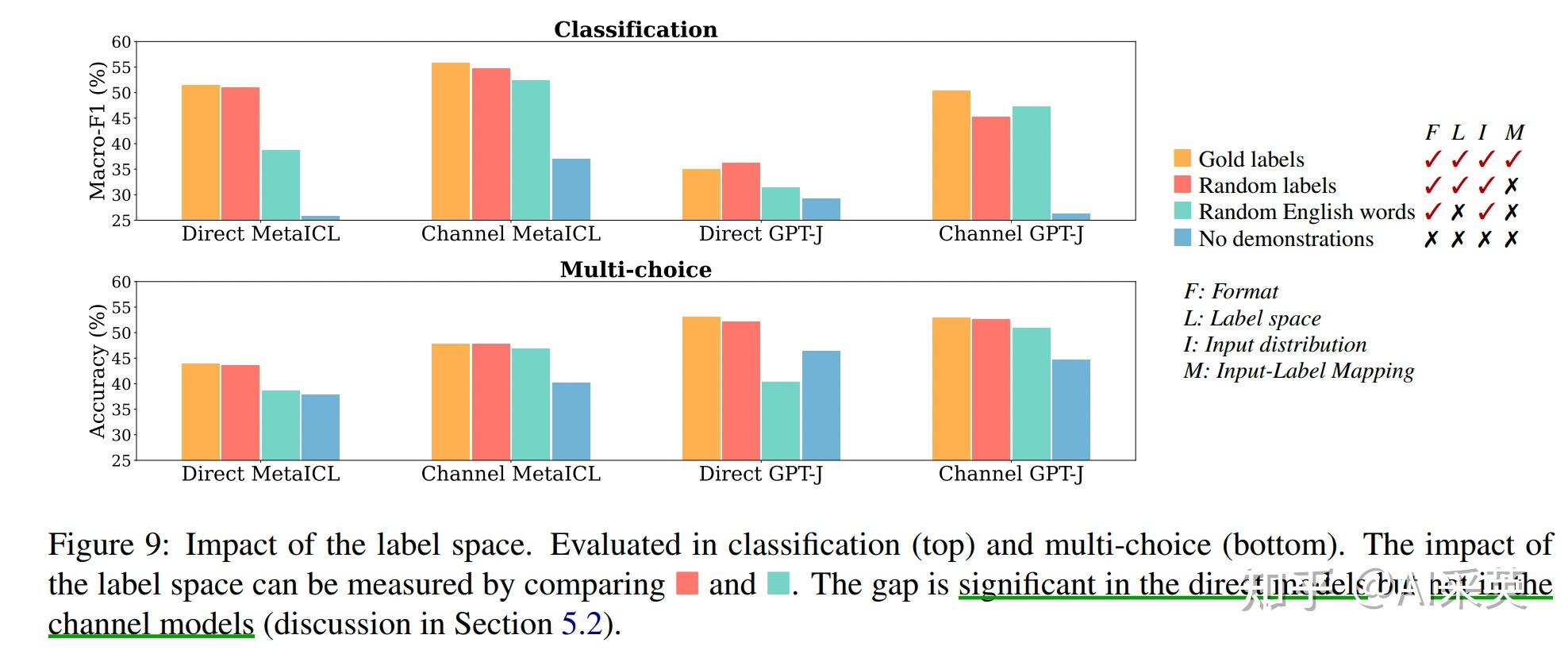
2、specifying the overall format is also crucial, e.g., when the label space is unknown, using random English words as labels is significantly better than using no labels;
:格式很重要;比如,一个样本,它的label是随机英文word,但依然好于没有label
3、meta-training with an in-context learning objective (Min et al., 2021b) magnifies these effects—the models almost exclusively exploit simpler aspects of the demonstrations like the format rather than the input-label mapping :重要结论
:使用demonstration比没有demon要好;label是random时,也无所谓,略差于gold label No Demos:LMs直接进行零样本预测,无提示 Demos w gold:依赖于K个标注的examples进行提示,进行预测 Demos w random labels:抽样K个examples提示,但样本labels在标签集中随机采样,而非groundtruth。
用random label替换gold label只会轻微影响性能(0-5%)。这一趋势在几乎所有的模型(700M->175B)上都是一致的
每 4 个一组的柱状图里(具体说明在右侧),中间两个(Random labels 和 OOD + Random labels)的对比区别就是 input distribution 不同。可见除了 Direct MetaICL 模型之外,其他模型下这两组 input distribution 带来的结果表现差异是很显著的。所以可以通过实验初步得出结论:input distribution 是有显著影响的。
This suggests that in-distribution inputs in the demonstrations substantially contribute to performance gains. This is likely because conditioning on the in-distribution text makes the task closer to language modeling, since the LM always conditioned on the in-distribution text during training.
5.2 label space
:label从random label->任意单词 时,两种模型表现不同:
direct models,性能下降快,5~16%,
channel models,性能下降不大 <2%,因为它是被label建模,并需要感知label space(全部至于空间)
the channel models only condition on the labels, and thus are not benefiting from knowing the label space. This is in contrast to direct models which must generate the correct labels.
:direct models vs channel models:
前者,更胜在exploit label space,后者更胜在exploit input distribution
5.3 input-label pairing
新增了一些format的测试:
demons with no-labels: 只有input text,每个样例不带标签
demons with labels -only:只有标签,没有input text
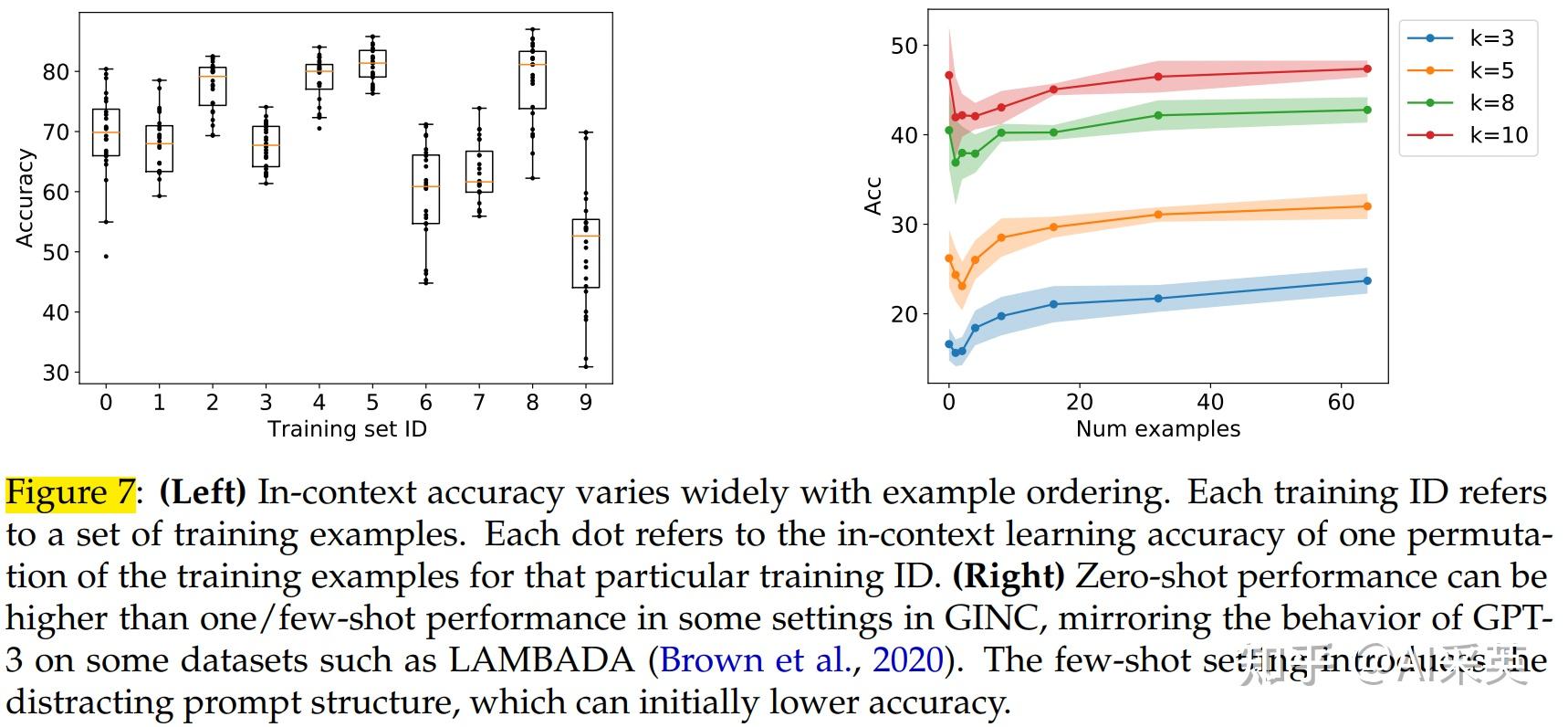
Left部分:Sensitivity to example ordering/示例样本的顺序
:上图每个train set ID,是一组样本;在某个ID内,样本按不同顺序,生成不同的分布,即,不同的样本。可以看到,效果是有差异的。
Right部分:Zero-shot is sometimes better than few-shot/Zero-shot有时表现更佳
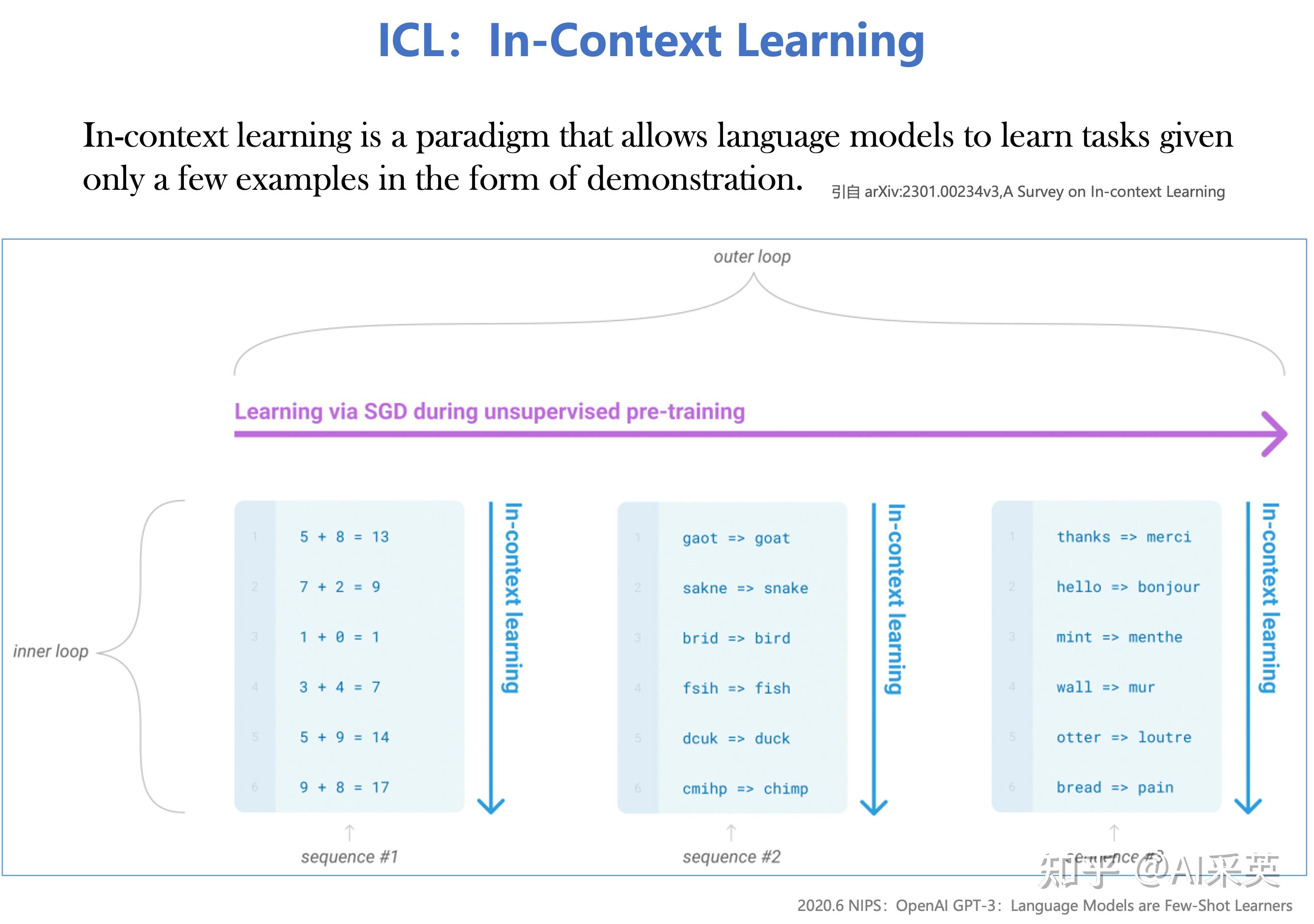
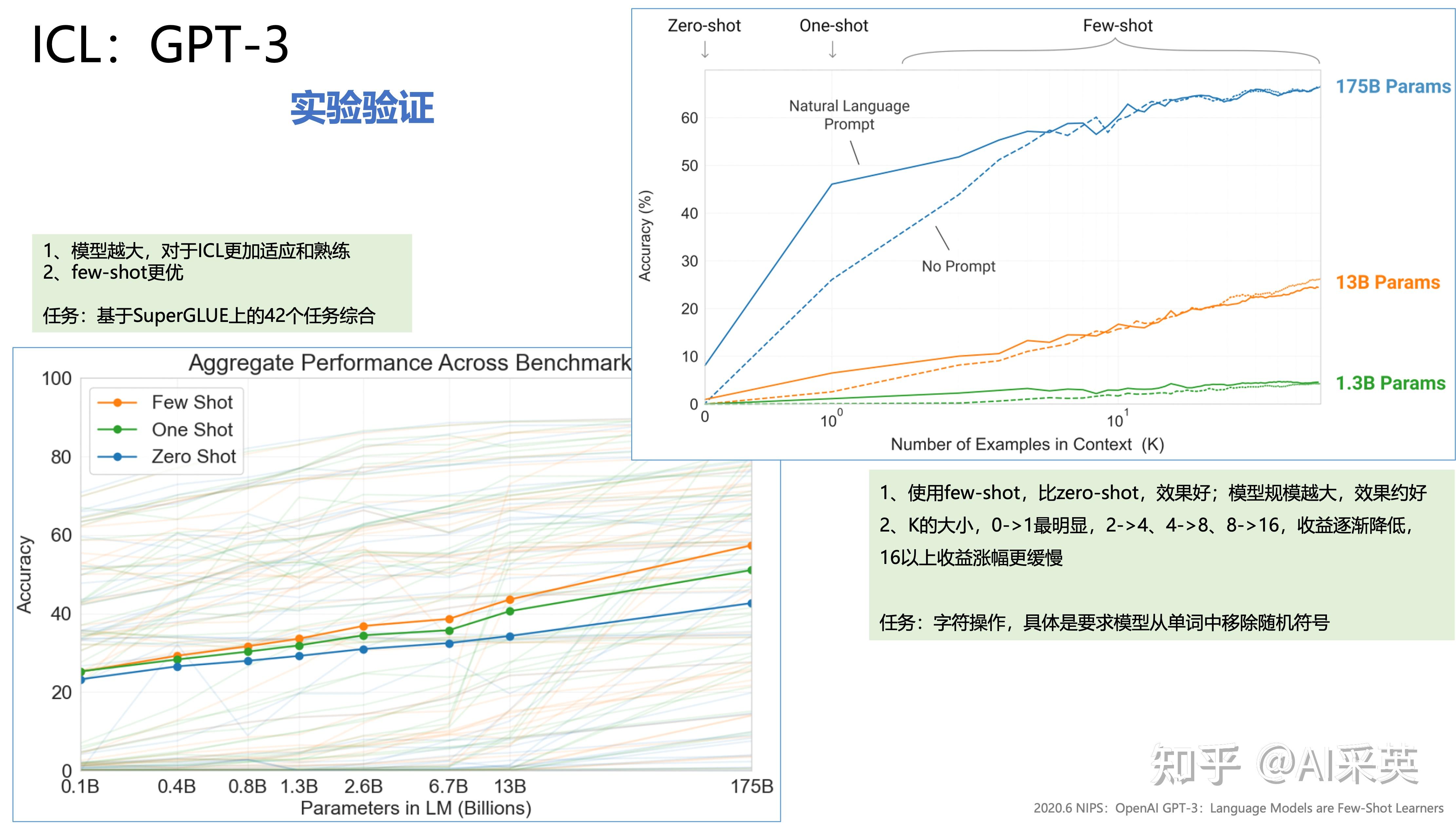
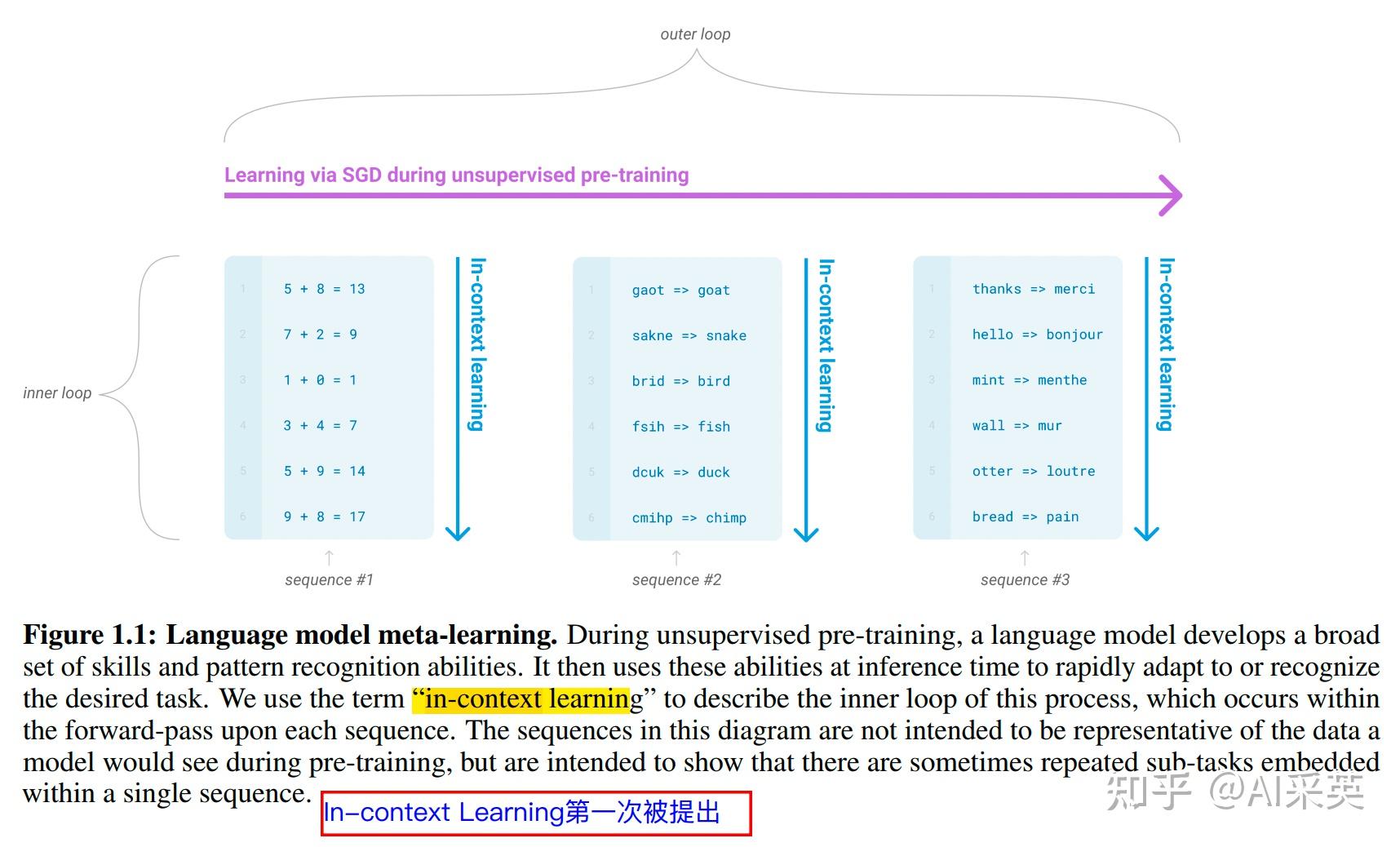
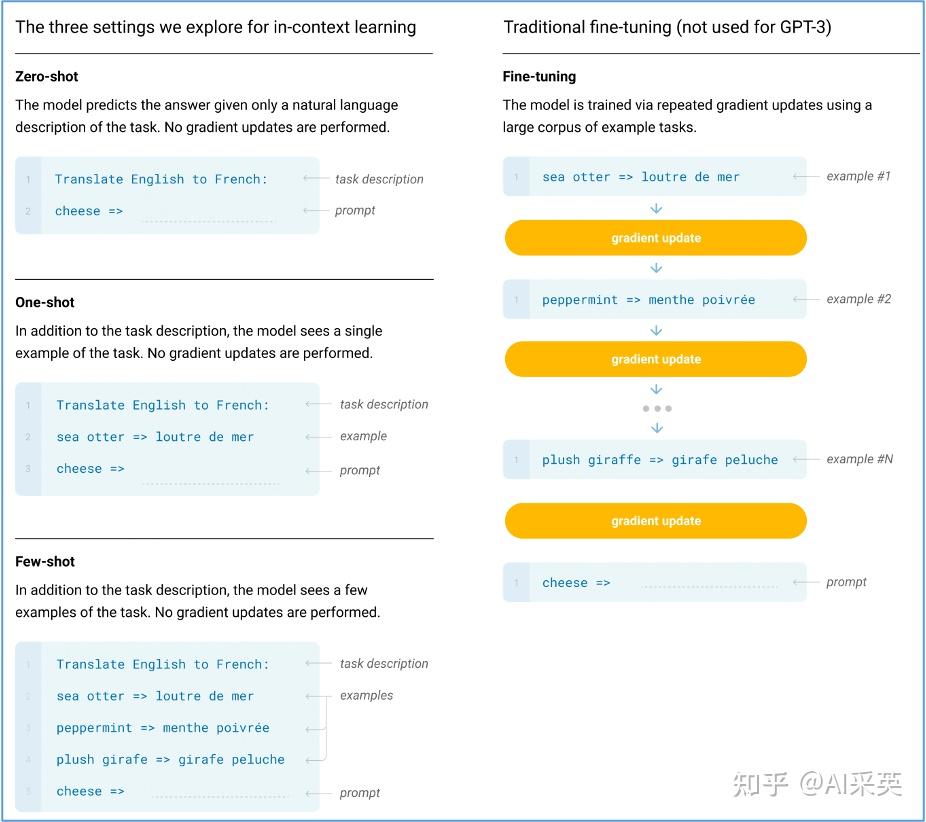
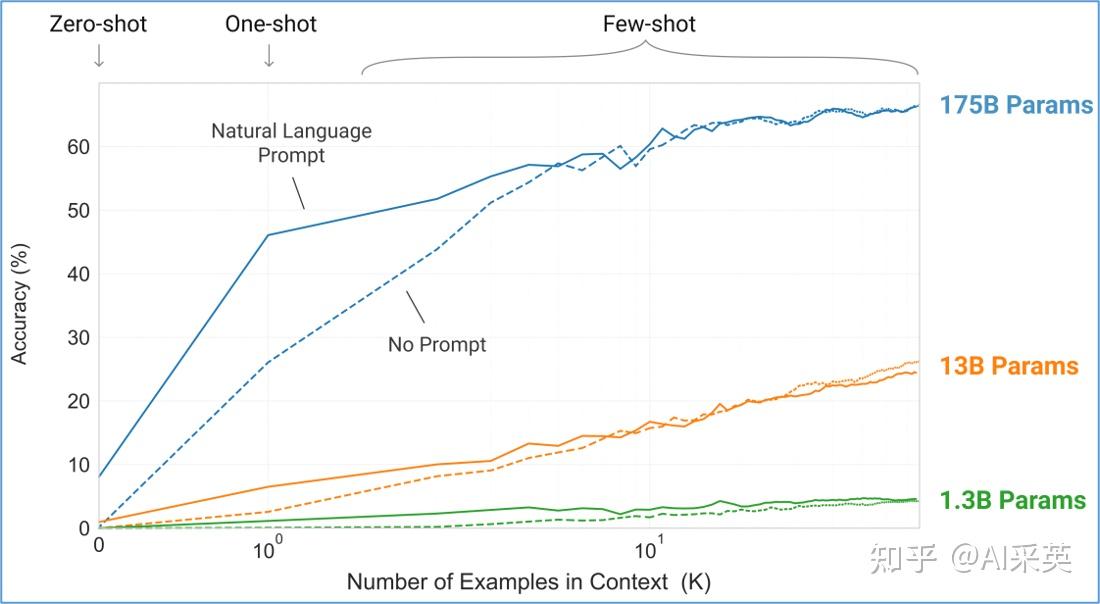
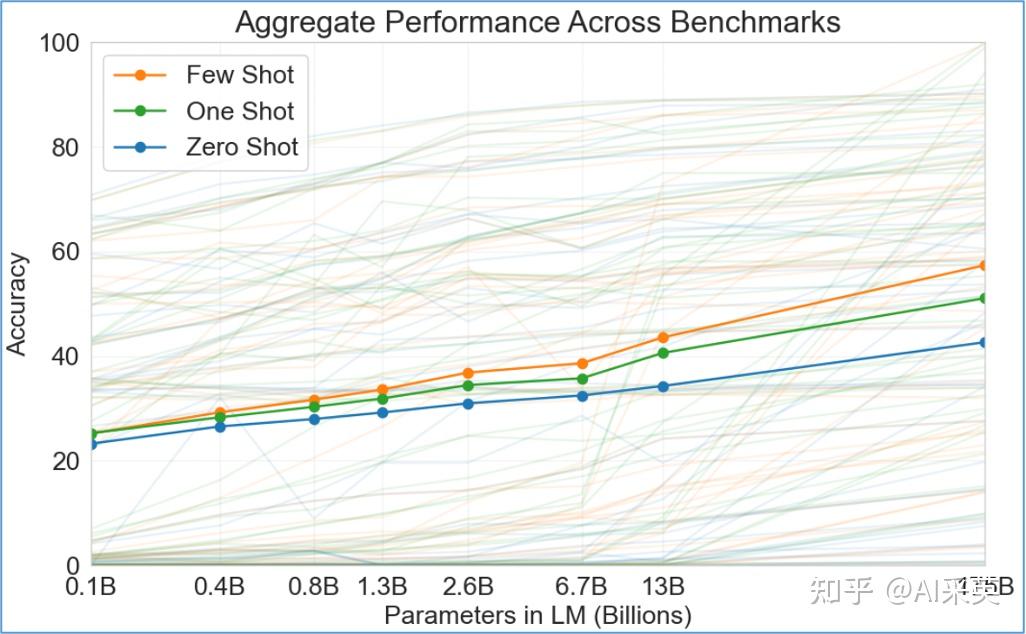
【20.6 OpenAI:在GPT-3提出ICL】
2020.6 NIPS:OpenAI GPT-3:Language Models are Few-Shot Learners

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 







 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年 2021庆中秋、迎国庆
2021庆中秋、迎国庆 2021庆【网站八周年
2021庆【网站八周年

 雷达卡
雷达卡 发表于 2024-12-19 15:14
发表于 2024-12-19 15:14















 提升卡
提升卡


