用户名
UID
Email
密码
记住
立即注册
找回密码
只需一步,快速开始
微信扫一扫,快速登录
开启辅助访问
快捷导航
门户
Portal
社区
BBS
资讯
会议
市场
产品
问答
数据
专题
帮助
签到
每日签到
企业联盟
人才基地
独立实验室
产业园区
投资机构
检验科
招标动态
供给发布
同行交流
悬赏任务
共享资源
VIP资源
百科词条
互动话题
导读
动态
广播
淘贴
法规政策
市场营销
创业投资
会议信息
企业新闻
新品介绍
体系交流
注册交流
临床交流
同行交流
技术杂谈
检验杂谈
今日桔说
共享资源
VIP专区
企业联盟
投资机构
产业园区
业务合作
投稿通道
升级会员
联系我们
搜索
搜索
本版
文章
帖子
用户
小桔灯网
»
社区
›
H、检验医学区
›
临检实验室(ICL)
›
EMNLP 2024 | 阿里通义实验室提出MLLM多图能力评估基准M ...
图文播报
2026庆【网站十三周
2025庆【网站十二周
2024庆中秋、迎国庆
2024庆【网站十一周
2023庆【网站十周年
2022庆【网站九周年
返回列表
查看:
10880
|
回复:
0
[分享]
EMNLP 2024 | 阿里通义实验室提出MLLM多图能力评估基准MIBench
[复制链接]
检验之星
检验之星
当前离线
金桔
金币
威望
贡献
回帖
0
精华
在线时间
小时
发表于 2024-10-23 17:15
|
显示全部楼层
|
阅读模式
登陆有奖并可浏览互动!
您需要
登录
才可以下载或查看,没有账号?
立即注册
×
本篇分享 EMNLP 2024 论文MIBench: Evaluating Multimodal Large Language Models over Multiple Images,阿里通义实验室提出MLLM多图能力评估基准MIBench。
论文链接:
https://arxiv.org/abs/2407.15272
数据链接:
https://huggingface.co/datasets/StarBottle/MIBench
动机
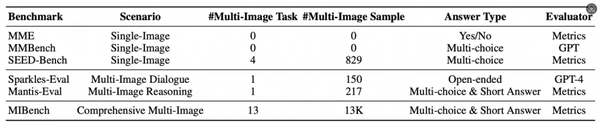
近年来,多模态大模型 (MLLMs) 在视觉描述、问答、推理等多种视觉-语言任务上展现出卓越的性能,也涌现出一批基准数据集工作,如MME、MMBench、SEED-Bench等,用于评估MLLMs在不同细分场景的能力。
然而,大多数MLLMs工作仅关注模型在单张图像输入时的性能,相应的评估基准也局限在单图场景。少数面向多图的评估数据集,如Sparkles-Eval、Mantis-Eval等,所包含的评估维度和样本数量十分有限。
基于此,阿里通义实验室mPLUG团队提出一个新的大规模基准测试集MIBench,包含13K条高质量测试样本,以全面、细致地评估现有MLLMs在多图场景的能力。
MIBench与现有MLLM评估基准对比
数据集设计
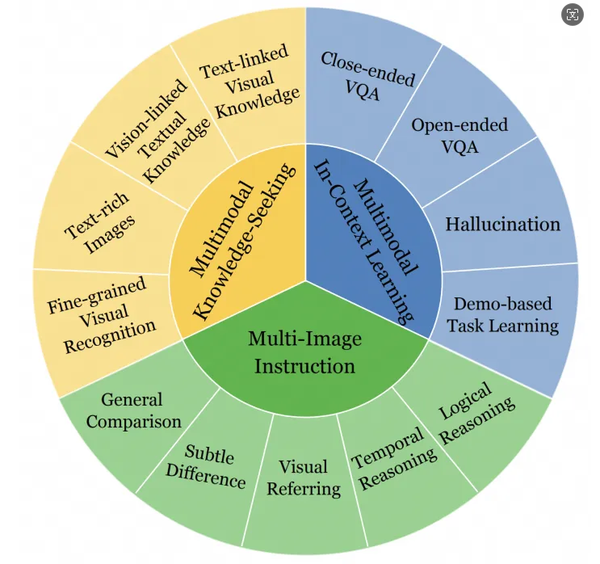
MIBench多图场景及子任务概览
如图所示,MIBench涵盖多图指令、多模态外部知识及多模态上下文学习等3个典型多图场景的13个细分子任务:
多图指令
:包含对输入的多张图像进行比较、指代、推理等指令。按照指令具体的语义类型,划分为
通用比较、细致差异、视觉指代、时序推理
和
逻辑推理
等5个子任务。
多模态外部知识
:模拟多模态检索增强 (RAG) 场景,考察MLLMs从图文形式的外部知识中,获取与当前问题有关的信息的能力。按照外部知识的形式,划分为
细粒度识别、富文本图片、视觉连接的文本知识
和
文本连接的视觉知识
等4个子任务。
多模态上下文学习
:考察MLLMs基于若干演示 (demo) 回答视觉问题的能力。以往对多模态上下文学习 (ICL) 能力的评估,笼统地以模型在Caption/VQA等数据集上的性能随demo数量增加的变化来衡量。为了细致地评估多模态ICL对不同方面能力的影响,作者划分了
封闭式VQA、开放式VQA、物体幻觉
和
任务学习
等4个子任务。
数据集构建
数据集的构建包括图片来源、选项生成、知识采样、质量控制等方面。
图片来源
:为了获得高质量的评估样本,收集相关数据集作为图片来源,例如在多图指令场景使用MagicBrush、VrR-VG等数据集,在多模态外部知识场景使用SlideVQA、InfoSeek等数据集,在多模态上下文学习场景使用Mini-ImageNet、POPE等数据集。
选项生成
:采用多项选择的形式进行模型评估,为了使干扰项具有足够的挑战性,针对不同子任务,采用两种方案生成选项。第一种方案,根据任务特点设计相应的采样策略,从数据集的原始标注中采样与ground truth具有一定相似性和混淆性的其他标注作为干扰项;第二种方案,使用大语言模型如GPT-4,根据问题和ground truth生成一些错误的答案作为干扰项。
知识采样
:对于多模态外部知识场景,为了使题目具有挑战性,采用两个采样原则:一是设置的干扰项均在采样的外部知识中有对应信息;二是外部知识中的正确与错误信息之间存在关联性,避免因干扰信息与问题无关导致模型利用语言先验走捷径,从而对模型性能产生错误的评估。
质量控制
:设计两种自动化筛选策略,利用SOTA MLLMs,筛除去掉图像/外部知识后仍能正确回答的样本,以消除问题或选项本身存在的bias。进一步结合人工验证,以确保生成数据中没有重复或模棱两可的选项。
评估策略
:采用多项选择题形式,并循环设置正确选项,以消除LLM对选项位置偏好的影响。
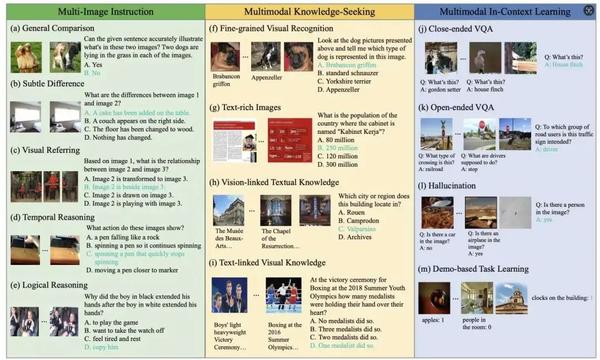
数据集子任务示例
模型评估与分析
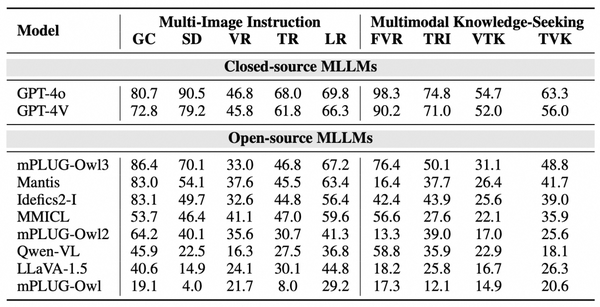
数据集设计和构建完成后,作者首先在多图指令和多模态外部知识场景,评估了多个开源的单图及多图MLLMs,以及GPT-4o等闭源模型的性能。通过对不同子任务测试结果的分析,可以看到:
开/闭源性能差距
:现有开源MLLMs相比GPT-4o,在多图指令和多模态外部知识场景的多数子任务上,仍然存在较大的性能差距。
细粒度感知缺陷
:开源模型在细致差异(SD)、富文本图片(TRI)等依赖细粒度感知能力的任务上,性能大幅落后于GPT-4o。
多图训练的重要性
:采用多图预训练的Idefics2模型,与采用多图指令微调的Mantis模型,在多数任务上的表现明显优于单图模型。
多模态外部知识场景极具挑战
:富文本图片(TRI)、视觉连接的文本知识(VTK)和文本连接的视觉知识(TVK)等任务对现有开源MLLMs提出了极大的挑战,即使对于GPT-4o也仍存在较大的提升空间。
作者进一步分析了开源MLLMs在多模态外部知识场景的性能瓶颈,可以看到:
对于
富文本图片任务
,即使去除外部知识中的干扰项,模型性能也仅取得了微弱的提升,而Idefics2模型采用图片切分进行高分辨率输入,能够获得显著的性能提升,说明
低分辨率输入造成的信息损失
是MLLMs在该任务上的性能瓶颈。
比较
视觉连接的文本知识
(VTK)和
文本连接的视觉知识
(TVK)两个对称的子任务,可以发现去掉外部知识中的干扰项后,模型在VTK任务上取得了非常显著的性能提升,而在TVK任务上则提升较小。说明VTK任务的性能瓶颈,主要是
模型无法很好地捕捉图片间的视觉关联
。而TVK任务中,模型虽然能够较好地捕捉文本间关联,但对于视觉知识的理解和提取能力限制了模型的性能。
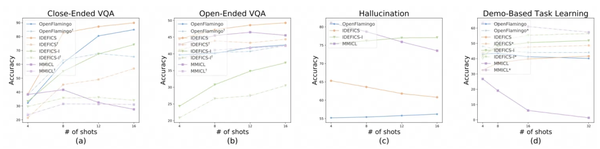
此外,在多模态上下文学习场景,作者着重评估了OpenFlamingo、Idefics、MMICL等具备ICL能力的模型,从上图显示的实验结果可以看到:
评估的MLLMs在封闭式VQA任务中,表现出较为显著的多模态上下文学习能力;
在开放式VQA任务中,MLLMs的上下文学习主要由语言模态驱动;
多模态上下文学习对缓解大模型的物体幻觉没有帮助,甚至呈现出副作用;
MLLMs基于示例学习任务的能力非常有限。
投稿
最新 AI 进展报道
请联系:amos@52cv.net
END
原文地址:https://zhuanlan.zhihu.com/p/968837434
回复
举报
返回列表
发表回复
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
关闭
官方推荐
/3
AI助手<小桔子>来了!
欢迎来交流,可以回答IVD行业各类问题!
查看 »
IVD业界薪资调查(月薪/税前)
长期活动,投票后可见结果!看看咱们这个行业个人的前景如何。请热爱行业的桔友们积极参与!
查看 »
小桔灯网视频号开通了!
扫描二维码,关注视频号!
查看 »
返回顶部
快速回复
返回列表
客服中心
搜索
洽谈合作
关注微信
微信扫一扫关注本站公众号
个人中心
个人中心
登录或注册
业务合作
-
投稿通道
-
友链申请
-
手机版
-
联系我们
-
免责声明
-
返回首页
Copyright © 2008-2024
小桔灯网
(https://www.iivd.net) 版权所有 All Rights Reserved.
免责声明: 本网不承担任何由内容提供商提供的信息所引起的争议和法律责任。
Powered by
Discuz!
X5.0 技术支持:
宇翼科技
浙ICP备18026348号-2
浙公网安备33010802005999号
快速回复
返回顶部
返回列表

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 






 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 发表于 2024-10-23 17:15
发表于 2024-10-23 17:15