我用经典的农夫动物过河问题做了一些测试,但是做了一些修改,使用的是DeepSeek “深度思考(R1)”模型。
补充说明:每次提问都是在一个新会话中进行,以避免上下文影响。
原始的经典问题是:
A farmer with a wolf, a goat, and a cabbage must cross a river by boat. The boat can carry only the farmer and a single item. If left alone, the wolf will eat goat, the goat will eat cabbage.
How can they cross the river without anything being eaten?
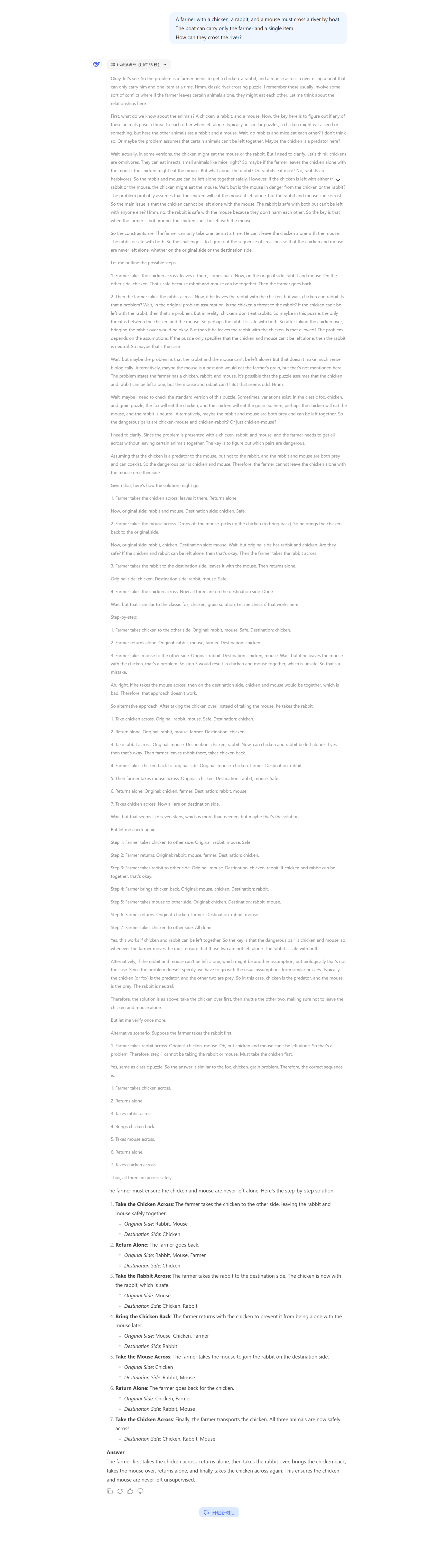
测试3:把动物换成chicken/rabbit/mouse,结果deep seek依然强行往经典问题上靠拢,甚至构造出了"the chicken might eat the mouse"的约束,它为什么一定要去构造约束?因为经典问题是有约束的,而最后的结果不出所料,依然是7步解决问题,和经典问题一样,我认为这次测试的结果失败。
测试4: 在测试2 animal A/B/C 的基础上,显式地加上了关于动物之间关系的约束 "A, B, C don't eat each other. They can stay together safely." 这一次,deep seek得到了正确结果,虽然中间过程依然提到了经典的问题。但是这种问法直接否定了经典问题所描述的场景,等于直接阻止deep seek陷入经典问题的训练结果。这是逻辑么?还是本质上依然是对外界直接命令的响应?而最终得出的所谓正确结论,是否不过是来自于某处的另一份训练数据?

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-1-31 15:12
发表于 2025-1-31 15:12