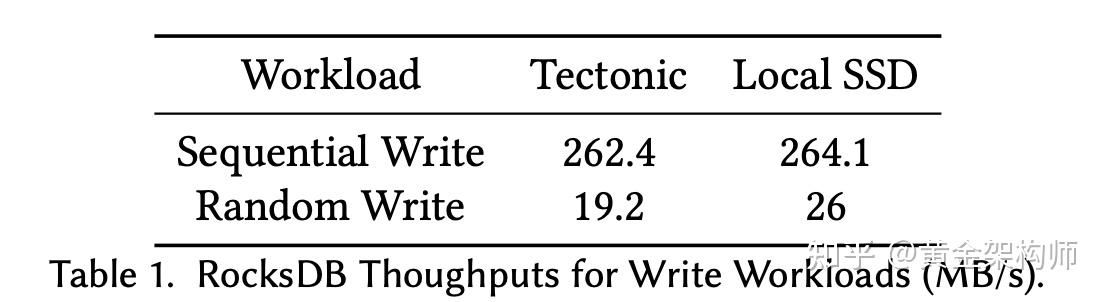
上图是写入的测试结果,Sequential Write 即数据有序写入,不需要 compact。Tectonic 和 Local SSD 的 throughput 是差不多的。对于 Random Write,Tectonic 大约慢了 25%。原文给的解释是:Although Tectonic can provide enough throughput for sequential read and write when operating multiple files, single files’ processing speed is limited and it causes some bottlenecks. Tuning RocksDB compaction knobs would be able to address these bottlenecks, but we leave the default setting for a better comparison.
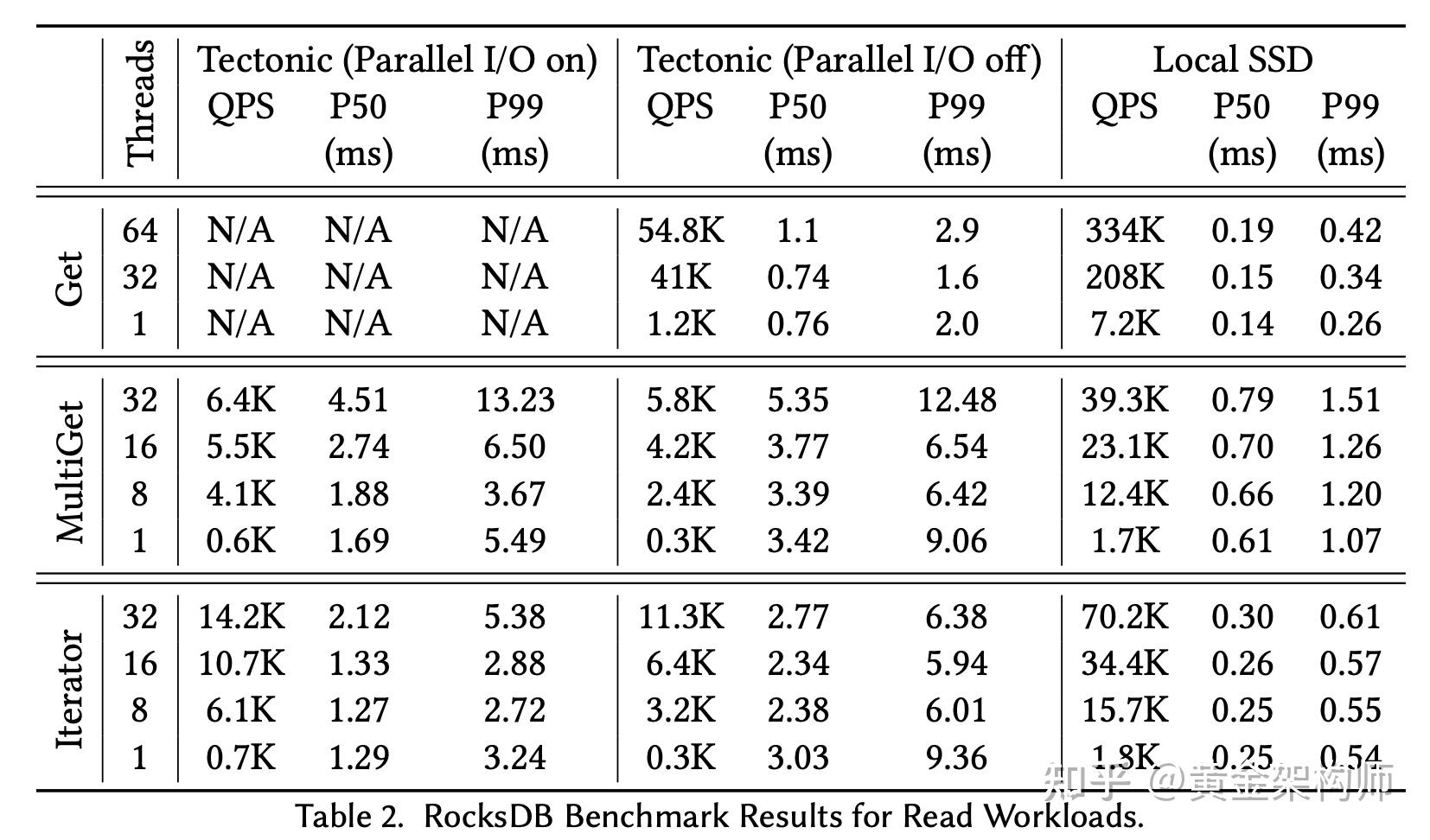
上图是读取的测试结果。RocksDB on Tectonic 测试了 parallel I/O off 和 on 两种模式。结果显示,Parallel I/O off 模式下,Tectoonic 的不同操作吞吐量大约是 Local SSD 的 5x,Parallel I/O on 模式下,能够优化到 3x。呃,有得必有失,性能会下降一点。
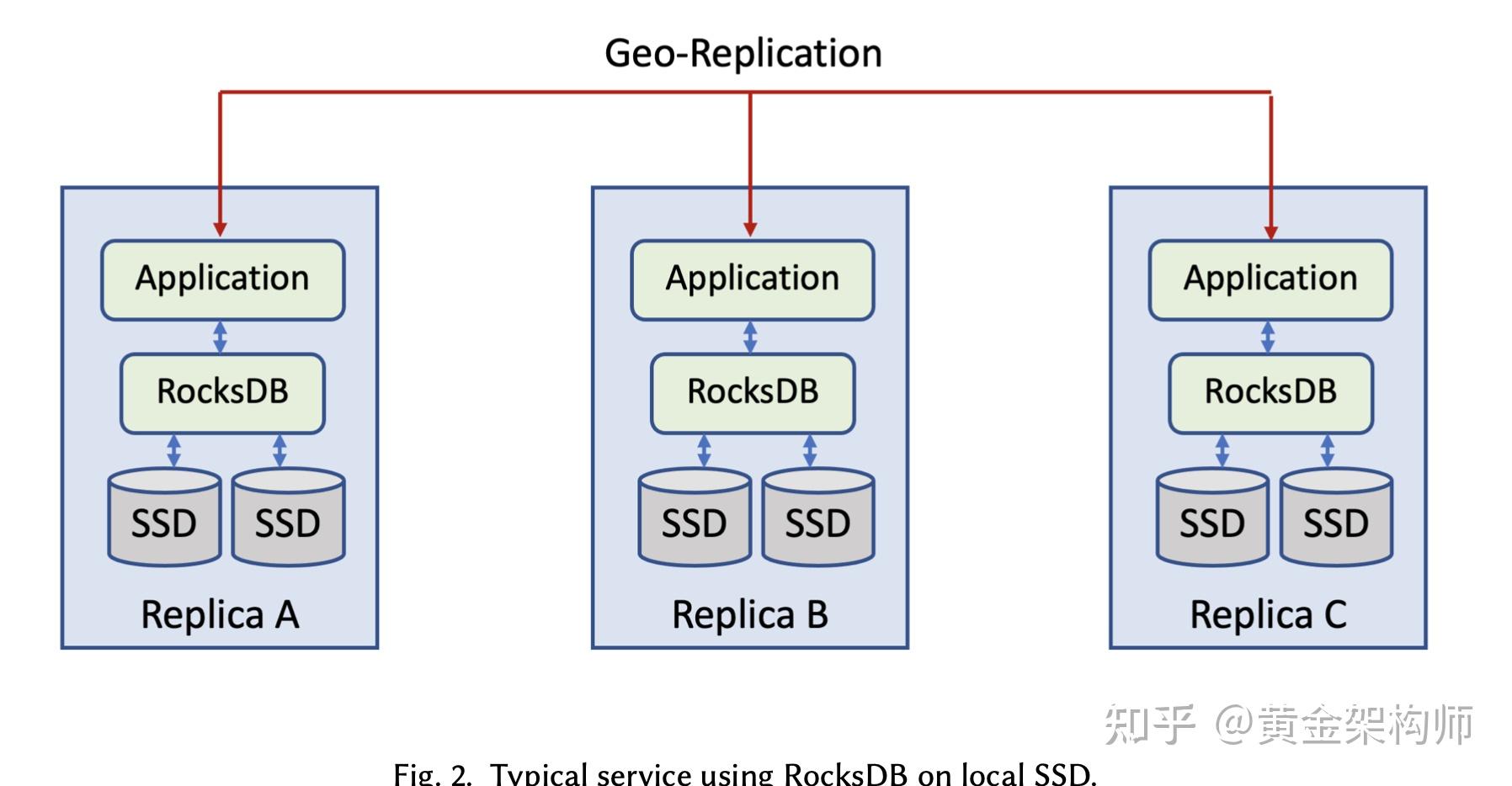
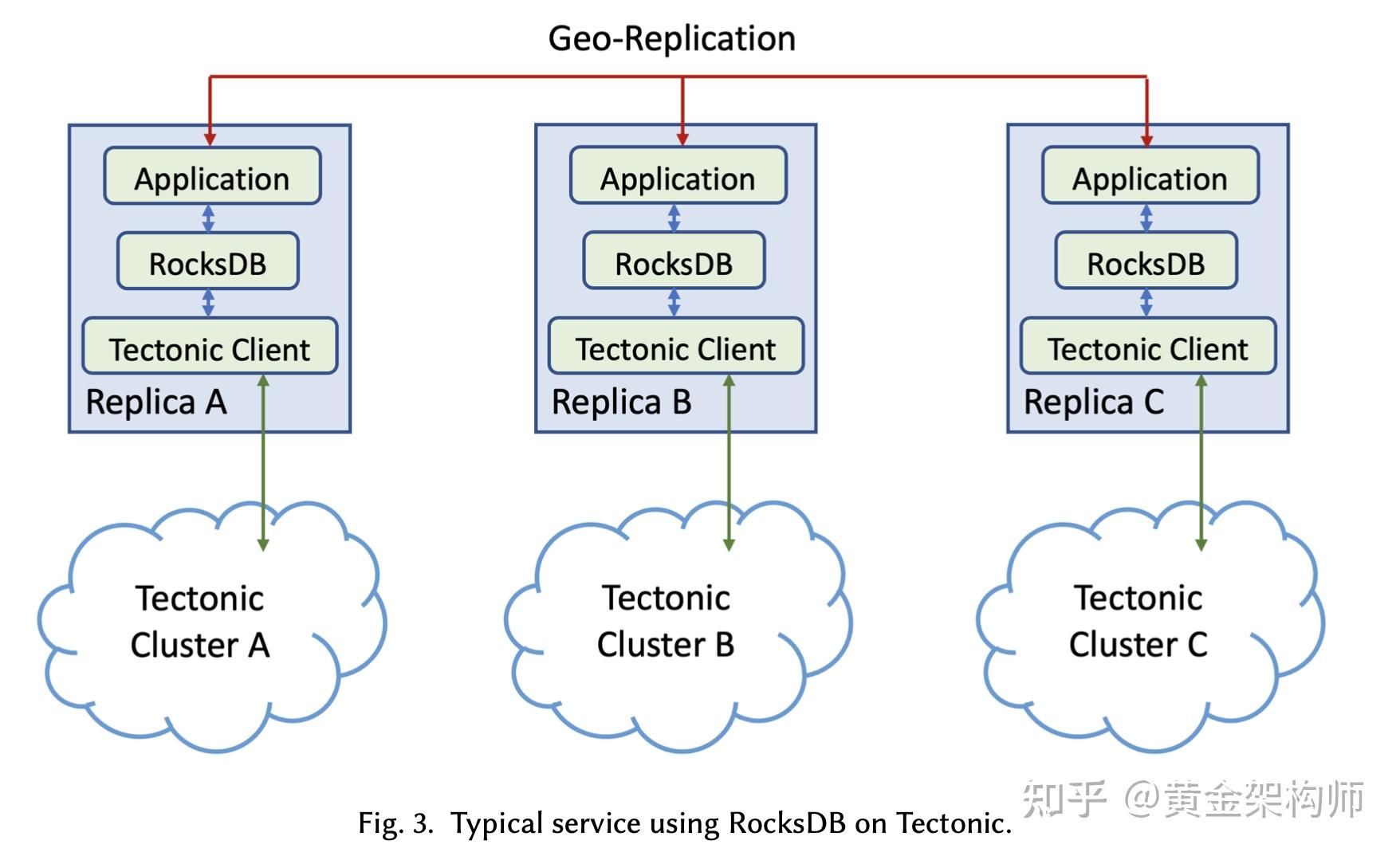
文章的最后还介绍了一个案例:基于 RocksDB on Tectonic 的 ZippyDB。这个案例很有参考价值,因为它涉及到一个非常有趣的问题:一个基于共识协议(e.g., Raft/Paxos) + RocksDB 实现的 share nothing 架构的数据库,如果存储放到了 DFS 上面,它的 Raft 日志放到哪里?显然,放到 DFS 上是不可能了,每次 Raft 日志持久化要刷到 DFS 上,时延太高,写入性能太差,如果是一个基于 RocksDB 的 OLTP 数据库(e.g., TiDB),这样的性能绝对是没法忍受的。这篇文章给的 ZippyDB 的方案是:仍然保持本地三副本的模式,只不过这三个副本是位于三个计算节点操作系统内核的 shared memory 中的,不做持久化。每次写入,需要把 raft 日志刷到三个计算节点的 shared memory 中,然后返回客户端成功。后台异步的把 shared memory 中的 raft 日志刷到 Tectonic 上。这里有一个假设,即认为多个计算节点的内核同时崩溃是非常罕见的,因此愿意承担一定数据的持久化风险,来换取写入性能。其实我曾经也想到过这个做法,还没有实践过,没想到已经有人在用了。
文章的最最后还提到了一些待做的工作:

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2025-1-25 23:00
发表于 2025-1-25 23:00



 提升卡
提升卡


