金桔
金币
威望
贡献
回帖0
精华
在线时间 小时
|
登陆有奖并可浏览互动!
您需要 登录 才可以下载或查看,没有账号?立即注册


×
本文是由哥伦比亚大学博士生罗艺主讲的『端到端声源分离研究进展』整理而来。内容主要覆盖了单通道和多通道上端到端音源分离的现状和进展以及未来的研究方向。 ------本文约5580字,阅读约需20min------
端到端音源分离定义与进展什么是端到端音源分离呢?罗艺老师首先介绍了端到端音源分离的定义。从名称来看,端到端的含义是模型输入源波形后直接输出目标波形,不需要进行傅里叶变换将时域信号转换至频域;音源分离的含义是将混合语音中的两个或多个声源分离出来。
文末有彩蛋,评论可获取课程学习资料~^-^
(图1)
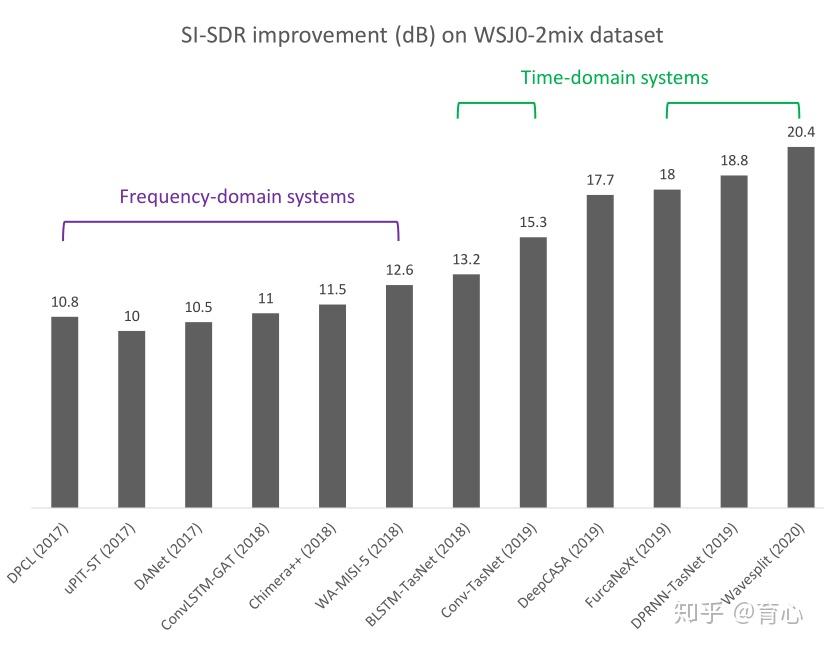
目前,端到端音源分离已经有了一些在时域和频域上的研究,罗艺老师以“WSJ0-2mix”数据集为例,并以在语音分离任务中使用十分广泛的SI-SDR为指标,为我们展示了目前端到端音源分离研究的进展。从图2中也可以直观地看到时域方法相较频域方法能够带来非常明显的提升,时域方法也因此成为了端到端音源分离的热门研究方向。
(图2)
单通道端到端音源分离研究
频域方法中广泛使用神经网络估计TF- Masking,并作用于混合语音从而得到分离语音。但该方法存在相位信息缺失、性能上限受制于oracle mask以及STFT特征不一定是分离模型最优特征等问题或挑战。
因此时域模型提出可以通过使用实数特征提取器以替代STFT特征以及直接建立wav2wav映射的方法来解决上述问题。
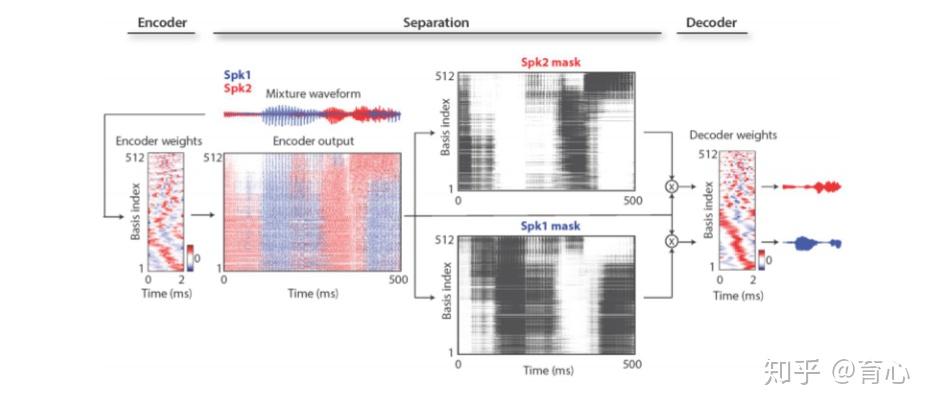
最先被提出的方法为TasNet模型,该模型使用Encoder提取语音二维特征,随后通过Separation估计说话人mask,最后通过Decoder实现二维特征到语音波形的转换从而得到分离语音。
(图3)
由于Decoder存在无法完美重构的问题,因此对于TasNet的深入探究和修改也得到了很多新的研究结果。在下述Two-step separation中,首先单独训练Encoder以及Decoder以期其能引入更少的失真。随后固定Encoder和Decoder只训练Separation,该训练方法可提升分离上限。
(图4)
此外我们希望Encoder能够更关注低中频部分,因此提出了Multi-phase Gammatone filterbank,相较于随机初始化学习,该方法可得到更好的频率响应分布。
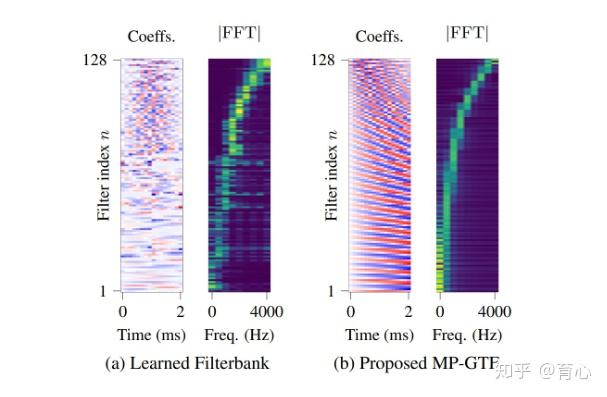
(图5)
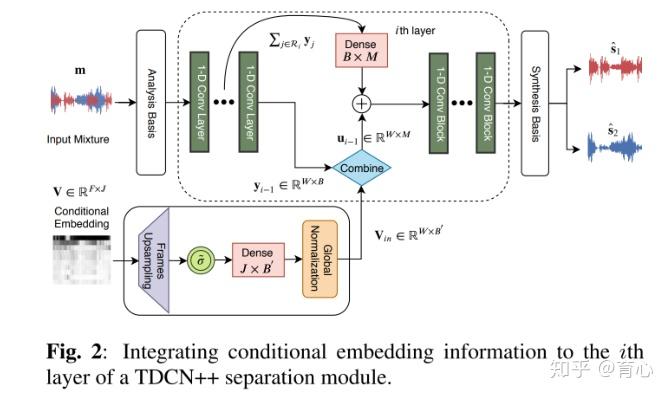
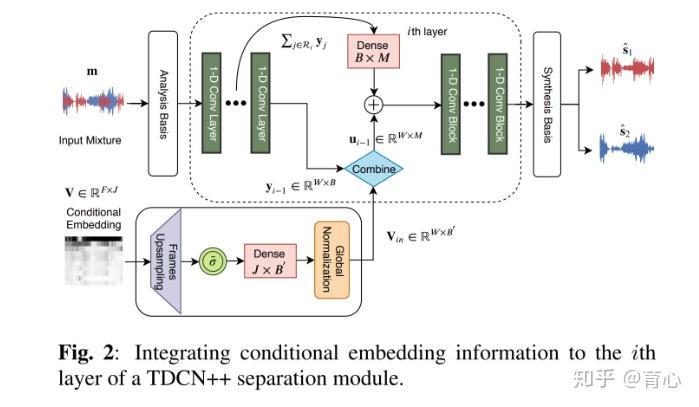
此外还有对训练目标和训练任务上的一些探索。Wavesplit引入说话人特征进行分离。该模型首先在一个固定时间窗内计算说话人向量,然后通过聚类计算出全局向量。之后将说话人信息送入分离网络得到分离结果。
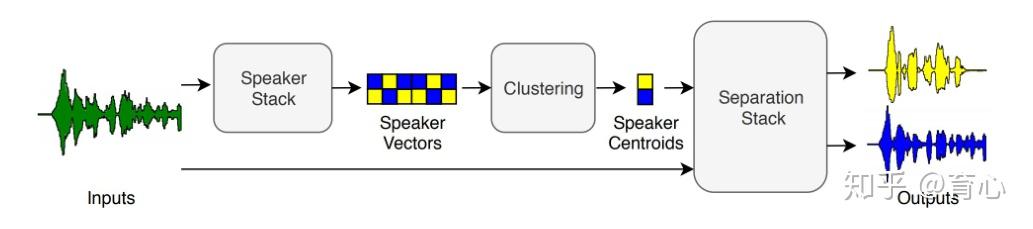
(图6)
MulCat DPRNN通过同时优化分离和说话人识别两个目标实现更好的说话人分离,此外该网络能够实现5-6人的分离,因此该网络是一个很好的设计。
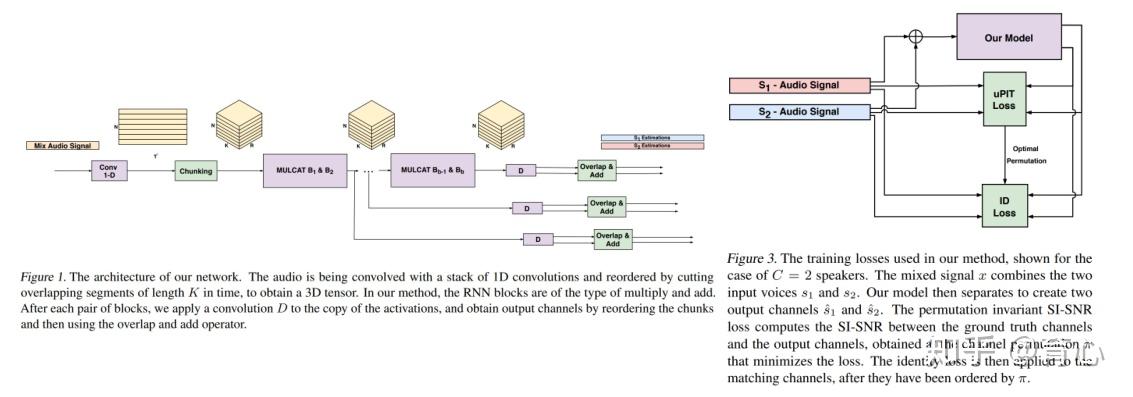
(图7)
以上介绍的网络目标均为将所有源分离出来,但在一些情况下一些源不具备很明显的被分离的意义,如智能音箱场景,因此说话人提取也具有十分重要的研究意义。
SpEx/SpEx+联合TasNet和说话人提取网络,从而只输出一个说话人的mask,实现声源提取的工作。
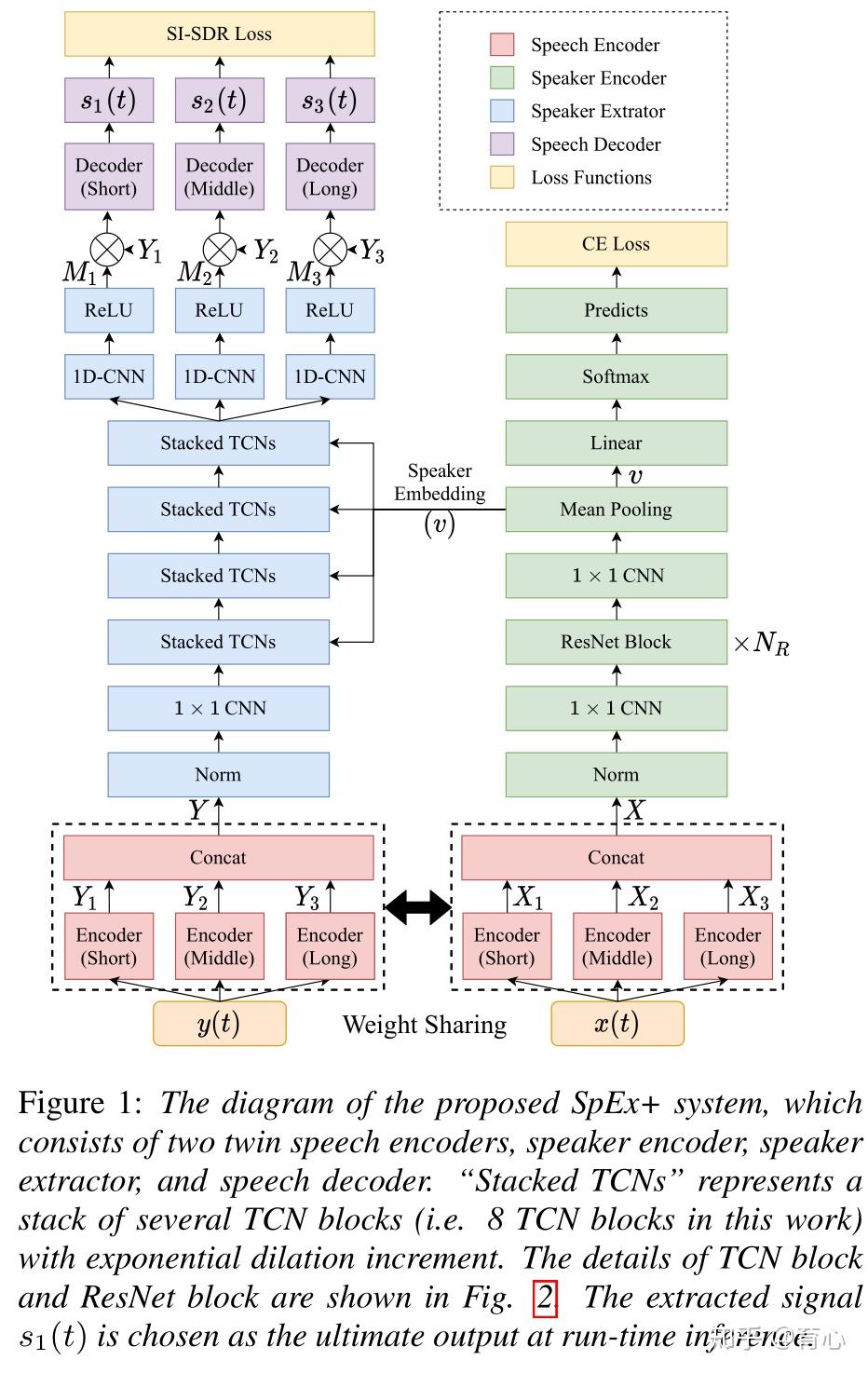
(图8)
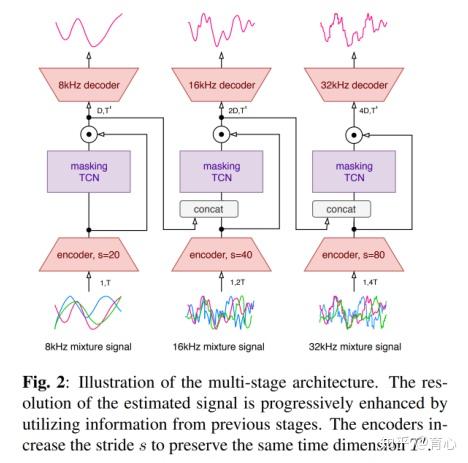
时域分离模型亦可作用到音乐分离任务上。音乐分离与语音分离的不同之处在于不存在置换问题。但由于音乐采样率普遍高于语音,因此会存在建模长序列及不同频带信息捕捉的问题。
Music separation采用progressive learning方法,从低至高分采样率处理,并通过元学习(meta-learning)的方法,对不同声源类型进行网络参数调整。
(图9)
语音分离的最终目标为Universal separation,即广义语音分离。Universal sound separation通过声学事件检测,提取声学事件特征,从而辅助广义声源分离。
(图10)
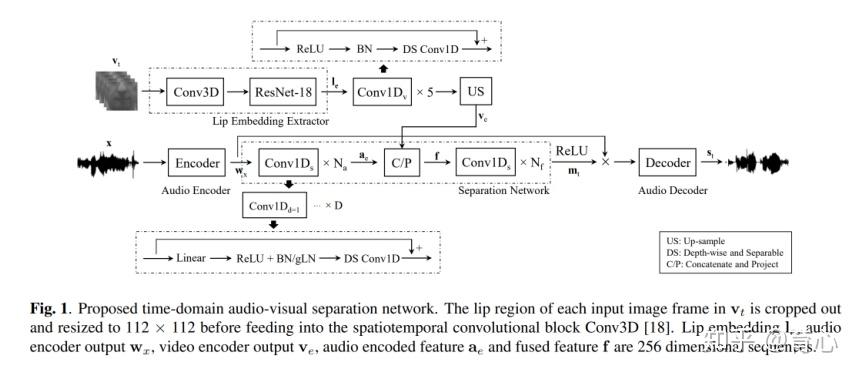
如果跳出音频,多模态信息亦可辅助语音分离。例如视频会议场景下,我们可以通过视频信息检测说话人特征,并分离该说话人语音。Audio-visual separation通过图像分析网络对嘴唇运动特征提取,送入TasNet模块,从而辅助音频分离任务。
(图11)
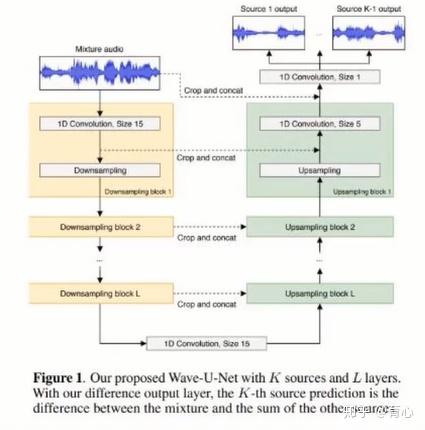
如果跳出Encoder-Separation-Decoder框架,可以进行waveform-to-waveform直接映射。Wave-U-Net通过设计相同层数的广义编解码器并实现编解码器间向量拼接操作,通过一维卷积实现波形-波形映射。
(图12)
基于WaveNet设计的模型结构在最后一层的输出上将所有声源分离开来。
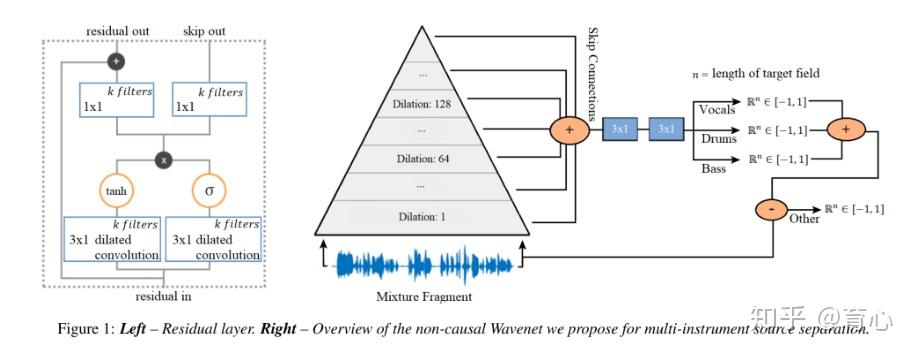
(图13)
多通道端到端音源分离研究
相较于单通道,多通道语音可得到更多的空间信息,从而进一步辅助语音分离。目前多通道端到端语音分离研究主要集中在两个方向:神经网络波束形成以及单通道模型向多通道扩展。基于输出的神经网络波束形成方法主要有DeepBeam和Beam-TasNet方法。
DeepBeam使用时域多通道维纳滤波,先选择一个参考麦克风,通过训练单通道增强网络对该麦克风信号进行预增强得到更加干净语音的信息,并利用该信息作为维纳滤波的目标,对其他麦克风解最优维纳滤波解得到最优滤波器参数。

(图14)
Beam-TasNet方法通过时域频域结合的方法。首先通过多通道TasNet分离得到预分离语音,随后通过分离语音估计频域上的MVDR权重,并作用于混合语音中得到分离语音。该方法通过时域方法隐式地进行了相位估计,并利用了空间特征得到分离语音。此外时域方法loss函数存在静音段消除过于激进的问题从而导致听感上的不友好。
而MVDR方法可对整句话进行滤波,对某一声源消除能力略低但失真较少,因此Beam-TasNet 中也考虑了如何将二者的长处在后处理步骤中进行结合,以得到更好的性能。
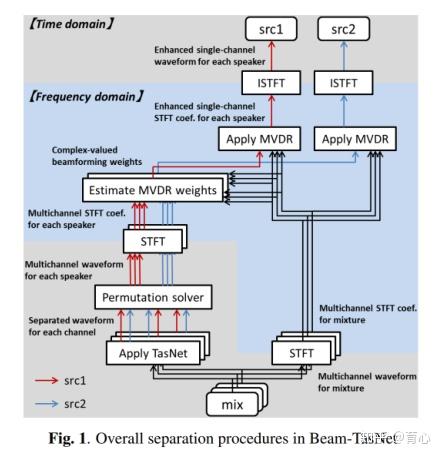
(图15)
此外基于神经网络的波束形成主要工作有Neural network adaptive beamforming(NAB),Filter-and-sum Network(FaSNet)。
NAB方法通过将多通道信号拼接送入神经网络估计得到每个通道的滤波器系数,并作用于每个通道的原始信号可得到增强信号。该方法类似于Filter-and-Sum Beamformer。
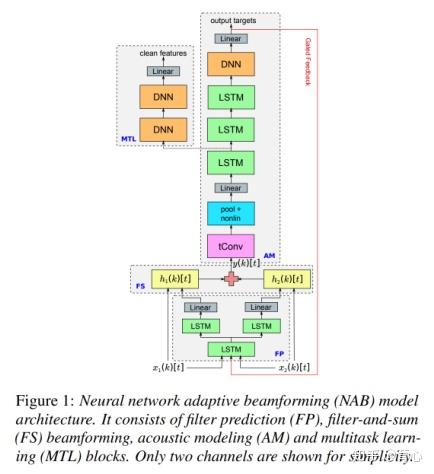
(图16)
FaSNet则侧重于多通道间信息共享以联合优化多通道时域滤波器。(该方法也是笔者目前尝试的所有时域分离模型中效果最好的方法)
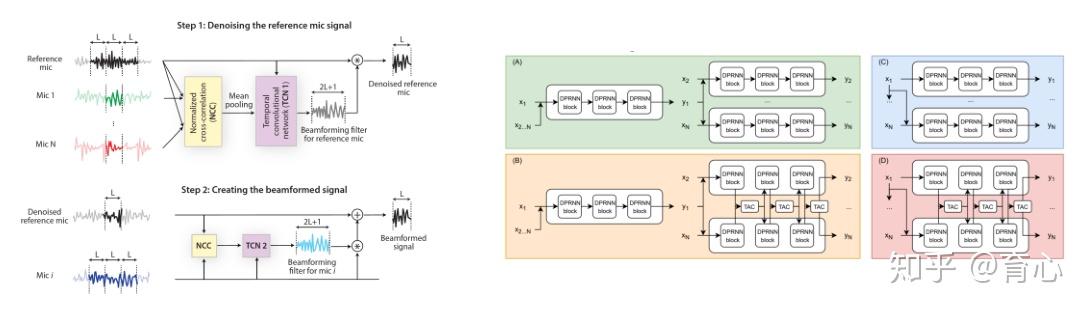
(图17)
而对于单通道向多通道扩展的方向,目前主要的方法是对单通道信号加入多通道信息作为模型输入以及直接将多通道信号作为模型输入。Multi-channel TasNet通过将单通道信息拼入IPD进行联合训练,或直接使用二维卷积估计通道间特征插值进行联合训练。
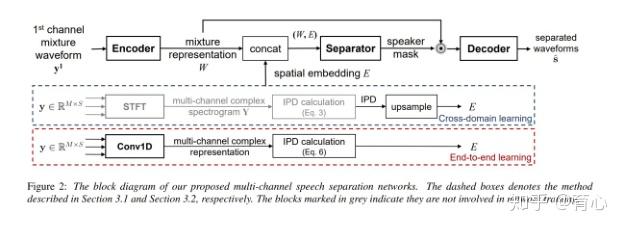
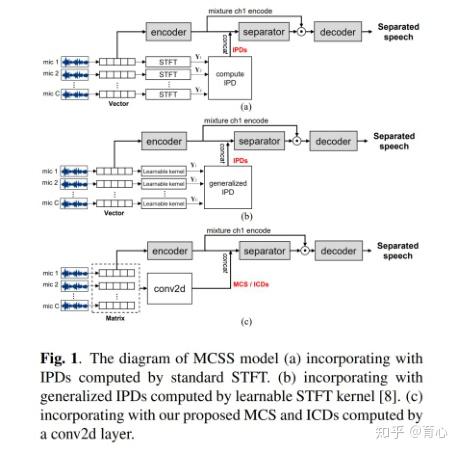
(图18)
Multi-channel Wave-U-Net则是将多通道信号拼接送入Wave-U-Net,因此只需将模型的输入通道数改为信号的通道数即可。
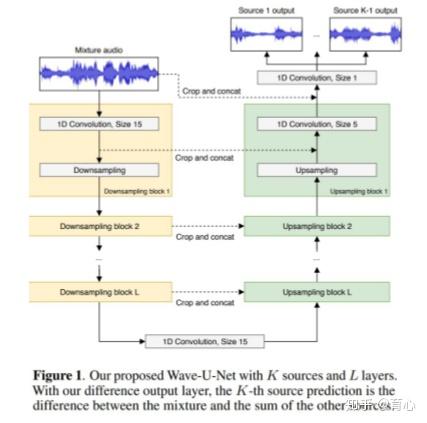
(图19)
一些问题和未来展望
如何得知混合音频中有多少说话人?在会议或讨论场景中两人同时说话的占比一般最高只为30%左右,大多数时间为一个人甚至没有人说话。
因此如何使用一个分离模型保证在不同说话人数量情况下都能保持较稳定性能是一个比较挑战的问题。目前在尝试的方法有多说话人活动检测以及说话人识别等,还可设计不同的训练目标以匹配不同的说话人个数。
长时间语音分离。如何保证在1-10min甚至1h的语音能够一致保证分离的稳定性?目前已有LibriCSS数据集面向此应用场景。此外还有JHU JSALT 2020 workshop面向长时间多人说话的说话人数量、语音识别、语音分离和说话人识别。(https://www.clsp.jhu.edu/speech-recognition-anddiarization-for-unsegmented-multi-talker-recordings-with-speaker-overlaps/)
未来一些挑战包括广泛的语音分离、前后端联合优化及真实场景(包括远场、噪声、混响和域不匹配)下的应用。
Q&A
1. 单通道与多通道语音分离的各自应用场景有什么不同,多通道有什么具体优势吗?
对于应用场景,主要是设备上的区分,有些设备只有一个麦克风因此就只能做单通道语音分离。多通道由于有多路麦克风数据因此可以获得更多的信息,输入的信息越多我们能提取的信息也就越多,比如多通道中IPD等信息是可以直接帮助性能提升的。
另外从传统上,多通道可以实现beamforming,它的泛化能力和鲁棒性非常强,因此相比于单通道有比较大的优势。2. 多通道的评估指标该怎么计算,因为源文件和混合音频文件有多个通道,分离结果该怎样像单通道一样进行比对呢?
由于多通道大部分还是用于语音识别,所以可以使用语音识别的指标词错误率(Word Error Rate, WER)进行对比;另外还可以从主观听觉上进行比较,使用平均主观意见分(Mean Opinion Score, MOS)。
端到端则相对更容易一点,可以直接计算网络的输出和目标声源之间的指标,包括频域指标和时域指标。整体上来讲,目前对于可以广泛应用到端到端和非端到端的指标仍需研究。3. 目前的语音分离还有哪些不足还需完善才能落地商用,现在有online(实时的)语音分离的研究吗?
目前智能家居、耳机和麦克风等都用到了很多分离降噪的研究。Online主要取决于模型设计,目前,可以在实时性和性能上进行研究。
4. 这些方法可以用来单通道语音降噪吗,如果可以的话实时性上和rnnoise算法相比怎么样,模型大小和速度和效果上如何?
分离模型都可以用来做降噪,模型的大小和速度上需要进行权衡,和rnnoise进行对比的话还需要确定模型的参数大小,单看模型的话是无法分析这件事的。
5. Audio-Visual Speech Separation的研究进展如何?围栏研究热点集中在哪?
我们举一个Audio-Visual研究的例子,我们对于Audio和Visual各有一个处理模块,之后会有一个将Audio和Visual处理结果融合起来的模块,然后再去做一个分离,这是Audio-Visual整体的框架。未来的研究方向主要是前文提到的一些挑战。
6. 基于深度学习的降噪,什么样的代价函数效果最好?
这个问题分两个方面,首先看你的任务目标是什么,如果目标任务是识别的话,si-snr和具体词错误率不一定是线性的,所以我们不能说某个loss在任务上绝对比另一个更好,但如果我们评价指标和训练指标相同,那我们使用评价指标作为loss肯定是最好的。irm对相位没有建模,因此irm在某些情况下不是很好,但是对于Perceptual evaluation of speech quality(PESQ)指标表现较好,可以减少语音的失真。
7. 近期的研究大多偏向时域分离,那时域分离效果为什么优于频域效果呢?以后的发展方向
主要是相位信息的建模、频域oracle mask的性能上限另外是使用的特征上来回优化出一个较好的特征。以后的发展方向是其他各种模型的一些设计,多模态、多通道以及其他前文提到的挑战。
8. Source separation和speaker-diarization在技术实现上有什么联系吗,我在做speaker-diarization任务,能借鉴source separation的什么思路?
传统的speaker-diarization一个假设是说话人之间独立无重叠。但如果我们说话人之间有重叠,那么不可避免的会用到分离,今年开始的做端到端的speaker-diarization的工作,speaker-diarization可以当作是一个粗粒度的source separation,因此很多source separation的框架都可以用到speaker-diarization中。这是一个比较重要的task。
9. 当输入音频存在混响时,对于Si-SNR loss是否需要修正?
是需要修正的,对于输入音频存在混响的情况如何修正目前没有特别好的方法。有很多工作都在关注修改Si-SNR loss使其更好的反应分离的性能,并让其包含有用的信息。
10. 单通道语音分离由于没有IPD/ISD等空间信息,智能做谱分析,那么说话人的声纹特征是否是重要的分离依据?训练集中不同说话人样本太少是否是跨数据集表现答复下降的主要原因?如果把speaker-diarization任务中的一些pre-train模块放到分离网络前辅助encode是否会有提升?
近期的一些模型,会在分离的时候直接加一个说话人识别的损失函数。或者是将说话人信息当作输入提供给网络,但是对于它是否是主要的分离依据,还需要更多的实验进行对比。
对于最后一个问题把diarization中pre-train的模块放到分离网络前辅助encode是一定会有提升的。speaker-diarization和source separation是互帮互助的关系。但是对于end2end模型由于处在较为早期的研究状态,具体的性能提升结果还需要更多研究。
11. 干扰人声,混响和噪声,远场能不能一起处理?不同重叠率的泛化能力怎么提升?
直观讲可以,端到端的话可以将这些进行融合,但是一般这么做的效果并不会很好。这里包括三个问题——分离、降噪、去混响。一般来说端到端的程度越高泛化能力越差因此泛化能力也是一个比较大的问题。不同重叠率的泛化能力提升最简单的是通过不同比例的不同重叠率的数据,也可以加入speaker count(说话人数量检测),某些部分只有一个说话人,可以在这个部分不做分离,做一个动态的处理。
参考文献
[1] Le Roux, Jonathan, et al. "SDR–half-baked or well done?." ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019.
[2] Luo, Yi, and Nima Mesgarani. "TasNet: time-domain audio separation network for real-time, single-channel speech separation." 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018.
[3] Luo, Yi, and Nima Mesgarani. "Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation." IEEE/ACM transactions on audio, speech, and language processing 27.8 (2019): 1256-1266.
[4] Luo, Yi, Zhuo Chen, and Takuya Yoshioka. "Dual-path RNN: efficient long sequence modeling for time-domain single-channel speech separation." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[5] Tzinis, Efthymios, et al. "Two-Step Sound Source Separation: Training On Learned Latent Targets." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[6] Ditter, David, and Timo Gerkmann. "A multi-phase gammatone filterbank for speech separation via tasnet." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[7] Zeghidour, Neil, and David Grangier. "Wavesplit: End-to-end speech separation by speaker clustering." arXiv preprint arXiv:2002.08933 (2020).
[8] Nachmani, Eliya, Yossi Adi, and Lior Wolf. "Voice Separation with an Unknown Number of Multiple Speakers." arXiv preprint arXiv:2003.01531 (2020)
[9] Xu, Chenglin, et al. "SpEx: Multi-Scale Time Domain Speaker Extraction Network." arXiv preprint arXiv:2004.08326 (2020).
[10] Ge, Meng, et al. "SpEx+: A Complete Time Domain Speaker Extraction Network." arXiv preprint arXiv:2005.04686 (2020).
[11] Samuel, David, Aditya Ganeshan, and Jason Naradowsky. "Meta-learning Extractors for Music Source Separation." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[12] Kavalerov, Ilya, et al. "Universal sound separation." 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE, 2019.
[13] Tzinis, Efthymios, et al. "Improving universal sound separation using sound classification." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[14] Wu, Jian, et al. "Time domain audio visual speech separation." arXiv preprint arXiv:1904.03760 (2019).
[15] Stoller, Daniel, Sebastian Ewert, and Simon Dixon. "Wave-U-Net: A multi-scale neural network for end-to-end audio source separation." arXiv preprint arXiv:1806.03185 (2018).
[16] Lluís, Francesc, Jordi Pons, and Xavier Serra. "End-to-end music source separation: is it possible in the waveform domain?." arXiv preprint arXiv:1810.12187 (2018).
[17] Qian, Kaizhi, et al. "Deep learning based speech beamforming." 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018.
[18] Ochiai, Tsubasa, et al. "Beam-TasNet: Time-domain audio separation network meets frequency-domain beamformer." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[19] Li, Bo, et al. "Neural network adaptive beamforming for robust multichannel speech recognition." (2016).
[20] Luo, Yi, et al. "FaSNet: Low-latency adaptive beamforming for multi-microphone audio processing." 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019.
[21] Luo, Yi, et al. "End-to-end microphone permutation and number invariant multi-channel speech separation." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[22] Gu, Rongzhi, et al. "End-to-end multi-channel speech separation." arXiv preprint arXiv:1905.06286 (2019).
[23] Gu, Rongzhi, et al. "Enhancing End-to-End Multi-Channel Speech Separation Via Spatial Feature Learning." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[24] Medennikov, Ivan, et al. "Target-Speaker Voice Activity Detection: a Novel Approach for Multi-Speaker Diarization in a Dinner Party Scenario." arXiv preprint arXiv:2005.07272 (2020)
[25] Horiguchi, Shota, et al. "End-to-End Speaker Diarization for an Unknown Number of Speakers with Encoder-Decoder Based Attractors." arXiv preprint arXiv:2005.09921 (2020).
[26] Takahashi, Naoya, et al. "Recursive speech separation for unknown number of speakers." arXiv preprint arXiv:1904.03065 (2019).
[27] Luo, Yi, and Nima Mesgarani. "Separating varying numbers of sources with auxiliary autoencoding loss." arXiv preprint arXiv:2003.12326 (2020).
[28] Chen, Zhuo, et al. "Continuous speech separation: Dataset and analysis." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[29] von Neumann, Thilo, et al. "End-to-end training of time domain audio separation and recognition." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[30] von Neumann, Thilo, et al. "Multi-talker ASR for an unknown number of sources: Joint training of source counting, separation and ASR." arXiv preprint arXiv:2006.02786 (2020).
[31] Maciejewski, Matthew, et al. "WHAMR!: Noisy and reverberant single-channel speech separation." ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
本文原创作者:付艺辉,姚卓远
原文地址:https://zhuanlan.zhihu.com/p/183846790 |
|

 /3
/3 

 浙公网安备33010802005999号
浙公网安备33010802005999号 





 2026庆【网站十三周
2026庆【网站十三周 2025庆【网站十二周
2025庆【网站十二周 2024庆中秋、迎国庆
2024庆中秋、迎国庆 2024庆【网站十一周
2024庆【网站十一周 2023庆【网站十周年
2023庆【网站十周年 2022庆【网站九周年
2022庆【网站九周年

 雷达卡
雷达卡 发表于 2024-10-13 12:52
发表于 2024-10-13 12:52
 提升卡
提升卡


