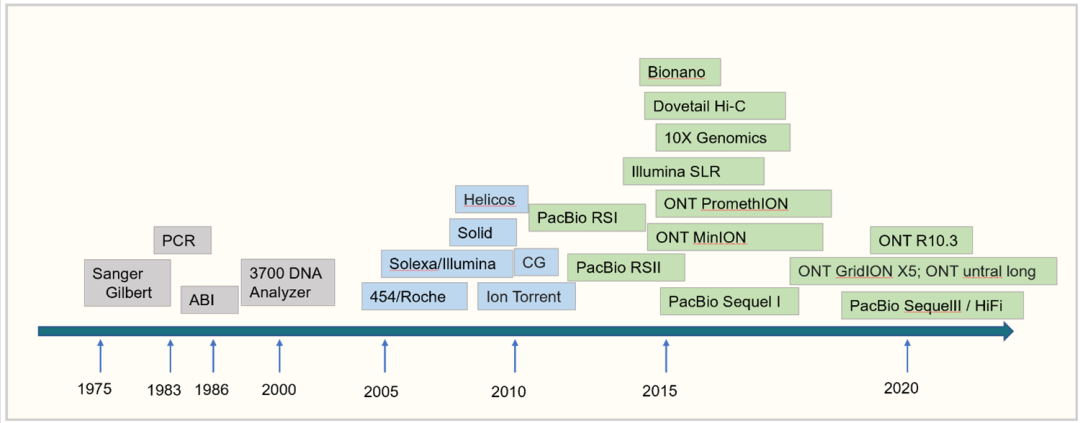
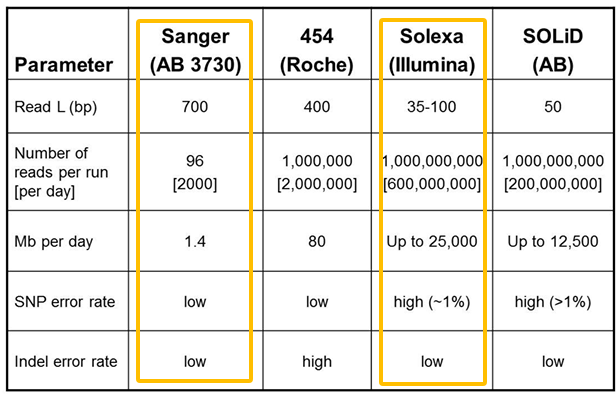
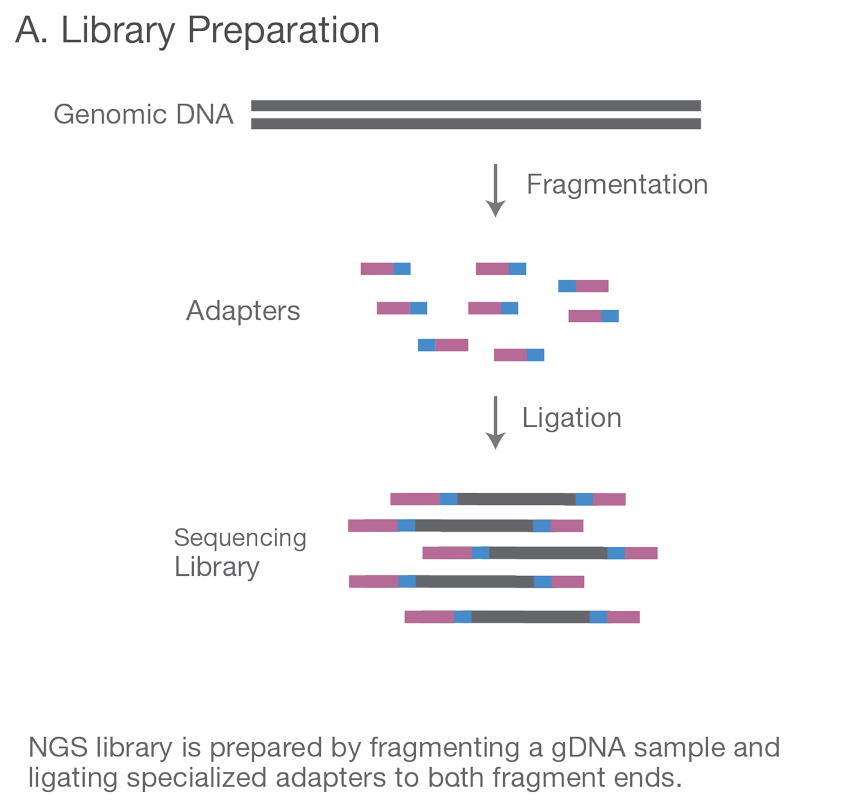
只需一步,快速开始
微信扫一扫,快速登录
您需要 登录 才可以下载或查看,没有账号?立即注册
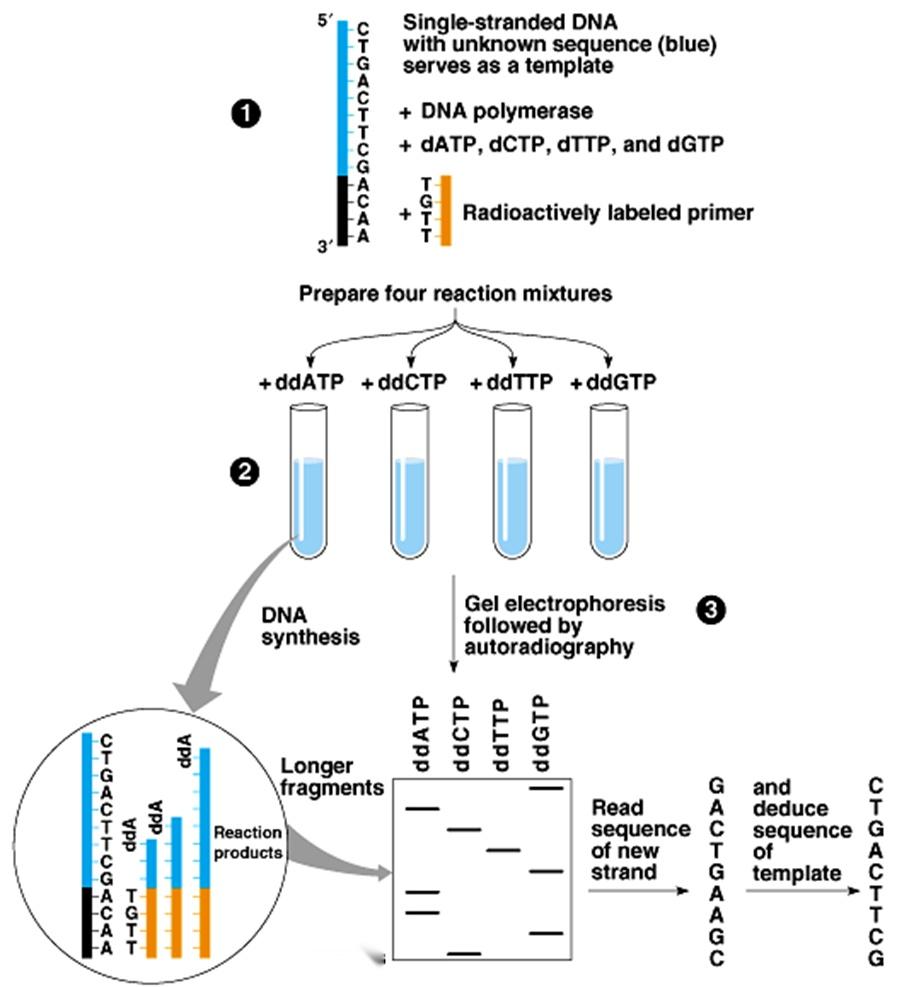
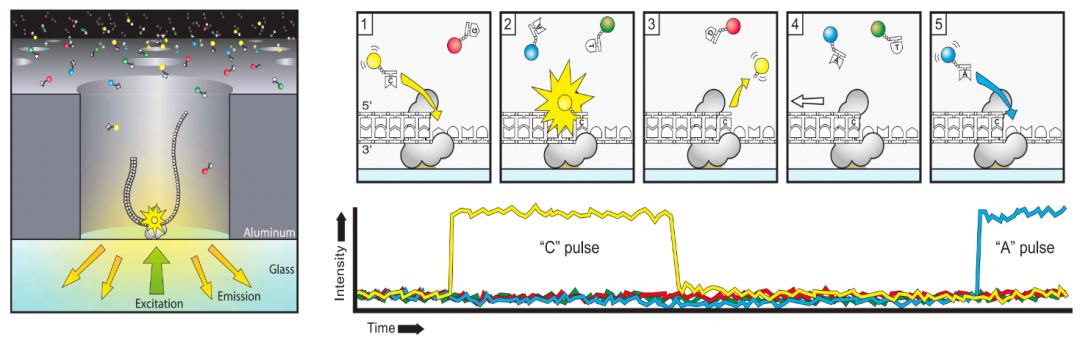
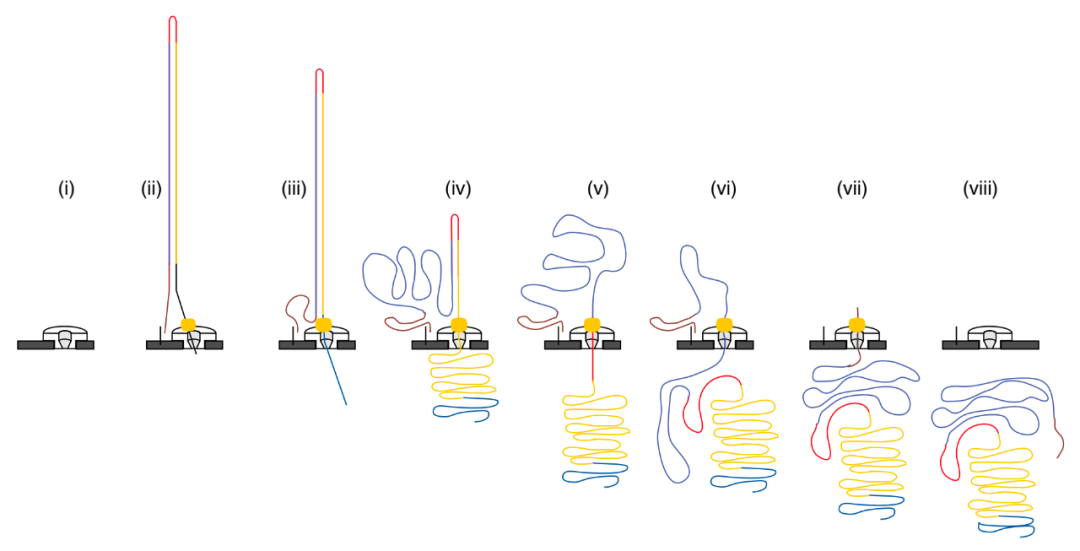
每一个脱氧核苷酸(dNTP)都由一个含氮碱基、一个脱氧核糖以及一个或多个磷酸基团组成。核苷酸手拉手形成【3%27,5%27磷酸二酯键】聚合组成长长的DNA链。 具体来说,一个核苷酸的3%27(三号碳位置)上的羟基(OH)与下一个核苷酸的5%27(五号碳位置)上的磷酸基团反应,通过脱去一个水分子(H2O),形成一个酯键,即3%27,5%27磷酸二酯键。 断臂杨过ddNTP ddNTP缺少三号碳位置上的羟基,不能与下一个dNTP反应,DNA链的合成便终止于此处。
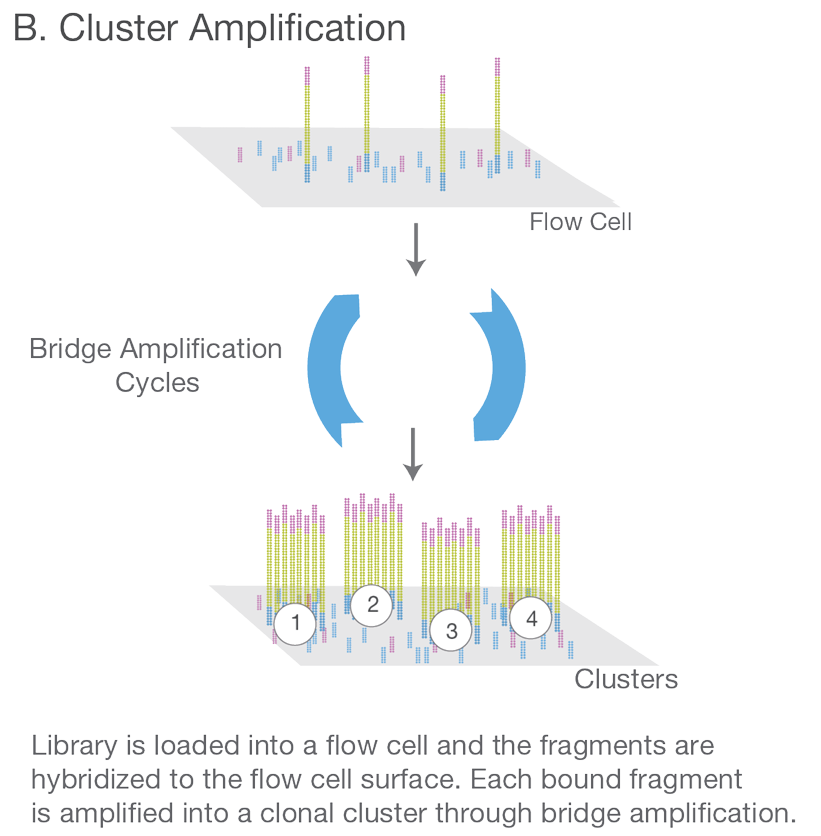
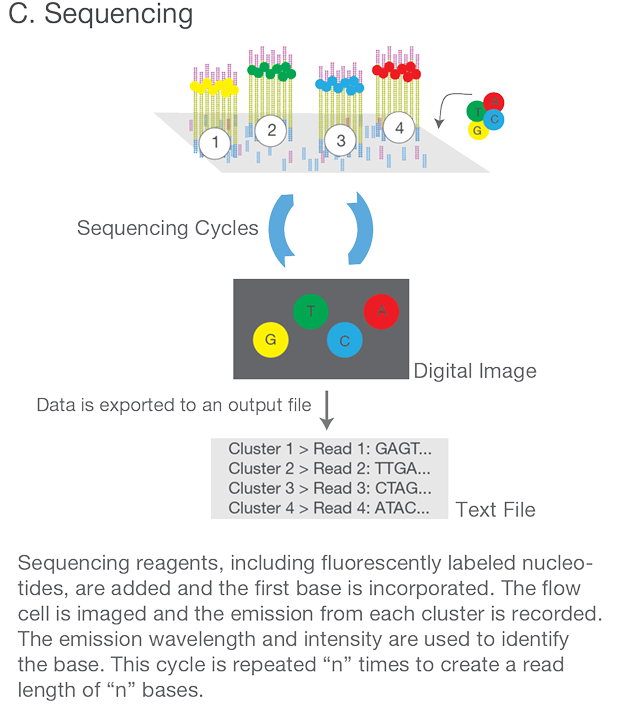
或许你会好奇这里复制这么多搞成一簇干嘛,看完步骤3我们再回头看看
举报
本版积分规则 发表回复 回帖后跳转到最后一页
查看 »
微信扫一扫关注本站公众号

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2025-1-22 14:58
发表于 2025-1-22 14:58